







本文先简要介绍序列标注的经典模型,然后以医疗文本实体识别为例,来介绍CRF和LSTM的应用。
一、序列标注的经典模型
参考论文 Neural Architectures for Named Entity Recognition
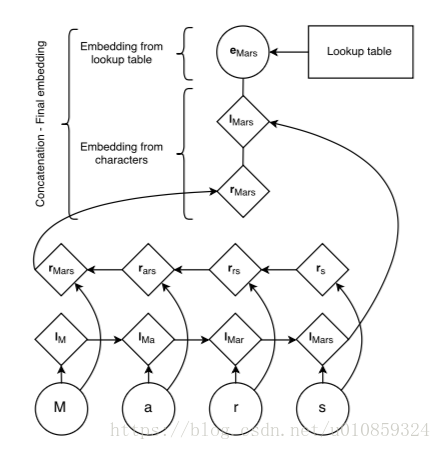
兼顾character-based embedding和word-based embedding,随机初始化character的embedding,用BiLSTM学习character的embedding,前向LSTM的最后一个输出反映的是word的suffix,而后向LSTM最后一个输出反映的是word的prefix。word的embeddind来自于pre-trained,然后将前向LSTM的最后一个hidden,后向LSTM的最后一个hidden,以及word embedding三个向量做concatenation,后接一个dropout层,然后输入到CRF层。
二、CRF和LSTM的对比
1.CRF在小数据集上会有相对较好的表现,而LSTM这样的深度学习模型在数据足够的情况下可以beat CRF;
2.CRF和LSTM经常搭配使用,这种框架已经成为主流;
3.LSTM经常会产生的一个问题是,在序列标注时,在某个位置输出一个结束标记,但是前面却没有开始标记。如果把CRF加在LSTM之上,则可以解决这个问题。
三、医疗文本实体识别
1.CRF模型
数据特征如下图所示
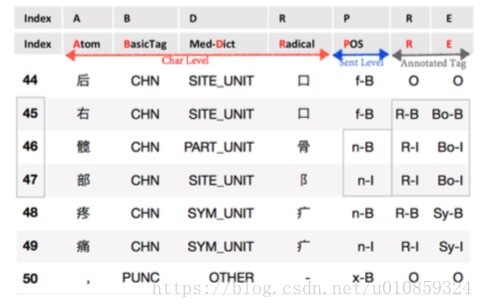
“B”列是字符的“基本标签“,把字符按类型分为7种,定义方法如下
import string
import re
# Tags for the basic information
def basicTags(word):
punStr = string.punctuation + '"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、\u3000、〃〈〉《》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏﹑﹔·!?。。'
engReg = r'[A-Za-z]{1}'
if '%' in word or '%' in word:
return 'PERC'
elif re.match(r'[0-9]{1}', word):
return "NUM"
elif word in punStr:
return "PUNC"
elif word >= '\u4e00' and word <= '\u9fff':
return "CHN"
elif re.match(engReg, word):
return 'ENG'
#elif word in string.whitespace:
#return 'SPA'
elif word == '@':
return 'SPA'
else:
return 'OTHER'“D“列由一个医学词典生成
def matrixPreparing(matrix):
matrix.sort(key = lambda x:len(x))
return matrix[::-1]
# Medical Dictionary Tag
def dictTags(word):
units = 'kBq kbq mg Mg UG Ug ug MG ml ML Ml GM iu IU u U g G l L cm CM mm s S T % % mol mml mmol MMOL HP hp mmHg umol ng'.split(
' ')
chn_units = '毫升 毫克 单位 升 克 第 粒 颗粒 支 件 散 丸 瓶 袋 板 盒 合 包 贴 张 泡 国际单位 万 特充 个 分 次'.split(' ')
med_units = 'qd bid tid qid qh q2h q4h q6h qn qod biw hs am pm St DC prn sos ac pc gtt IM IV po iH'.split(' ')
all_units = units + chn_units + med_units
site_units = '上 下 左 右 间 片 部 内 外 前 侧 后'.split(' ')
