







接着上一篇cms + cdh安装博客: http://blog.csdn.net/u010839779/article/details/78858936 cms cdh
cms cdh 升级成HA的配置详解:
NameNode的HA:
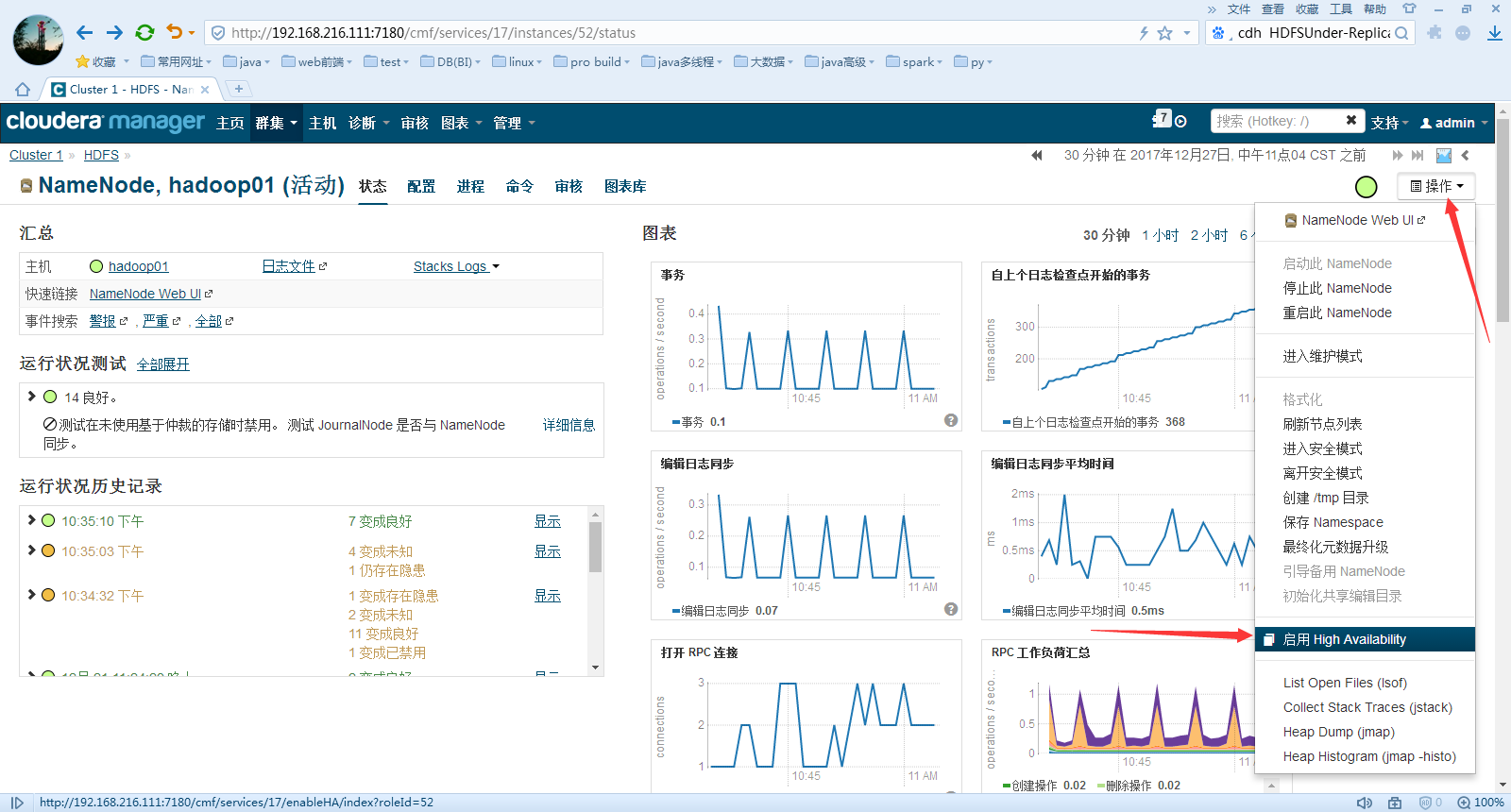
找到namenode的服务-----> 操作----->启用High Avaliablity
