







业务场景:通常情况下,在MR操作中到达Reduce中的key值都是按照指定的规则进行排序,在单一key的情况下一切都进行的很自然,直到我们要求数据不再单纯的按key进行排序,以如下数据举例:
Key -> value:
100 -> 2017-02-27 19:21:31,45,67,68
50 -> 2017-02-27 19:22:04,89,90,56
90 -> 2017-02-27 19:22:27,90,89,99
50 -> 2017-02-27 19:20:42,88,45,89
现要求对结果数据进行分组,key值相同的为一组且组内有序
处理方式:
原理:借助MR排序的优势,提供可扩展的二次排序操作
流程
Map ->(复合主键,value) à自定义分区函数àReduce-
实例:
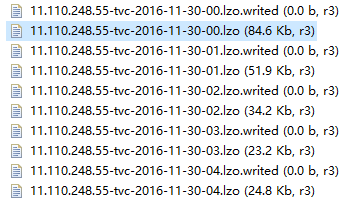
数据目录如下,其中.loz结尾的为真正的数据文件,以其文件名为前缀.writed为后缀的问文件标识当前.loz文件写状态,只有处于.writed状态的loz文件为有效可读文件
数据格式如下:VERSION=1.0,PASSTIME=2016-11-30 00:00:39 000,CARSTATE=1,CARPLATE=无,PLATETYPE=99,SPEED=0,PLATECOLOR=4,LOCATIONID=-1,DEVICEID=-1,DRIVEWAY=2,DRIVEDIR=4,CAPTUREDIR=1,CARCOLOR=10,CARBRAND=99,CARBRANDZW=其它,TGSID=1125,PLATECOORD=0,0,0,0,CABCOORD=0,0,0,0,IMGID1=http://11.110.248.59:9099/image/dhdfs/2016-11-30/archivefile-2016-11-30-000040-00677B0200000001:5750848/308059.jpg,IMGID2=,IMGID3=,
数据量>=2G
要求如下:统计全部数据中每辆车按时间序列经过的卡口信息(卡口字段为元数据中TGSID列) 数据输出格式为,文件名=号牌+辅助字段,内容=过车时间(PASSTIME)-卡口编号(TGSID),…
编程实现:
1. CarOrder.class,自定义组合键,借助MR的KEY排序操作实现Map内按key-time排序操作,要求实现两序列化接口
classCarOrder implements Writable, WritableComparable<CarOrder> {
//号牌
private Text carPlate;
//过车时间
private Text day;
public Text getDay() {
return day;
}
public void setDay(Text day) {
this.day = day;
}
public CarOrder() {
carPlate = new Text();
day = new Text();
}
public CarOrder(Text carPlate, Text day){
super();
this.carPlate = carPlate;
this.day = day;
}
public int compareTo(CarOrder co){
int compareValue = this.carPlate.compareTo(co.carPlate);
// 相等
if (compareValue == 0) {
compareValue = this.day.compareTo(co.day);
}
return compareValue;
}
public void write(DataOutput out)throws IOException {
this.carPlate.write(out);
this.day.write(out);
}
public void readFields(DataInputin) throws IOException {
this.carPlate.readFields(in);
this.day.readFields(in);
}
public Text getCarPlate() {
return carPlate;
}
public void setCarPlate(TextcarPlate) {
this.carPlate = carPlate;
}
@Override
public String toString() {
return "CarOrder[carPlate=" + carPlate + ", day=" + day + "]";
}
}2. CarComparator.java,定义分组比较器,决定在MR SHUFFLE过程中对数据分组的依据,要求号牌相同时间不同的为同一组
classCarComparator extends WritableComparator {
public CarComparator() {
// 指定Key值
super(CarOrder.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a,WritableComparable b) {
CarOrder car1 = (CarOrder) a;
CarOrder car2 = (CarOrder) b;
return car1.getCarPlate().compareTo(car2.getCarPlate());
}
}3. CarPartitioner.class,自定义分区函数,Mapper操作中间结果分区依据,将数据均匀划分.
classCarPartitioner extends Partitioner<CarOrder, Text> {
@Override
public int getPartition(CarOrder key, Textvalue, int numPartitions) {
return Math.abs(key.getCarPlate().hashCode())% numPartitions;
}
}4. CarMap.java Mapper函数,此处做简单的数据解析工作,文件过滤在驱动器节点完成,Mapper操作封装复合键CarOrder输出(CarOrder,”时间-卡口编号”)
classCarMap extends Mapper<LongWritable, Text, CarOrder, Text> {
@Override
protected void map(LongWritable key, Textvalue, Context context) throws IOException, InterruptedException {
String temp = value.toString();
if (temp.length() > 13) {
temp = temp.substring(12);
String[] items =temp.split(",");
if (items.length > 10) {
// CarPlate As Key
if(!items[2].endsWith("无牌")){
try {
CarOrderco = new CarOrder(new Text(items[2].substring(9)), newText(items[0].substring(9)));
//time + tgsid
context.write(co,new Text(items[0].substring(9)+"-"+items[14].substring(6)));
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
}
}5. CarCombine.java ,考虑到Map端数据可能会偏大的情况,使用MR的Combine特性对Map的结果预先进行处理,减少Mapper端输出,降低IO操作提高程序性能.