sym_units = '大 小 增 减 多 少 升 降 高 低 宽 厚 粗 两 双 延 长 短 疼 痛 终 炎 咳'.split(' ')
part_units = '脑 心 肝 脾 肺 肾 胸 脏 口 腹 胆 眼 耳 鼻 颈 手 足 脚 指 壁 膜 管 窦 室 管 髋 头 骨 膝 肘 肢 腰 背 脊 腿 茎 囊 精 唇 咽'.split(' ')
break_units = '呈 示 见 伴 的 因'.split(' ')
more_units = '较 稍 约 频 偶 偏'.split(' ')
non_units = '无 不 非 未 否'.split(' ')
tr_units = '服 予 行'.split(' ')
all_units = matrixPreparing(all_units)
units = matrixPreparing(units)
chn_units = matrixPreparing(chn_units)
med_units = matrixPreparing(med_units)
if word in units:
return 'UNIT'
elif word in chn_units:
return 'CHN_UNIT'
elif word in med_units:
return 'MED_UNIT'
elif word in site_units:
return 'SITE_UNIT'
elif word in sym_units:
return 'SYM_UNIT'
elif word in part_units:
return 'PART_UNIT'
elif word in break_units:
return 'BREAK_UNIT'
elif word in more_units:
return 'more_UNIT'
elif word in non_units:
return 'NON_UNIT'
elif word in tr_units:
return 'TR_UNIT'
else:
return 'OTHER'“R“列是汉字的偏旁部首,这列结果由两部分组成,一个是一张部首表,如下图

另一个是来自于百度的接口。偏旁部首的计算类如下
class Radical(object):
def __init__(self,rootPath):
self.dictionary_filepath = rootPath + 'sources/xinhua.csv'
self.dictionary = read_csv(self.dictionary_filepath)
self.baiduhanyu_url = baiduhanyu_url
def get_radical(self,word):
if word in self.dictionary.char.values:
return self.dictionary[self.dictionary.char == word].radical.values[0]
else:
return self.get_radical_from_baiduhanyu(word)
def get_radical_from_baiduhanyu(self,word):
url = self.baiduhanyu_url % word
#print(url)
try:
r = requests.get(url)
#print(r.content)
html = str(r.content).decode("utf-8")
except Exception as e:
print('URL Request Error:', e)
html = None
if html == None:
return None
soup = BeautifulSoup(html, 'html.parser')
li = soup.find(id="radical")
radical = li.span.contents[0]
if radical != None:
self.dictionary = self.dictionary.append({'char': word, 'radical': radical}, ignore_index= True)
self.dictionary.to_csv(self.dictionary_filepath, encoding = 'utf-8', index = False)
