






1.Scrapy选择器介绍
当我们取得了网页的response之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,python从网页中提取数据的包很多,常用的有下面的几个:
- a.BeautifulSoup
- 它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但是速度上有所欠缺。
- b.lxml
-
是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
你可以在scrapy中使用任意你熟悉的网页数据提取工具,但是,scrapy本身也为我们提供了一套提取数据的机制,我们称之为选择器(seletors),他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
-
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。下面我们来了解scrapy选择器。
-
2.使用Scrapy选择器
-
scrapy中调用选择器的方法非常的简单,下面我们从实例中进行学习。
-
以豆瓣电影 Top 250页面信息作为例子,演示使用选择器抓取数据,下图是Top 250页面的html信息,我们下面就是抓取电影名,演员等信息,电影评分,评价人数。如下图,是Top 250页面的html信息
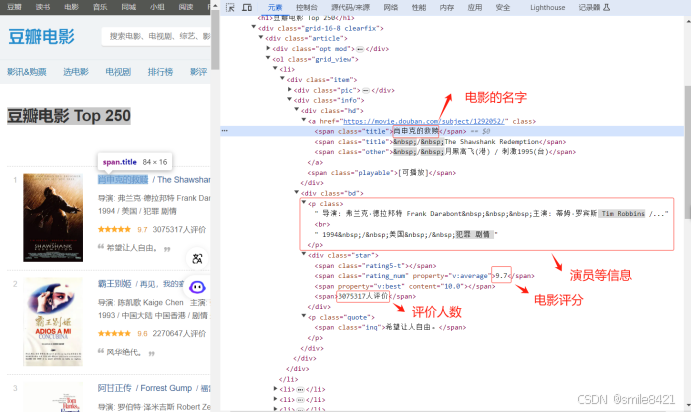
-
2.1 XPath表达式
-
XPath是一门在xml文档中查找信息的语言,它可用来在xml文档中对元素和属性进行遍历。XPath表达式中符号的含义见下表
-
表达式
描述
/
从根节点选取
//
选择所有匹配的节点,而不考虑它们的位置
.
选取当前节点
..
选取当前节点的父节点
@
选取属性
*
匹配任何元素节点
@*
匹配任何属性节点
Node()
匹配任何类型的节点
-