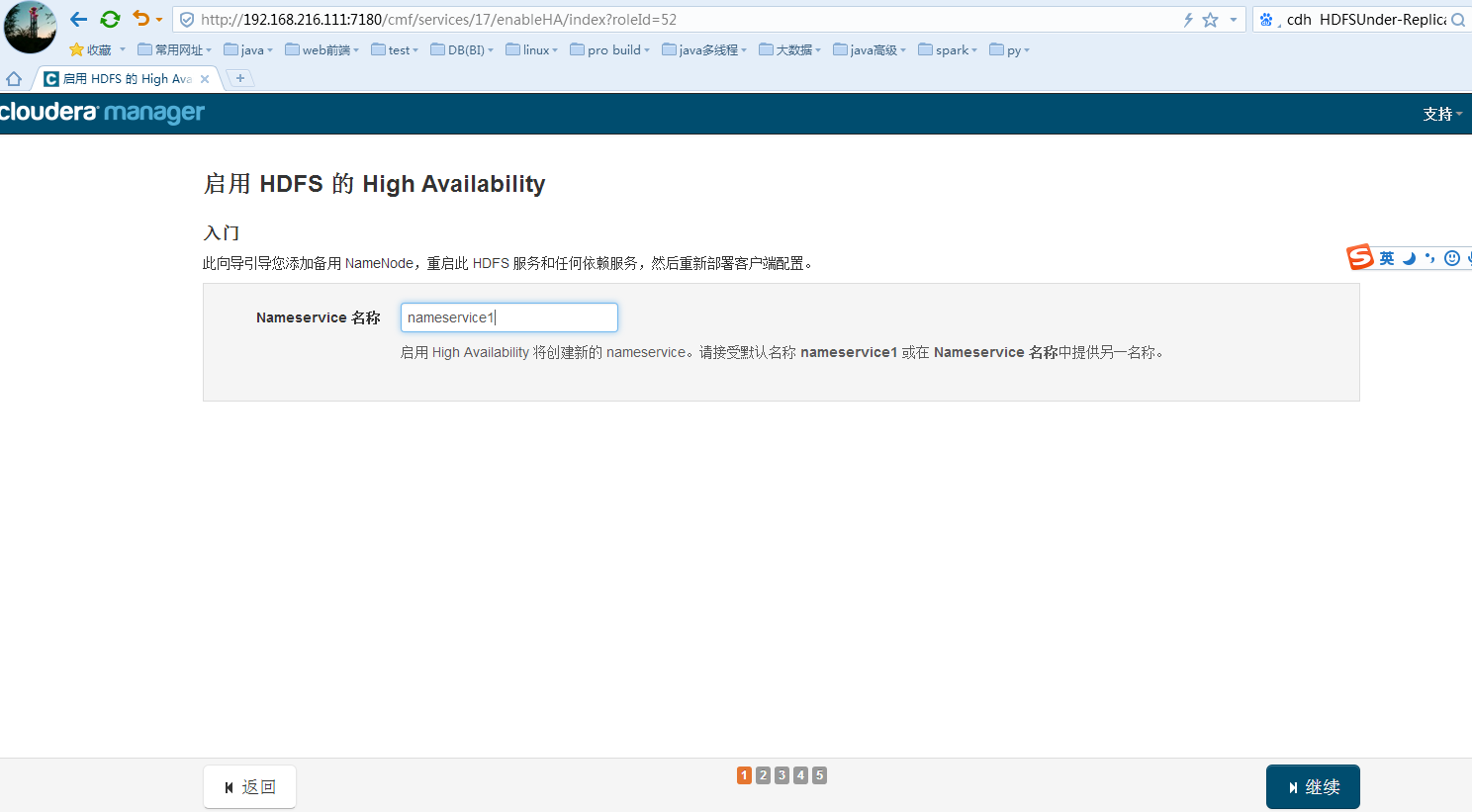
继续即可配置
高可用的命名空间名字随便命名即可,建议使用默认值nameservice1。
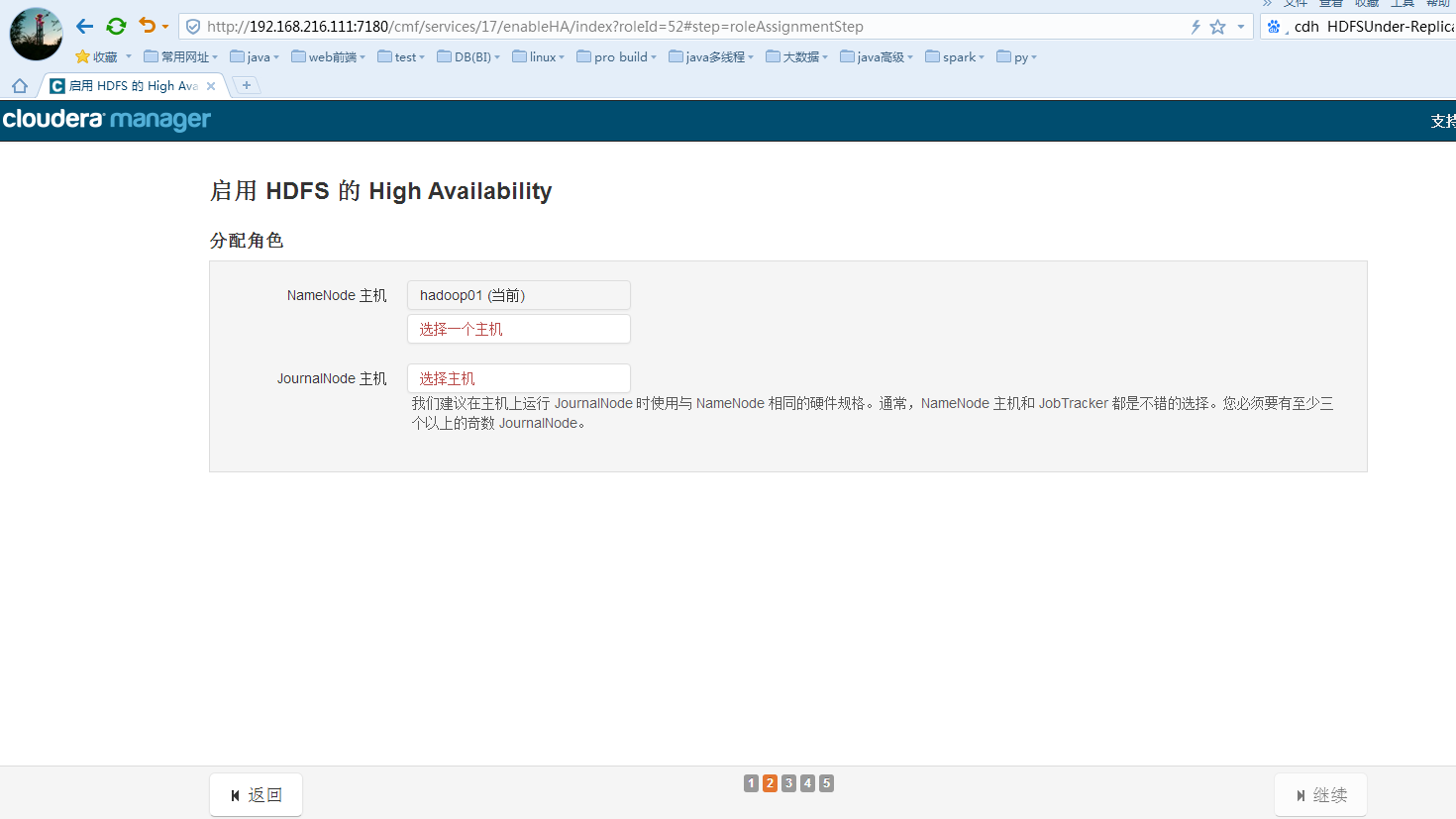
点击选择一个namenode的主机:
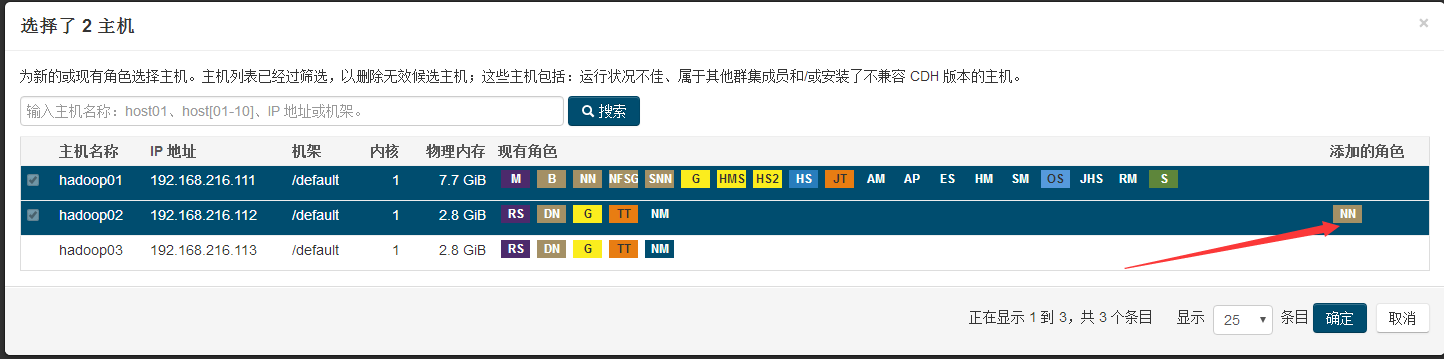
选择journalNode的主机,建议至少3个且为基数个:
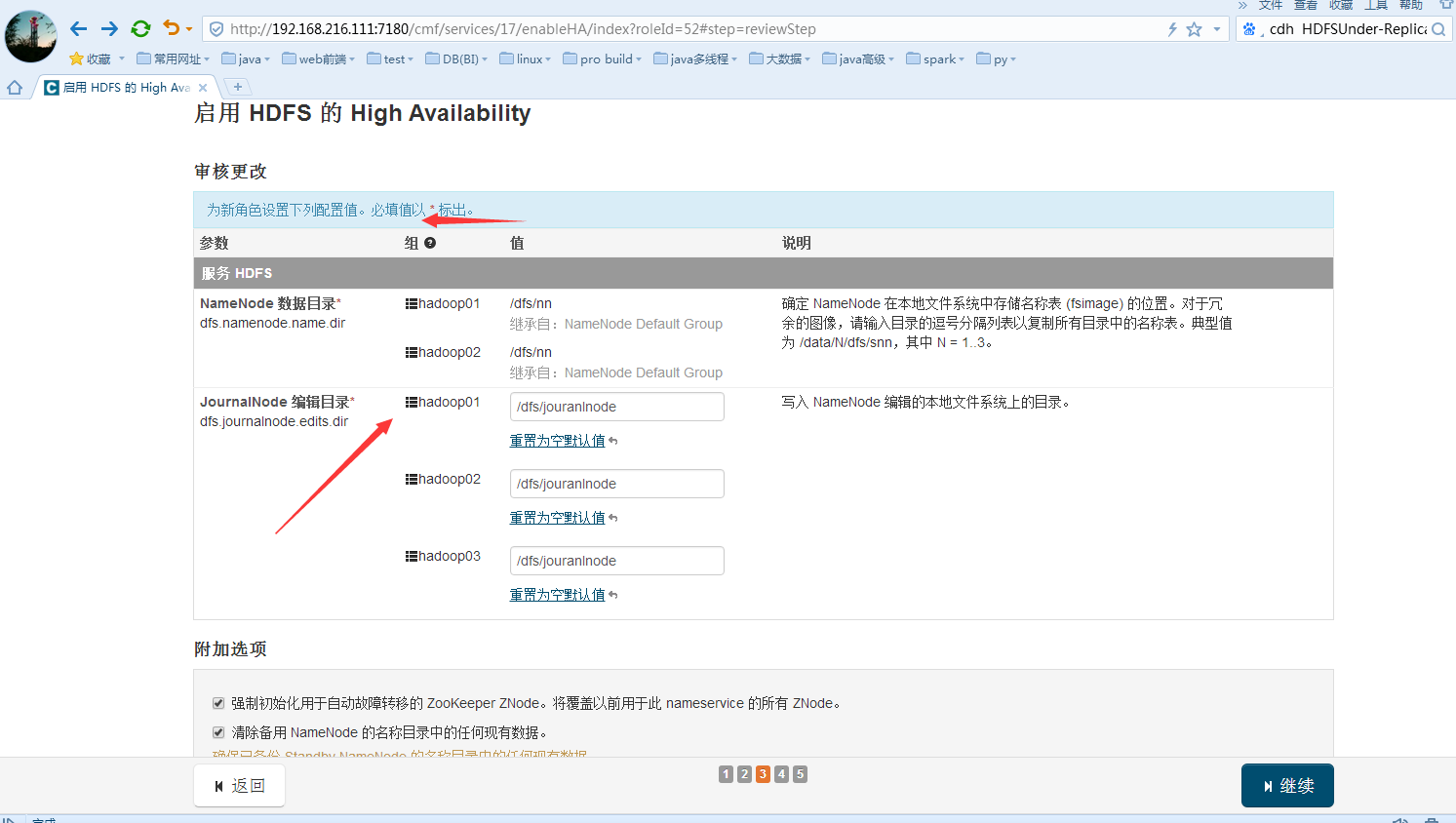
