







统计每个产品的评论,将数据中键相同的分为一组,将两个不同的RDD 进行分组合并等)。
1. 创建Pair RDD
在Python 中使用第一个单词作为键创建出一个pair RDD
pairs = lines.map(lambda x: (x.split(" ")[0], x))

pari RDD 支持 RDD所支持的函数。例如,我们可以拿前一节中的pair RDD, 筛选掉长度超过20个字符的行。
result = pairs.filter(lambda keyValue: len(keyValue[1]) < 20)2. 聚合操作
(1)在Python 中使用reduceByKey() 和mapValues() 计算每个键对应的平均值
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1])) rdd = sc.textFile("s3://...")
words = rdd.flatMap(lambda x: x.split(" "))
result = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)(3) 在Python 中使用combineByKey() 求每个键对应的平均值
sumCount = nums.combineByKey((lambda x: (x,1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()(4) 并行度调优
在执行聚合或分组操作时,可以要求Spark 使用给定的分区数。Spark 始终尝试根据集群的大小推断出一个有意义的默认值,但是有时候你可能要对并行度进行调优来获取更好的性能表现。
在Python 中自定义reduceByKey() 的并行度
data = [("a", 3), ("b", 4), ("a", 1)]
sc.parallelize(data).reduceByKey(lambda x, y: x + y) # 默认并行度
sc.parallelize(data).reduceByKey(lambda x, y: x + y, 10) # 自定义并行度3 数据分组
如果数据已经以预期的方式提取了键,groupByKey() 就会使用RDD 中的键来对数据进行分组。对于一个由类型K 的键和类型V 的值组成的RDD,所得到的结果RDD 类型会是[K, Iterable[V]]。
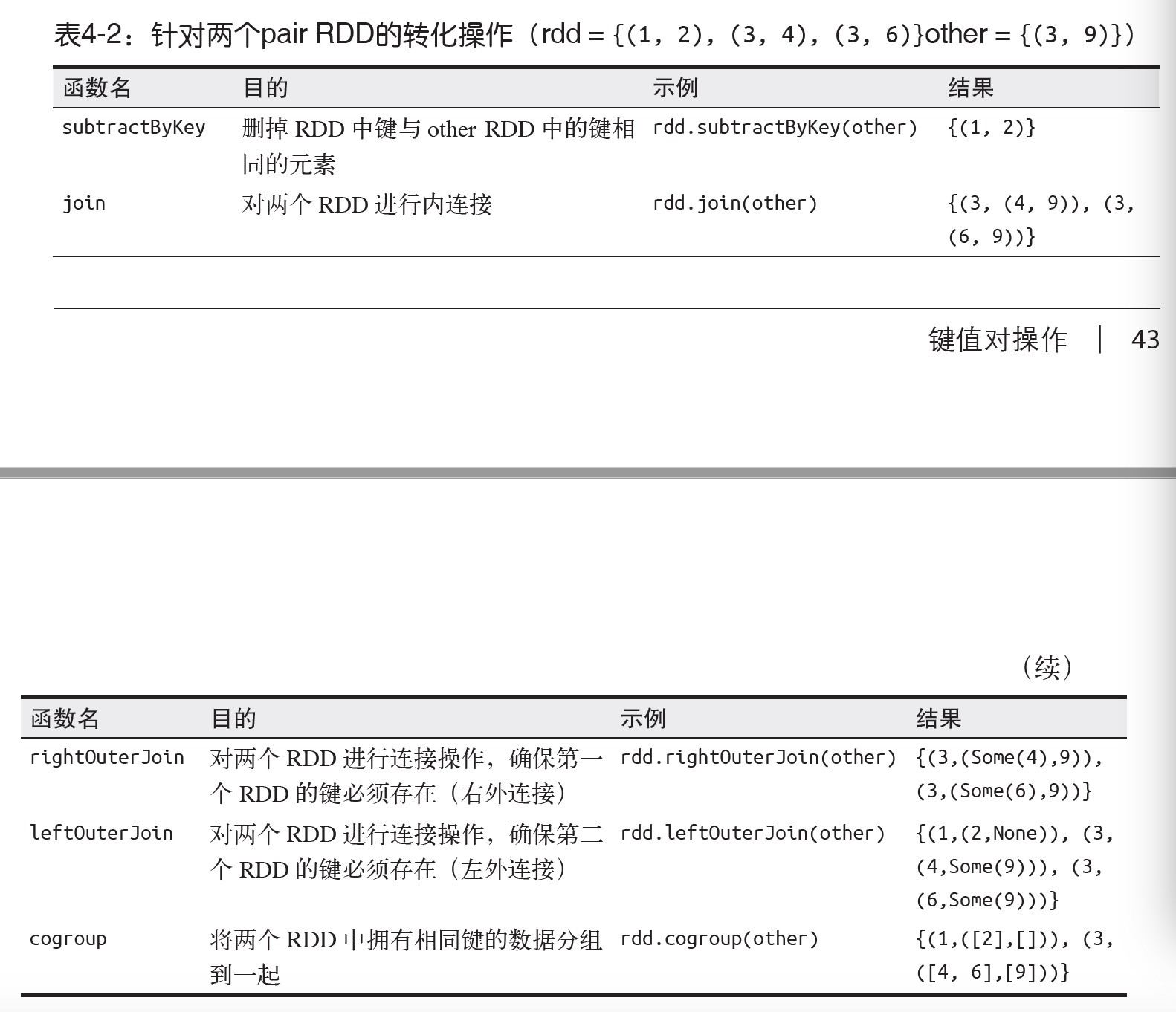
除了对单个RDD 的数据进行分组,还可以使用一个叫作cogroup() 的函数对多个共享同一个键的RDD 进行分组。对两个键的类型均为K 而值的类型分别为V 和W 的RDD 进行cogroup() 时,得到的结果RDD 类型为[(K, (Iterable[V], Iterable[W]))]。
4 数据分区
4.1 分区操作
Spark 程序可以通过控制, RDD 分区方式来减少通信开销。
rdd.partitionBy(100).persist()
4.2 从分区中获益的操作
数据分区中获益的有cogroup()、groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey() 以及lookup()。对于join()这类二元操作,预先进行数据分区会让其中至少一个RDD不发生数据混洗操作。如果两个RDD 使用同样的分区方式,并且它们还缓存在同样的机器上(比如一个RDD 是通过mapValues() 从另一个RDD 中创建出来的,这两个RDD 就会拥有相同的键和分区方式),或者其中一个RDD 还没有被计算出来,那么跨节点的数据混洗就不会发生了。
4.3 自动分区的操作
这里列出了所有会为生成的结果RDD 设好分区方式的操作:cogroup()、groupWith()、join()、lef tOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey()、partitionBy()、sort()、mapValues()(如果父RDD 有分区方式的话)、flatMapValues()(如果父RDD 有分区方式的话),以及filter()(如果父RDD 有分区方式的话)。其他所有的操作生成的结果都不会存在特定的分区方式。
4.4 自定义分区
在Python 中,不需要扩展Partitioner 类,而是把一个特定的哈希函数作为一个额外的参数传给RDD.partitionBy() 函数,如例4-27 所示。
import urlparse
def hash_domain(url):
return hash(urlparse.urlparse(url).netloc)
rdd.partitionBy(20, hash_domain) # 创建20个分区















 2731
2731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









