







提问:现有一服务用于清理Elasticsearch中索引的文本数据,在这之前需要保证将记录中关联的几张图片也删除掉才能将该条记录完全删除,由于删除图片采用RPC部署的多个删除服务来完成,网络故障自然无法避免,同时对于Elasticsearch数据抓取采用Scroll API以减轻对Elasticsearch的影响,为便于观察数据删除的进度,服务中提供了守护进程用于统计每批次抓取数据的删除情况(图片,文本,进度等),系统部署运行几个月后现在要求能了解该服务的运行状态,及每天清理数据的情况天、月的汇总情况
方案:
因之前使用过Elasticsearch,其强大的数据索引能力和数据分析能力,以及丰富的插件(支持SQL),可以使用Logstash将处理后的数据直接索引到Elasticsearch 可避免大量的开发工作,无论如何Logstash可以做到这一点也很适合做这件事情,当然不止于此。
Logstash简介:

如上图所示,Logstash使用配置的方式来收集各种各样的数据源(日志文件\流数据\等等),允许在数据传输过程中对数据进行解析、清理、转换、聚合最后到存储,支持多样的输出源。
Logstash架构:
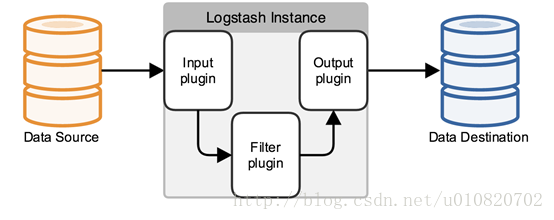
如上图所示,Logstash从数据收集处理到输出抽象了三层,Input (对应各种各样的数据源),Filter(数据匹配、清理、转换、聚合等操作)以及Output(对应各种各样的输出源),Logstash 原生提供了很多Input、Filter、Output的实现让通过简单的配置完成数据流的接入、处理、输出操作在很短的时间完成,当然可以开发自己的插件来满足业务要求。
Logstash 安装:
下载安装包,下载基于jdk1.7的最后一个发布版本https://download.elastic.co/logstash/logstash/logstash-2.4.1.tar.gz
解压缩到安装目录,JDK1.7须自行安装。tar -zxf logstash-2.4.1.tar.gz
在logstash-2.4.1目录下执行测试:
bin/logstash -e 'input { stdin { } } output { stdout {} }'

上述脚本启动一个logstash 实例,从标准输入接收数据,不经过任何处理在标准输出打印,可以看见logstash 默认额外的补充了时间戳信息和主机信息。
实例:
使用Logstash 分析Logback打印到磁盘的日志,日志格式如下,需要将实时的统计信息汇总到Elasticsearch中便于做整体的查询、分析操作.