继续下一步的配置,建议把journalnode数据共享目录的配置给配置上,默认为空:
继续进行启用 HDFS 的 High Availability:
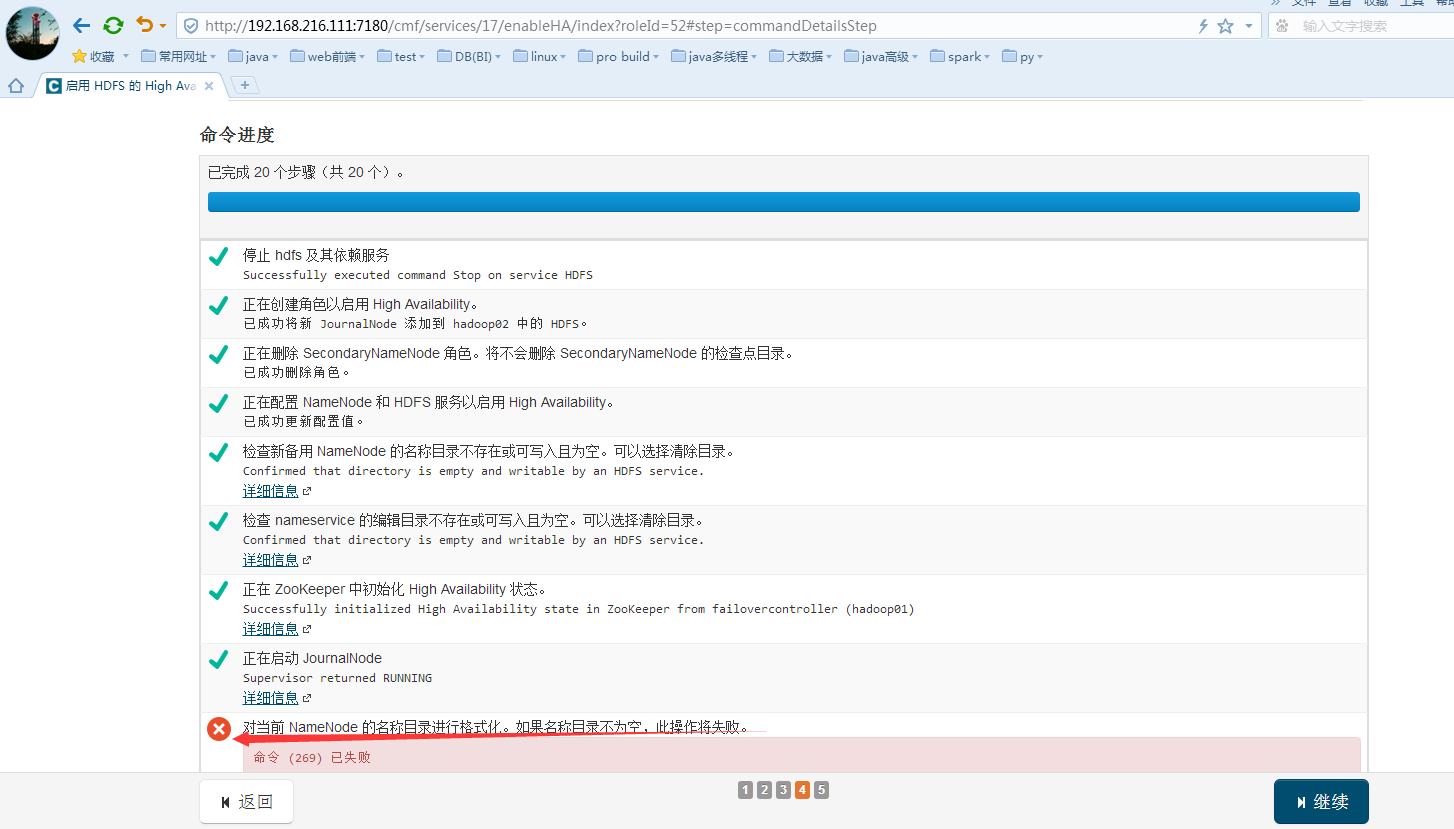
失败格式化已经存在的namenode的节点:因为目录存在数据存在,可以选择手动格式化以前的数据,然后再删除datanode的数据,如果是一开始就搭建HA就不会失败咯。详细信息如下:

完成启动NameNode的HA配置:
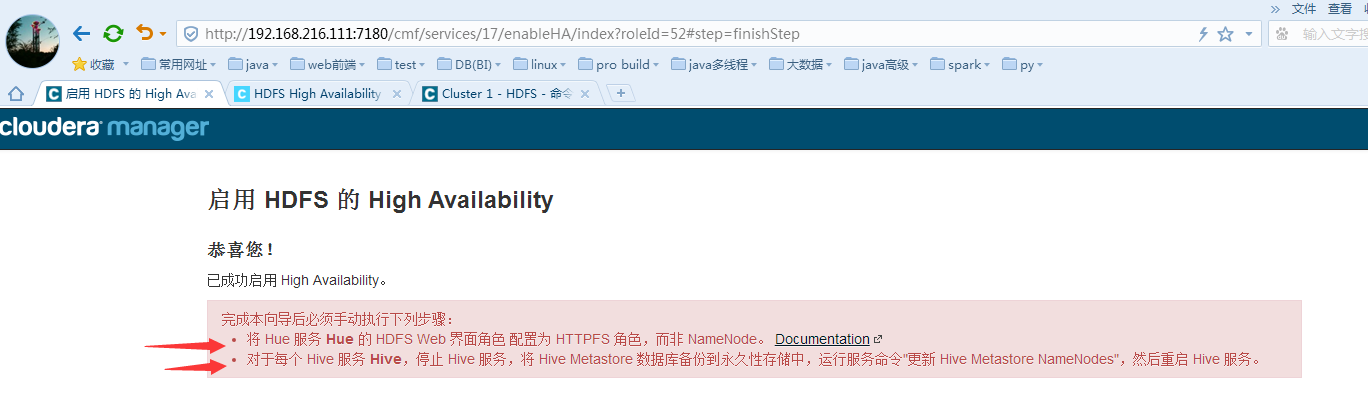
测试NameNode是否可用:
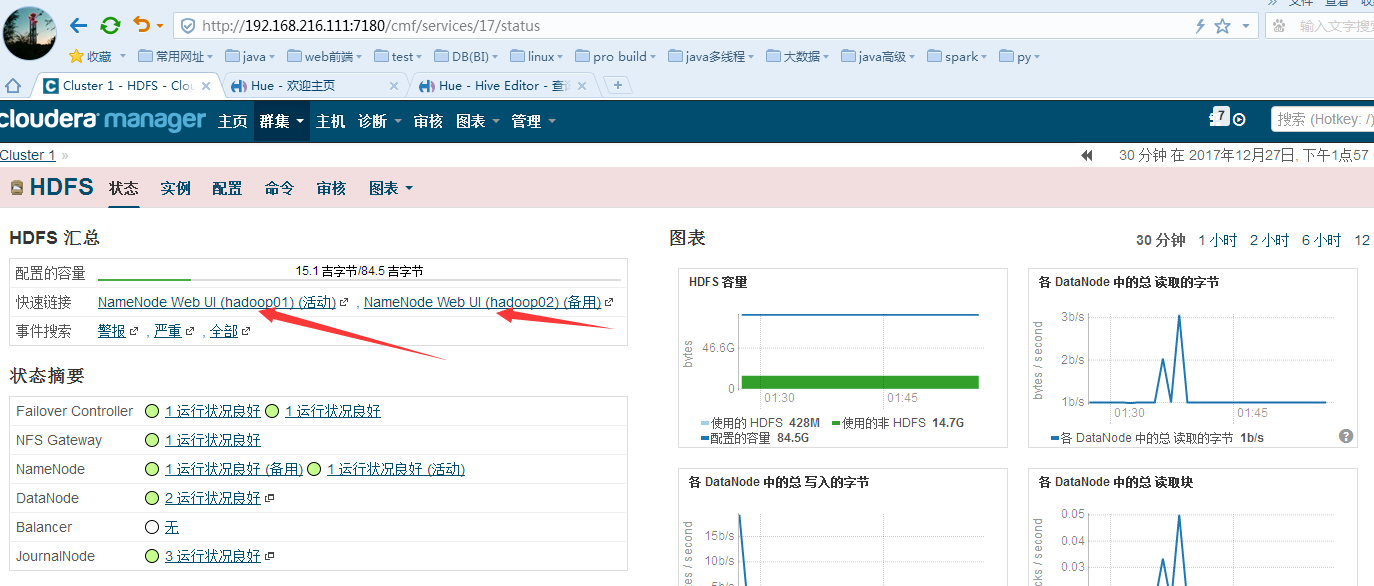
关闭活动的NameNode服务:

证明已经失败转移过来,然后再查看是否能进行hdfs的文件读写操作;然后再启动hadoop01的Namenode再关闭hadoop02的namenode试试能否进行正常切换。
