







该文档是将网上与linux户态内存分配函数相关的资料进行汇总后和一些个人心得,知识来源:
1.https://www.cnblogs.com/dongzhiquan/p/5621906.html
2. https://www.cnblogs.com/huxiao-tee/p/4660352.html
3. https://blog.csdn.net/qq_36675830/article/details/79283113
文章目录
1 malloc
1.1 malloc函数基本功能
#include <malloc.h> //或 #include <alloc.h>
extern void *malloc(unsigned int num_bytes);
1. 功能:为进程动态分配长度为num_bytes字节的内存块。(先在分配虚拟地址,使用时再映射物理地址)
a.内存块长度小于128k,在进程堆区分配
b.内存块长度大于128K,在进程mmap映射区分配
2. 参数:申请内存块长度(单位字节)
3. 返回值:
a.成功:指向分配内存块数据区首地址(指向内存块的指针)
b.失败:返回NULL
void free(void *ptr);
//malloc内存释放函数,和malloc搭配使用
1.2 malloc实现原理(转)
现在glibc里malloc的实现,主要通过三种方法分配内存给用户层。
- malloc将进程堆区进行了分块管理,空闲的虚拟内存块会用链表的形式链接起来。malloc分配内存时,首先会根据需要内存块的大小,在空闲内存块链表中去获取满足要求的内存块。此种做法的好处是不需要系统调用,在用户态实现。
- 堆区用户态分块管理参考:
- https://www.cnblogs.com/blogernice/articles/13041529.html
- https://blog.csdn.net/ordeder/article/details/41654509
- 堆区用户态分块管理参考:
- brk系统调用。当malloc内部内存不够用(不能在空闲内存块中找到合适的内存块),需要向内核申请内存。brk系统调用增大堆顶位置,但是只是虚拟内存。真正使用时会page fault进而真正得到物理内存。
- mmap系统调用。malloc实现有一个问题是只有当堆顶空闲内存区大于128K,内存才真正free还给内核。mmap(匿名映射)会在堆顶与栈底之间的shared libs、files区域给应用一个线性区,也是虚拟内存。好处是munmap的时候,内存是真的还给内核。
ps:brk获得的内存可以给方法1复用,而mmap只能应用自己管理。频繁的mmap和munmap系统调用、用户态与内核态切换以及pagefault开销是很大的。
下面以一个例子来说明内存分配的原理:(转https://www.cnblogs.com/dongzhiquan/p/5621906.html)
情况一:
malloc小于128k的内存,使用brk分配内存,将_edata(有些地方为brk)往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
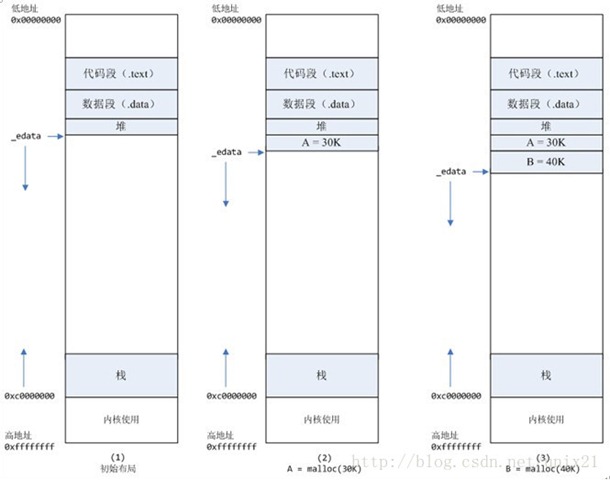
1、进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。_edata指针(glibc里面定义)指向数据段的最高地址。
2、进程调用A=malloc(30K)以后,内存空间如图2: malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。你可能会问:只要把_edata+30K就完成内存分配了?事实是这样的:_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。(对于匿名页进程第一次读,触发缺页异常,缺页异常流程会将该虚拟地址映射到一个linux 内核bss段共享的0页上去,该0页具有只读权限,只有等进程下次写该匿名页时,再次触发缺页异常,进入do_wp_page写时复制流程,此时内核才会分配一个物理页,与对应虚拟地址建立映射关系。这里的0页机制就是为了节省内存。)
3、进程调用B=malloc(40K)以后,内存空间如图3。
情况二:
malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:

4、进程调用C=malloc(200K)以后,内存空间如图4:默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为:brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5、进程调用D=malloc(100K)以后,内存空间如图5;
6、进程调用free©以后,C对应的虚拟内存和物理内存一起释放。