-
2.2 使用Scrapy选择器的xpath()方法解析豆瓣电影网页中的内容
-
xpath路径的使用可以分为下面的三步:
-
1)页面分析
-
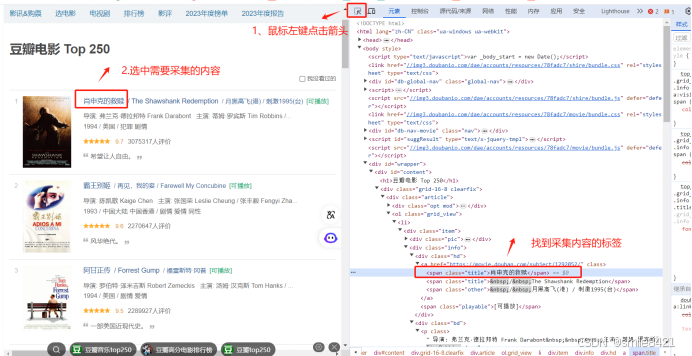 2)复制xpath
2)复制xpath -
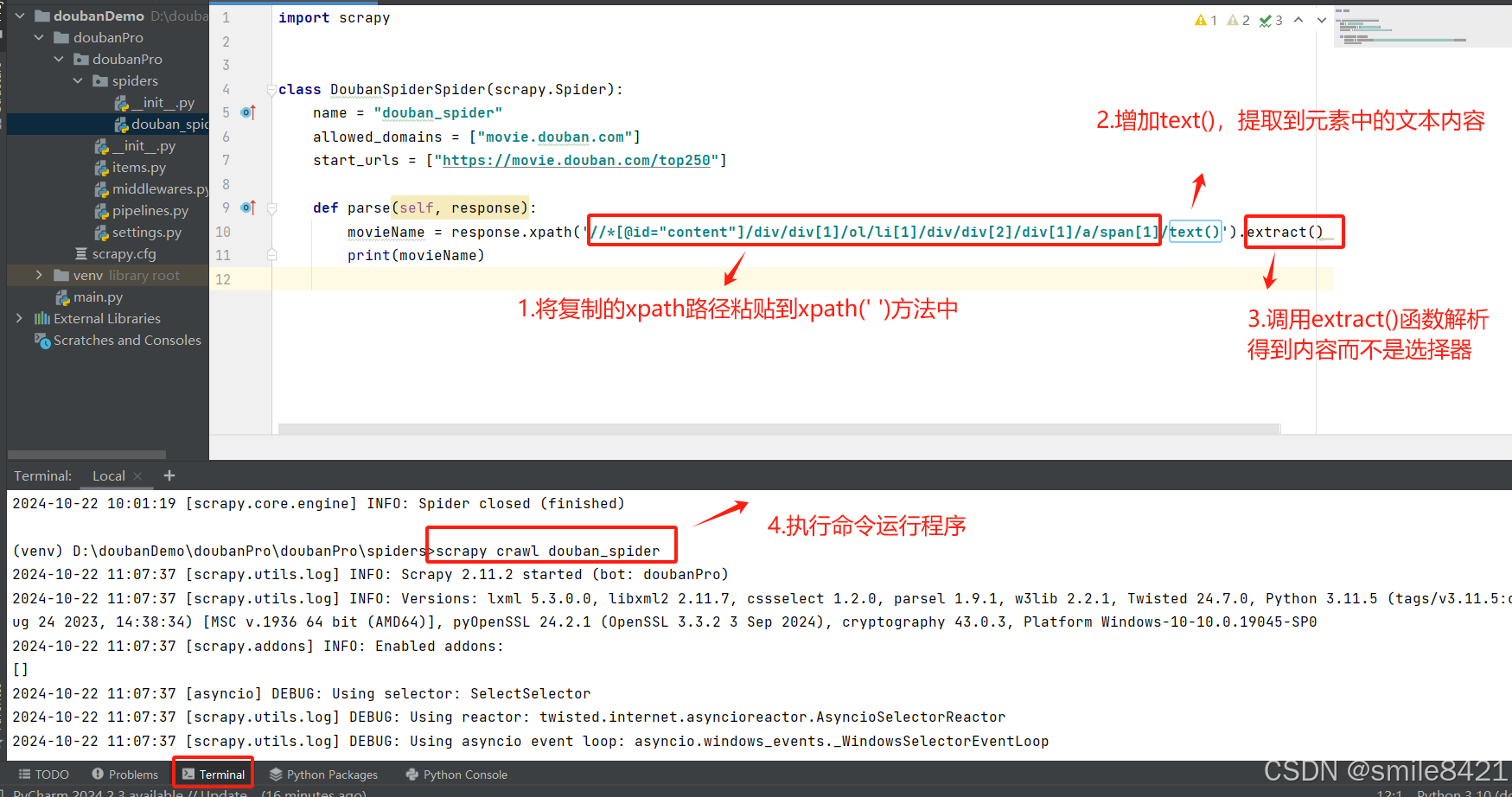
 3) 粘贴到代码中
3) 粘贴到代码中 -
-
打印如下信息,则表示成功获取到1部电影的名称
-
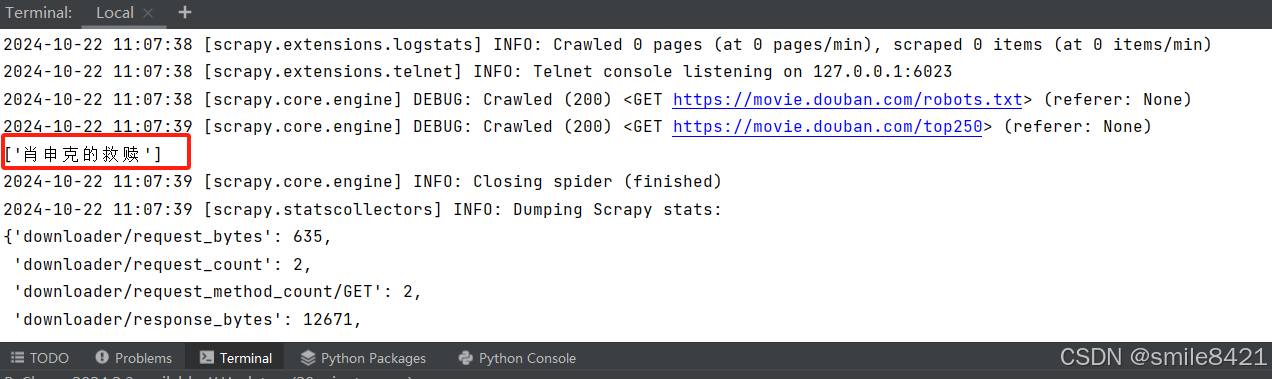
-
如果不想打印其他日志信息,则可执行命令:scrapy crawl douban_spider --nolog
-