[root@hadoop01 ~] hdfs dfs -put /home/helloworld.sh /
[root@hadoop01 ~] hdfs dfs -cat /helloworld.sh
#!/bin/bash
echo "hello world" >> /home/helloworld
证明可以失败转移后可以进行正常读写,然后再来回关闭namenode试试是否可用即可。
Yarn的resurce的HA:
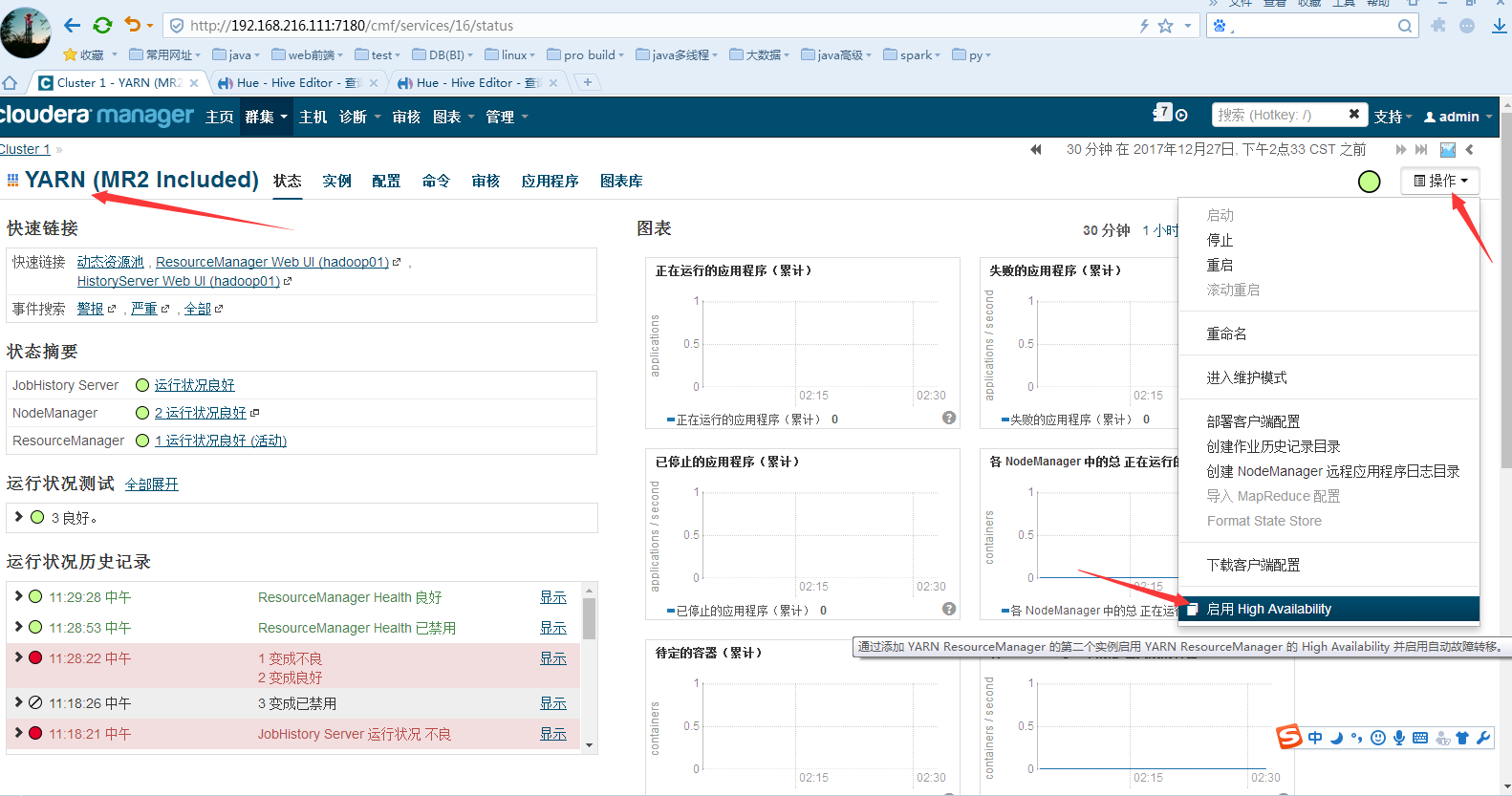