return radical“P“列是词性标注列。词性编码表可以参考 词性编码表
调用jieba的词性标注函数posseg进行标注,输入一个句子,通过下面的函数可以得到该句子的词性标注
from jieba import posseg as ppseg
def getPOSTagsList(text):
segs = list(ppseg.cut(text))
for i in range(len(segs)):
pair = segs[i]
start = sum(len(p.word) for p in segs[:i])
end = sum(len(p.word) for p in segs[:i+1]) -1
pair.indeces = [start, end]
POSTagsList = []
for p in segs:
word = p.word
for i in range(len(p.word)):
if i == 0:
POSTagsList.append([p.indeces[0] + i, word[i], p.flag+'-B'])
else:
POSTagsList.append([p.indeces[0] + i, word[i], p.flag+'-I'])
return POSTagsList
>>>text = u"美国总统特朗普宣布对中国的贸易战正式生效"
>>>for i in getPOSTagsList(text):
>>> print str(i[0])+"\t"+i[1]+"\t"+i[2]
0 美 ns-B
1 国 ns-I
2 总 n-B
3 统 n-I
4 特 nr-B
5 朗 nr-I
6 普 nr-I
7 宣 v-B
8 布 v-I
9 对 p-B
10 中 ns-B
11 国 ns-I
12 的 uj-B
13 贸 nz-B
14 易 nz-I
15 战 nz-I
16 正 ad-B
17 式 ad-I
18 生 n-B
19 效 n-I“R“列是对“E“列简化的结果,只标记是否是实体,并不区分实体类别。
“E“列是标签列,按实体类型分为五种,即”Sy”、”Bo”、”Ch”、”Tr”、”Di”,再加上BIO标识,就得到E列。
然后就可以搭建CRF模型。论文 Named Entity Recognition for Chinese Clinical Texts by CRF Models中采用了两种CRF架构,一种是单层的,另一种是双层的,
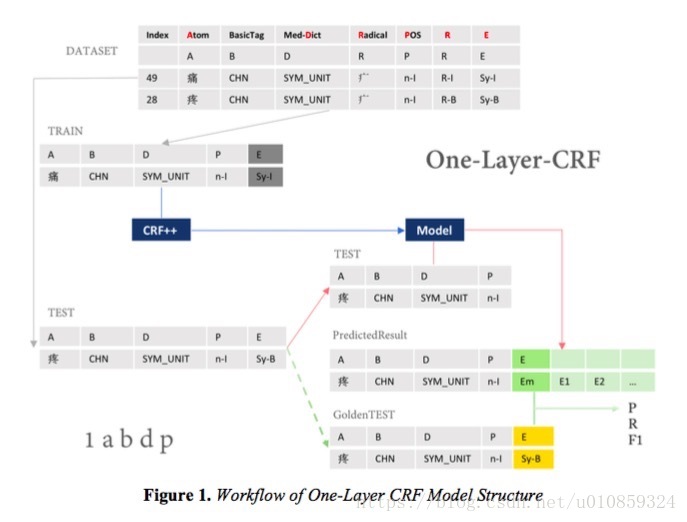
文中的单层网络使用了”A”、”B”、”D”、”P”四列数据来预测标签。
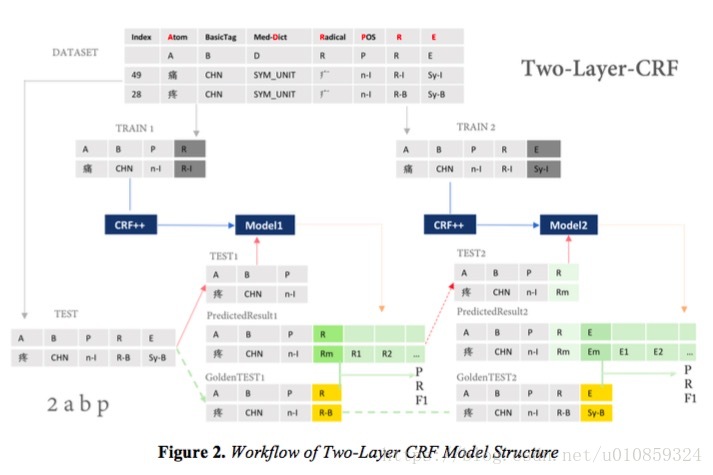
双层的CRF包含了两个子model,model1用”A”、”B”、”P”预测”R”列,model2用”A”、”B”、”P”、”R”列来预测”E”列,model1和medel2独立训练。在做inference的时候,先用model1预测”R”,然后用model2预测”E”。
2.BiLSTM-CRF
我们要对
p(y|x)=p(x|y)⋅p(y)p(x)
p
(
y
|
x
)
=
p
(
x
|
y
)
⋅
p
(
y
)
p
(
x
)
建模,我们把
p(x|y)
p
(
x
|
y
)
改成
p(y|x)
p
(
y
|
x
)
,毕竟CRF的feature function还是比较随意的,想怎么定义就怎么定义(只要有意义就行)。
我们用一个BiLSTM网络拟合
p(y|x)
p
(
y
|
x
)
,视输出为顶层的CRF的feature。
BiLSTM-CRF架构如下图所示
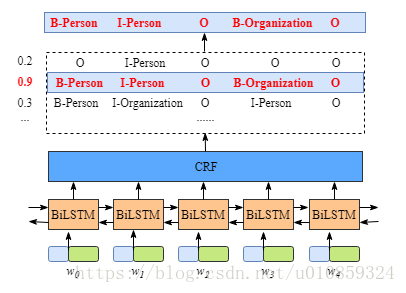
我们假设实体只有两种,即人和组织。输入的句子
x
x
共有5个单词,即使。
输入
w0,w1,w2,w3,w4
w
0
,
w
1
,
w
2
,
w
3
,
w
4
包含了character embedding和word embedding。其中character embedding是随机初始化的,而word embedding来自于一个pre-trained word embedding结果。所有的embedding都是要在训练过程中进行更新的。
所以BiLSTM-CRF的输入是embedding,输出是tag。
看一下底层的BiLSTM,它的输出是什么?