第一步-定义输入,Logstash 中使用配置文件来定义流处理操作,包括输入、过滤、输出操作。
在logstash-2.4.1目录下创建config目录,在config目录中创建配置文件
mkdir config;vi config/first-pipeline.conf; 配置文件内容如下,下面将做逐一解释:
input {
file {
path => "/app/tvc-carclean/logs/app.log"
start_position => beginning
ignore_older => 0
}
}
filter {
#事件过滤删除
if "CarCleanTask.java:139" not in [message]{
drop { }
}
#事件解析
grok{
match => {
"message" => "%{TIMESTAMP_ISO8601:exetime} %{LOGLEVEL:loglevel} \[pool%{NUMBER:poolnum}-thread%{NUMBER:threadnum}\] %{JAVACLASS:classpath} \[%{JAVACLASS:classname}:%{NUMBER:line}\] Metric \[total=%{NUMBER:total}, imgfail=%{NUMBER:imgfail}, imgsuccess=%{NUMBER:imgsuccess}, txtsuccess=%{NUMBER:txtsucess}, txtfail=%{NUMBER:txtfail}, progress=%{NUMBER:process}\]"
}
remove_field => [ "message", "path"]
}
#日期格式转换
ruby {
code => "event['exetime']=Time.parse(event['exetime']).to_f*1000"
}
#数据格式转换
mutate{
convert => { "exetime" => "integer" }
convert => { "line" => "integer" }
convert => { "total" => "integer" }
convert => { "imgfail" => "integer" }
convert => { "imgsuccess" => "integer" }
convert => { "txtsucess" => "integer" }
convert => { "txtfail" => "integer" }
convert => { "process" => "integer" }
remove_field => ["@version" ]
}
}
output {
elasticsearch {
hosts =>["10.150.27.223:9200","10.150.27.224:9200","10.150.27.225:9200"]
}
}配置文件结构:
#开始的为注释行,input{}中定义Input,filter{}中定义filter,output{}中定义output,每个模块中可以定义多个对应的组件.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}配置Input
2.4.1版本内置了40+个内置的Input,https://www.elastic.co/guide/en/logstash/2.4/input-plugins.html 具体配置方式可查看文档说明,该例只用file输入源,监控文件/app/tvc-carclean/logs/app.log中实时写入的日志流作为logstash的输入由path属性指定,start_position 指定从文件的首行开始取数据.
#定义输入操作
input {
file {
path => "/app/tvc-carclean/logs/app.log"
start_position => beginning
ignore_older => 0
}
}配置filter
2.4.1版本内置了40+个内置的Filter提供对数据的分析,删除,转换等操作。
以下配置用来删除非统计类的日志,logstash中提供了若干支持的逻辑判断词, 对满足条件的记录使用drop插件删除,其中全局属性message标识当前的消息记录。
#只保留含有关键字的日志记录
if "CarCleanTask.java:139" not in [message]{
drop { }
}以下配置使用grok插件来适配日志消息并绑定到指定的字段中,并移除原始消息("message"),文件路径("path")grok 使用如下格式来匹配字段%{SYNTAX:SEMANTIC} 其中SYNTAX为grok 内定义的正则或者自定义的正则SEMANTIC为将匹配的内容绑定到该变量。
匹配关系如下:
2018-03-11 11:44:00,006 INFO [pool-6-thread-1] c.e.t.t.CarCleanTask [CarCleanTask.java:139] Metric [total=0, imgfail=0, imgsuccess=0, txtsuccess=0, txtfail=0, progress=0]