点击启动High Avaliability:
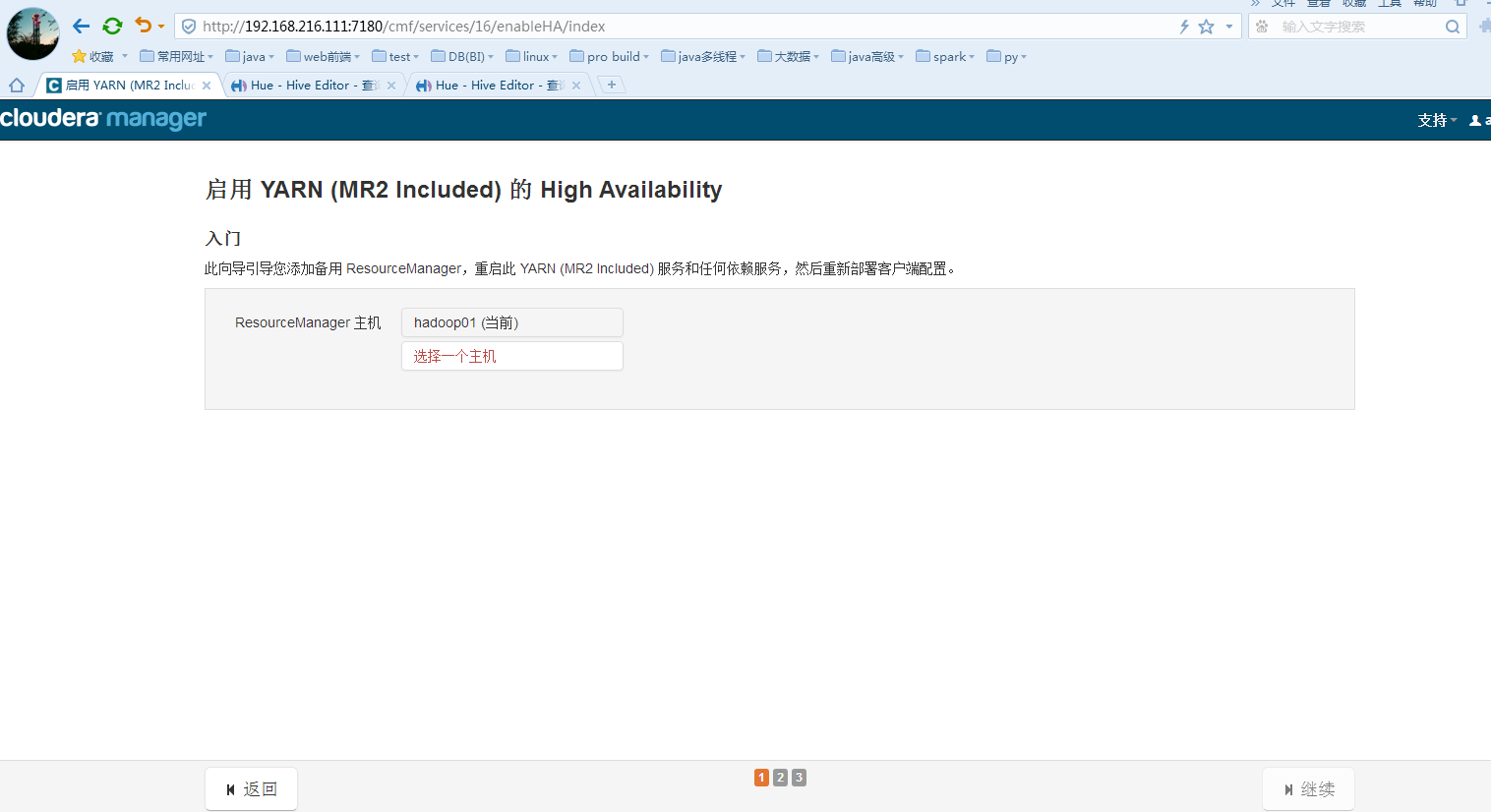
点击选择一个主机,选择hadoop02为备用rm服务主机:

点击确定然后再点击继续:
然后对环境进行检测,只有三项检测,如果三项检测都是没有异常,点击完成即可(我忘记截完成的图啦)。
停掉活动的rm:

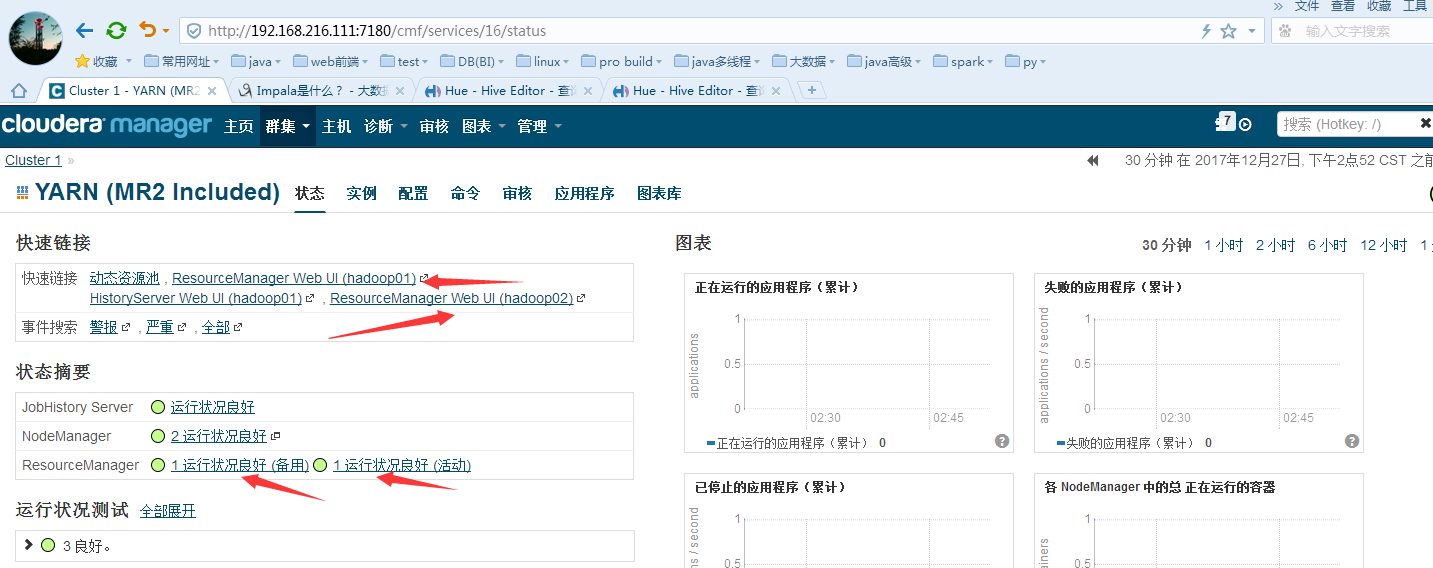