classCarCombine extends Reducer<CarOrder, Text, CarOrder, Text> {
@Override
protected void reduce(CarOrder co,Iterable<Text> values, Reducer<CarOrder, Text, CarOrder,Text>.Context context)
throws IOException,InterruptedException {
StringBuffer buf = newStringBuffer();
String before = null;
String current = null;
for (Text text : values) {
current = text.toString();
if (current.equals(before)){
continue;
}
buf.append(current);
buf.append(',');
before = current;
}
if(buf.length()==0){
return ;
}
context.write(co, newText(buf.toString()));
}
}6. OutputByCarPlate.java ,Reduce操作,由于要求结果按好配进行分类,经测试发现,在MR中使用大量的文件输出并不是好事,举例来说如果有50万车辆则可能需要50万个文件来存储,性能开销极大容易造成MR假死,甚至内存溢出! 未避免此问题,此处仍然采用多文件输出只不过降级为:按所有数据以天为文件划分依据进行存储,单个车辆存储一行。
classOutputByCarPlate extends Reducer<CarOrder, Text, NullWritable, Text> {
MultipleOutputs<NullWritable, Text> mo;
@Override
protected void setup(Reducer<CarOrder, Text,NullWritable, Text>.Context context)
throws IOException,InterruptedException {
mo = newMultipleOutputs<NullWritable, Text>(context);
}
@Override
protected void reduce(CarOrder key,Iterable<Text> values, Context context)
throws IOException,InterruptedException {
StringBuffer buf = newStringBuffer();
for (Text text : values) {
buf.append(text.toString());
buf.append(',');
}
String value = buf.toString();
String[] flows =value.split(",");
if (flows.length >= 3) {
String prefix =key.getDay().toString().replaceAll("[-\\s:]", "");
mo.write(NullWritable.get(),new Text(value.substring(0, value.length() - 1)), prefix.substring(0, 8));
}
}
@Override
protected void cleanup(Reducer<CarOrder,Text, NullWritable, Text>.Context context)
throws IOException,InterruptedException {
mo.close();
}
}7. Main.java ,驱动器节点,组织MR作业,预处理文件,由于小文件数量较多此处采用CombineTextInputFormat输入文本文件(因源数据使用LOZ压缩算法,经测试此处需要明确标识输入块的大小否则文件合并无效,即: CombineTextInputFormat.setMaxInputSplitSize(job, 67108864);),MR提供的TextInputFormat.setInputPathFilter有局限,只能过滤已经被识别的子目录文件,不支持动态修改,此处使用在Mapper之外过滤以CombineTextInputFormat.addInputPath(job, temp);方式追加输入,以实现按特定要求去输入文件.
public class Main{
public static void main(String[] args) throwsException {
Configuration conf = newConfiguration();
conf.set("mapreduce.reduce.memory.mb","4096");
Job job = Job.getInstance(conf,"TRACK_BY_TIME_TGSID");
// 小文件合并
job.setInputFormatClass(CombineTextInputFormat.class);
job.setJarByClass(cn.com.zjf.MR_04.Car1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(CarOrder.class);
job.setMapOutputValueClass(Text.class);
job.setMapperClass(CarMap.class);
job.setReducerClass(OutputByCarPlate.class);
// 组合键的排序规则
//job.setSortComparatorClass(ResultComparator.class);
// 自定义分区
job.setPartitionerClass(CarPartitioner.class);
// 自定义比较器-->二次排序的依据
job.setGroupingComparatorClass(CarComparator.class);
FileSystem fs = FileSystem.get(conf);
Path input = new Path(args[0]);
/**
* 预处理文件 .只读取写完毕的文件 .writed结尾 .只读取文件大小大于0的文件
*/
{
FileStatus childs[] =fs.globStatus(input, new PathFilter() {
public booleanaccept(Path path) {
if(path.toString().endsWith(".writed")) {
returntrue;
}
returnfalse;
}
});
Path temp = null;
for (FileStatus file :childs) {
temp = newPath(file.getPath().toString().replaceAll(".writed", ""));
if (fs.listStatus(temp)[0].getLen()> 0) {
CombineTextInputFormat.addInputPath(job,temp);
}
}
}
CombineTextInputFormat.setMaxInputSplitSize(job,67108864);
Path output = new Path(args[1]);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job,output);
if (!job.waitForCompletion(true))
return;
}
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









