







本篇介绍scrapy的使用步骤。scrapy是python的一个框架,可以通过安装python包的形式安装,必须先安装python。
scrapy安装步骤
- 安装python2.7
- 安装pip
- 安装lxml(抽取数据)
- 安装OpenSSL(网页访问认证)
- 安装Scrapy
使用步骤
- create a project
- define items
- write a spider
- write and configure an item pipeline
- execute crawler
现在通过通过第一、三、五步创建一个爬虫,代码如下。
创建工程
scrapy startproject tutorial
目录结构如下:
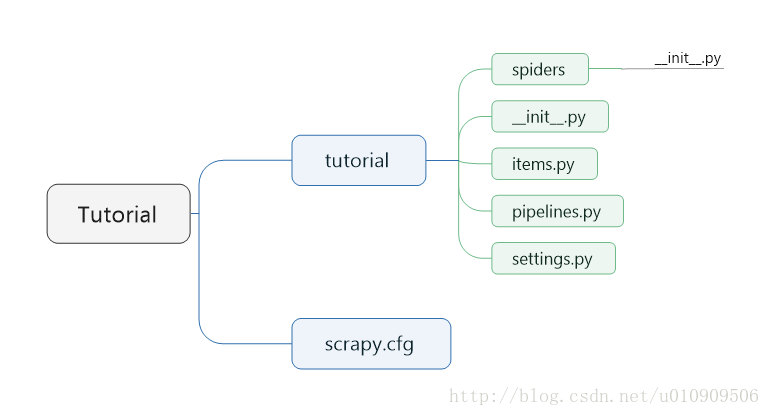
创建一个爬虫
cd tutorial
scrapy genspider dmoz dmoz.org
此时目录结构如下:
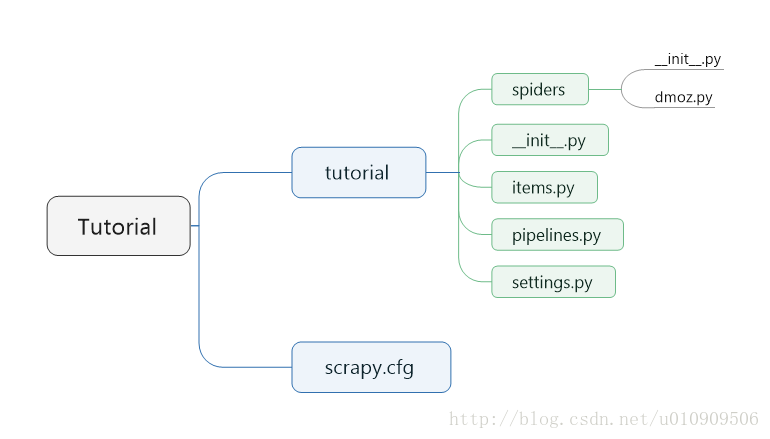
dmoz.py
# -*- coding: utf-8 -*-
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = ['http://dmoz.org/']
def parse(self, response):
pass修改dmoz.py
# -*- coding: utf-8 -*-
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
'http://dmoz.org/Computers/Programming/Languages/Python/Books/',
'http://dmoz.org/Computers/Programming/Languages/Python/Resources/'
]
def parse(self, response):
# 保存start_urls中网页的内容
filename = response.url.split('/')[-2] + '.html'
with open(filename, 'w') as fp:
fp.write(response.body)运行爬虫
scrapy crawl dmoz
此时,爬虫将爬取两个网页的内容
修改爬虫,加入第二步
修改items.py
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
desc = scrapy.Field()
link = scrapy.Field()再次修改dmoz.py
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import TutorialItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
'http://dmoz.org/Computers/Programming/Languages/Python/Books/',
'http://dmoz.org/Computers/Programming/Languages/Python/Resources/'
]
def parse(self, response):
# 获取li标签。通过firefox浏览器的firebug插件很容易获取元素的xpath
lis = response.xpath('/html/body/div[2]/div[3]/fieldset[3]/ul/li')
for li in lis:
item = TutorialItem()
item['title'] = li.xpath('a/text()').extract()
item['link'] = li.xpath('a/@href').extract()
item['desc'] = li.xpath('text()')
yield item
运行爬虫
scrapy crawl dmoz
此时,爬虫将爬取网页中的书籍名称、链接和描述信息
在实际应用中,还应该编写pipelines.py文件,将数据保存到数据库中。

















 1823
1823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