证明是已经失败转移(来回切换几次试试可以失败转移),然后再运行几个mr的job作业即可。
bash-4.1$yarn jar /opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /words /out/01
解决hue中不能查询hive数据的问题:
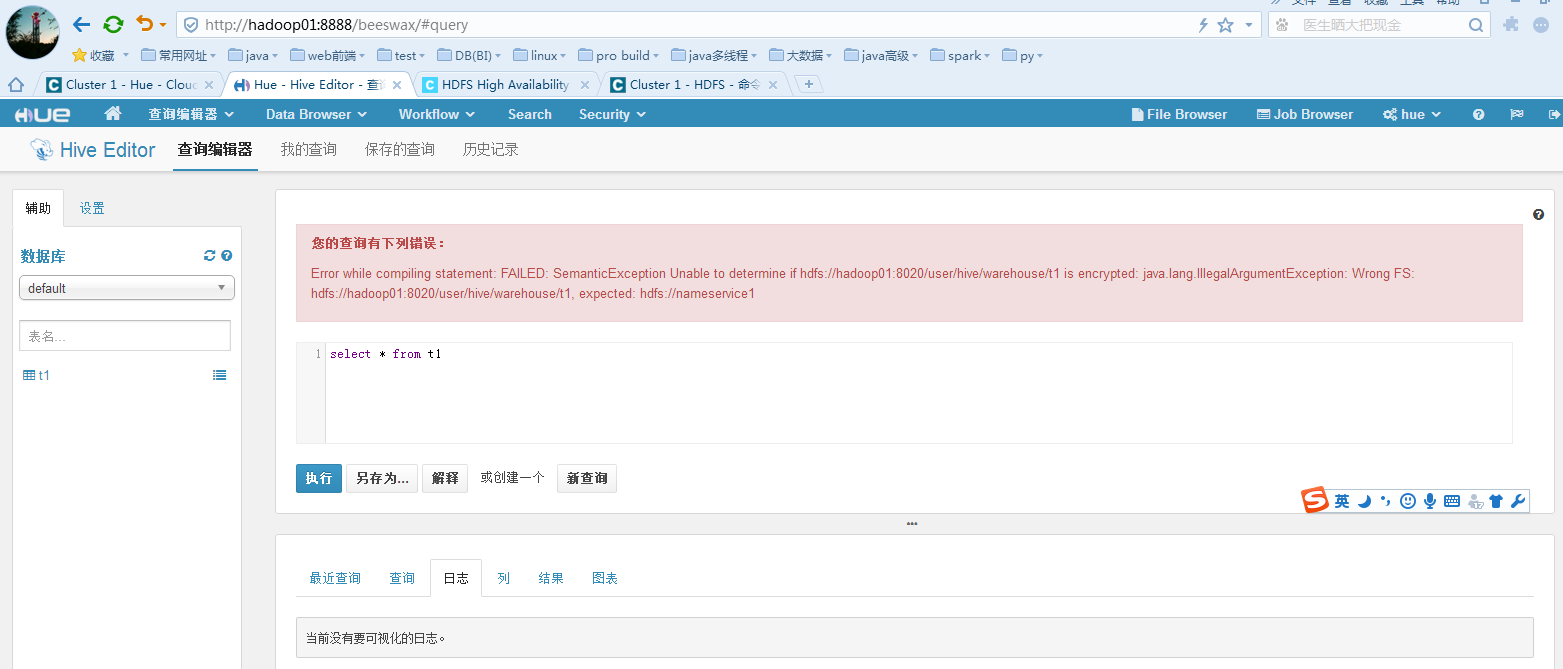
手动批量将hive的元数据信息中的库和表指向的hdfs中的目录修改成HA的即可。