#事件解析
grok{
match => {
"message" => "%{TIMESTAMP_ISO8601:exetime} %{LOGLEVEL:loglevel} \[pool%{NUMBER:poolnum}-thread%{NUMBER:threadnum}\] %{JAVACLASS:classpath} \[%{JAVACLASS:classname}:%{NUMBER:line}\] Metric \[total=%{NUMBER:total}, imgfail=%{NUMBER:imgfail}, imgsuccess=%{NUMBER:imgsuccess}, txtsuccess=%{NUMBER:txtsucess}, txtfail=%{NUMBER:txtfail}, progress=%{NUMBER:process}\]"
}
remove_field => [ "message", "path"]
}Logstash提供了在线的grok插件调试工具用来在线检查grok 正则表达式的合法性,大大降低了调试难度,在网页中调试好直接放在生产环境使用即可
http://grokdebug.herokuapp.com/
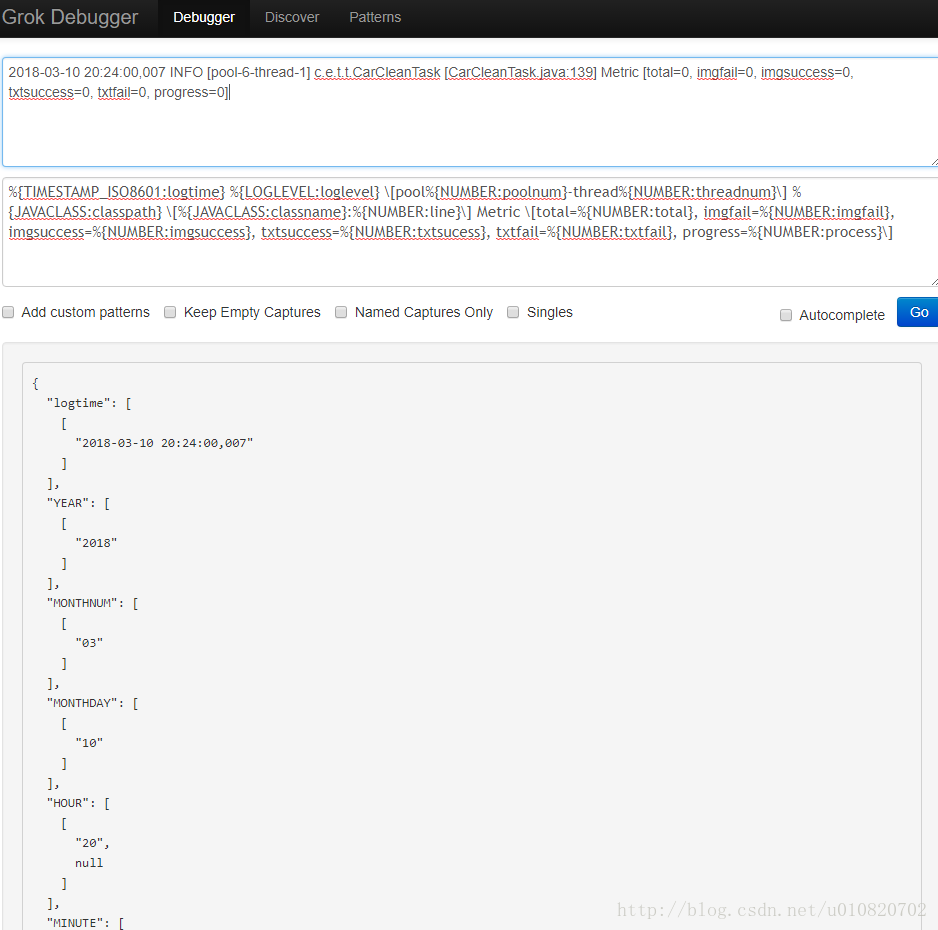
TIMESTAMP_ISO8601模式识别的日期为2018-03-11 11:44:00,006 我们需要存储为时间戳格式,下面配置使用ruby filter完成日志转换操作,ruby 域内使用event 集合来访问个更新原始事件值。
#日期格式转换
ruby {
code => "event['exetime']=Time.parse(event['exetime']).to_f*1000"
}下面配置使用mutate filter将浮点数转为整数并删除元数据中的["@version"] 字段。
#数据格式转换
mutate{
convert => { "exetime" => "integer" }
convert => { "line" => "integer" }
convert => { "total" => "integer" }
convert => { "imgfail" => "integer" }
convert => { "imgsuccess" => "integer" }
convert => { "txtsucess" => "integer" }
convert => { "txtfail" => "integer" }
convert => { "process" => "integer" }
remove_field => ["@version" ]
}最后配置处理后的数据字段索引到Elasticsearch索引中,默认索引一天一个,type为logs.
output {
elasticsearch {
hosts =>["10.150.27.223:9200","10.150.27.224:9200","10.150.27.225:9200"]
}
}以后台运行方式启动logstash
nohup bin/logstash -f config/first-pipeline.conf &
查看Elasticsearch中索引的统计信息,可使用Elasticsearch聚合或其它插件进行数据统计分析,很多没有用的字段可以在logstash配置中进行删除.

最后简单的统计一下截至目前总共清理了多少条过车记录.
POST请求查询
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"sumtextsuccess": {
"sum": {
"field": "txtsucess"
}
}
}
}返回结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 11,
"max_score": 0,
"hits": [ ]
},
"aggregations": {
"sumtextsuccess": {
"value": 0
}
}
}














 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