-
如果想获取页面其他电影名称,则需要修改xpath路径
-
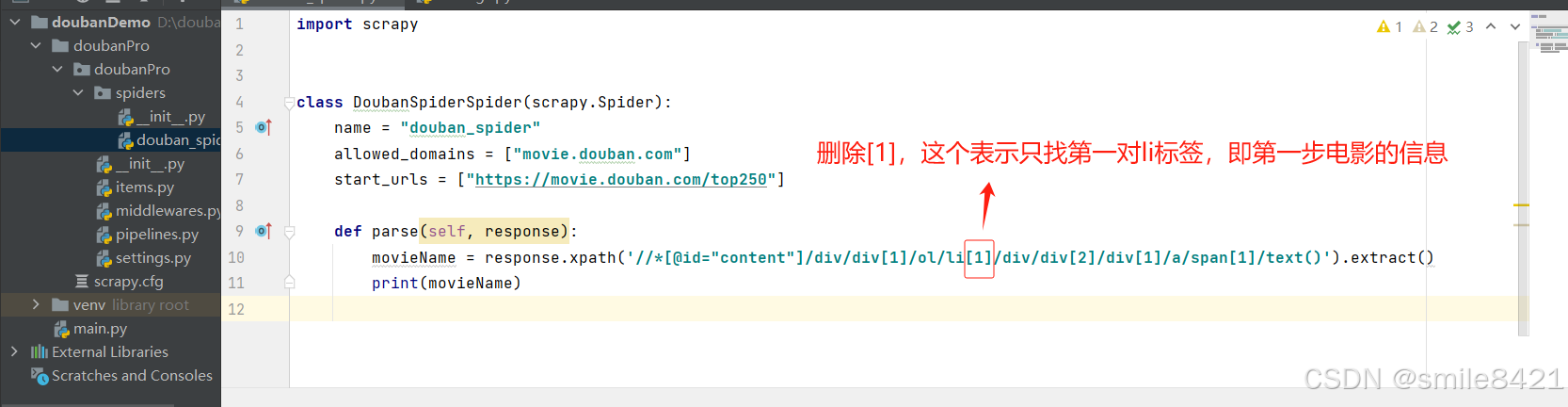
-

-
2.3 css表达式
-

-
2.4 使用Scrapy选择器的css()方法解析豆瓣电影网页中的内容
-
选择器的使用可以分为下面的三步:
-
1)页面分析
-
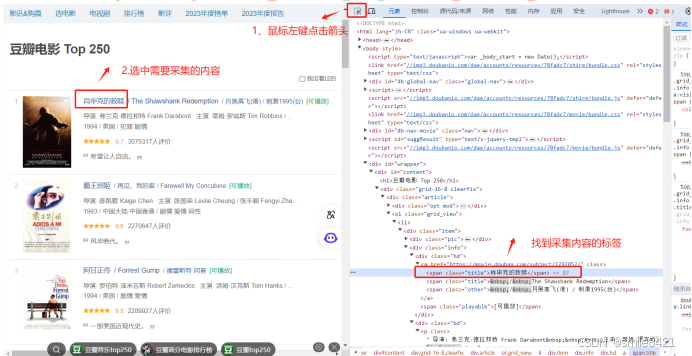
-
2)复制选择器
-
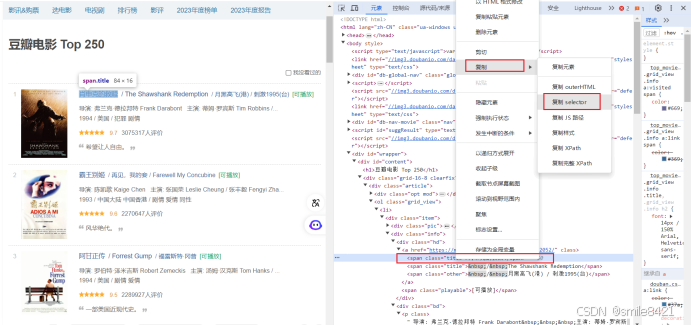 3) 粘贴到代码中
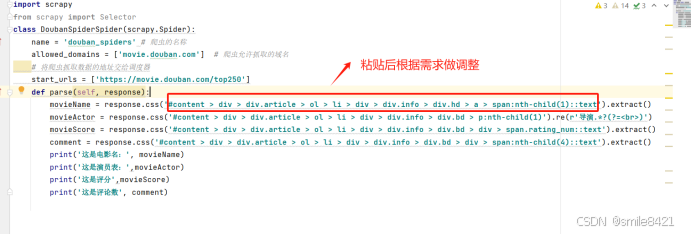
3) 粘贴到代码中 -
修改方法与xpath类似,将li的[1]去掉,增加::text获取标签中的文本,增加extract()方法提取真实的原文数据。
-
 注意:.xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表,就是说,你依然可以使用里面的元素进行向下提取,因为它还是一个选择器,为了提取真实的原文数据,我们需要调用 .extract()。如果想要提取到第一个匹配到的元素, 可以调用.extract_first()。
注意:.xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表,就是说,你依然可以使用里面的元素进行向下提取,因为它还是一个选择器,为了提取真实的原文数据,我们需要调用 .extract()。如果想要提取到第一个匹配到的元素, 可以调用.extract_first()。
-

















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