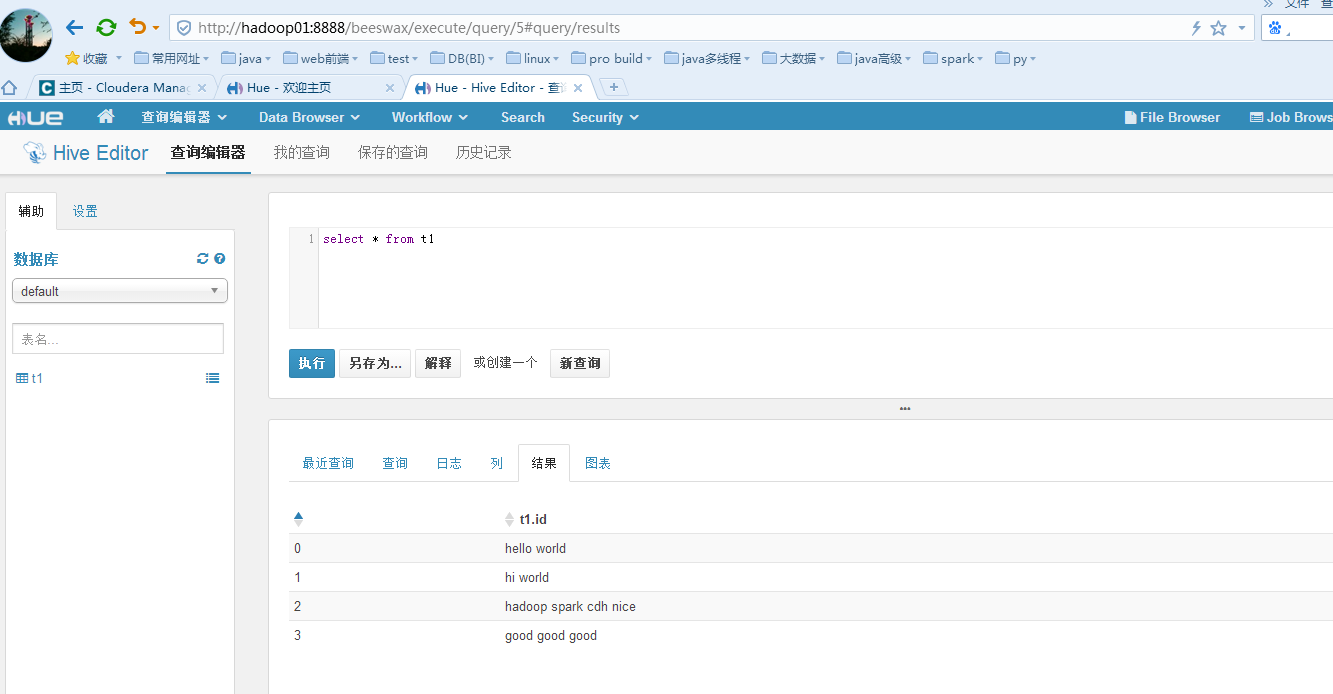
到此,hadoop的hdfs模块和yarn模块的HA已经升级完成.........
而hbase的备份master和hiveserver2建议安装时选择配置在多台服务器中。
注意:一切升级后请检测别的组件是否受影响,即做好完全测试。
















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