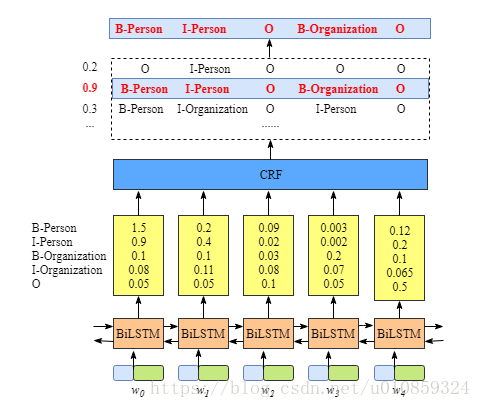
上图显示,BiLSTM的输出是每个label的score。
看起来其实BiLSTM就是我们想要的,为什么还要加个CRF层呢?
上图的例子中,BiLSTM的输出结果就是正确的tagging结果,这只是巧合,很多时候没那么幸运,如下图中的BiLSTM的输出
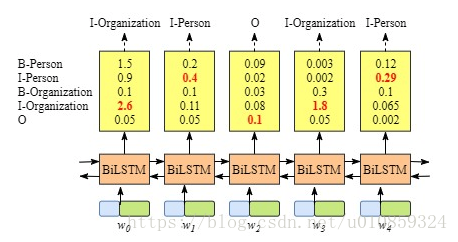
这时候BiLSTM的输出并不是正确答案。
CRF能够学习到数据中的约束(CRF layer can learn constrains from training data)
CRF可以把一些约束条件加到tag的预测中,这些约束条件包括
1)句子的第一个word的tag应当以”B-“或”O”开头,而不是”I-“;
2)tag序列应当是“B-label I-label I-label I-…”形式,先出现”B-“,后出现”I-“;
3)”O I-“是无效的;
等。
CRF可是做到这些,所以就可以大大减少错误标记的数量。那么LSTM为什么做不到呢?
CRF的优势在于可以学习到tag之间的dependence,但是LSTM其实也会考虑之前时刻的tag。也许LSTM学习到的这种的tag间的dependence不够strong?谁知道呢?
那么CRF是怎么做到这些的?
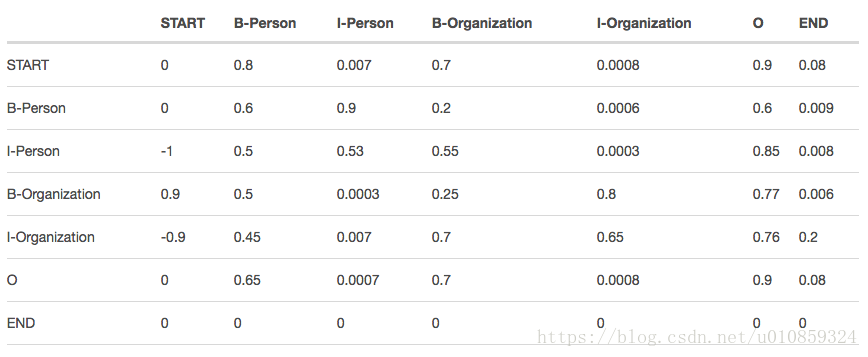
我们来研究CRF。CRF包含两个核心成分,即Emission score和Transition score。
Emission score来自于BiLSTM。
用
ty1y2
t
y
1
y
2
表示transition score,我们可以计算tag之间的transition score,形成一个转移矩阵,如下图所示
参考资料:
https://github.com/floydluo/cctner
https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/#more














 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