7、进程调用free(B)以后,如图7所示:B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8、进程调用free(D)以后,如图8所示:B和D连接起来,变成一块140K的空闲内存。
9、默认情况下:当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
通过上面的介绍,发现malloc函数在用户态用内存块链表去维护进程的堆区,每次free一个动态分配的堆内存块时,只是在用户态将该内存块的控制模块状态改为free状态,然后将free的内存块加入到空闲内存块链表中去,供下次分配使用,并不会进入内核态解除虚拟地址与物理页的映射关系(内存缩紧情况除外)。这种设计方式和page cache有异曲同工之处。在有些场景下可以减少用户态进程内存访问时缺页中断的次数,从而降低进程内核态cpu使用率。如下列频繁分配释放内存导致的性能问题的分析场景:
-
**场景:**一个压力测试,每秒执行2000次下列请求:每次请求都malloc一块2M的内存,请求后并访问该内存块,然后用munmap释放该内存块。
-
**问题分析:**被测模块在内核态cpu消耗高的原因:每次请求来都malloc一块2M的内存,默认情况下,malloc调用mmap分配内存,请求结束的时候,调用munmap释放内存。假设每个请求需要6个物理页,那么每个请求就会产生6个缺页中断,在2000的压力下,每秒就产生了10000多次缺页中断,这些缺页中断不需要读取磁盘解决,所以叫做minflt;缺页中断在内核态执行,因此进程的内核态cpu消耗很大。缺页中断分散在整个请求的处理过程中,所以表现为分配语句耗时(10us)相对于整条请求的处理时间(1000us)比重很小。
-
解决办法:
-
将动态内存改为静态分配,或者启动的时候,用malloc为每个线程分配,然后保存在threaddata里面。但是,由于这个模块的特殊性,静态分配,或者启动时候分配都不可行。另外,Linux下默认栈的大小限制是10M,如果在栈上分配几M的内存,有风险。
-
禁止malloc调用mmap分配内存,禁止内存紧缩。在进程启动时候,加入以下两行代码:
mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存 mallopt(M_TRIM_THRESHOLD, -1); // 禁止内存紧缩效果:加入这两行代码以后,用ps命令观察,压力稳定以后,majlt和minflt都为0。进程的系统态cpu从20降到10。
-
-
**小结:**可以用命令ps -o majflt minflt -C program来查看进程的majflt, minflt的值,这两个值都是累加值,从进程启动开始累加。在对高性能要求的程序做压力测试的时候,我们可以多关注一下这两个值。
如果一个进程使用了mmap将很大的数据文件映射到进程的虚拟地址空间,我们需要重点关注majflt的值,因为相比minflt,majflt对于性能的损害是致命的,随机读一次磁盘的耗时数量级在几个毫秒,而minflt只有在大量的时候才会对性能产生影响。
1.3 malloc支持多线程
Linux中malloc的早期版本是由Doug Lea实现的,它有一个重要问题就是在并行处理时多个线程共享进程的内存空间,各线程可能并发请求内存,在这种情况下应该
如何保证分配和回收的正确和有效。Wolfram Gloger在Doug Lea的基础上改进使得glibc的malloc可以支持多线程——[ptmalloc](http://www.malloc.de/en/),在glibc-
2.3.x.中已经集成了ptmalloc2,这就是我们平时使用的malloc.
其做法是,为了支持多线程并行处理时对于内存的并发请求操作,malloc的实现中把全局用户堆(heap)划分成很多子堆(sub-heap)。这些子堆是按照循环单链
表的形式组织起来的。每一个子堆利用互斥锁(mutex)使线程对于该子堆的访问互斥。当某一线程需要调用malloc分配内存空间时,该线程搜索循环链表试图获得
一个没有加锁的子堆。如果所有的子堆都已经加锁,那么*malloc*会开辟一块新的子堆,对于新开辟的子堆默认情况下是不加锁的,因此线程不需要阻塞就可以获得
一个新的子堆并进行分配操作。在回收free操作中,线程同样试图获得待回收块所在子堆的锁,如果该子堆正在被别的线程使用,则需要等待直到其他线程释放该子
堆的互斥锁之后才可以进行回收操作。
申请小块内存时会产生很多内存碎片,ptmalloc在整理时需要对子堆做加锁操作,每个加锁操作大概需要5~10个cpu指令,而且程序线程数很高的情况下,锁等待的
时间就会延长,导致malloc性能下降。
因此很多大型的服务端应用会自己实现内存池,以降低向系统malloc的开销。[Hoard](http://www.hoard.org/)和[TCmalloc](http://code.google.com/p/google-
perftools/)是在glibc和应用程序之间实现的内存管理。Hoard的作者是美国麻省的Amherst College的一名老师,理论角度对hoard的研究和优化比较多,相关的文献可
以hoard主页下载到到。从我自己项目中的系统使用来看,Hoard确实能够很大程度的提高程序的性能和稳定性。TCMalloc(Thread-Caching Malloc)是google开发
的开源工具──“google-perftools”中的成员。这里有它的[系统的介绍](http://shiningray.cn/tcmalloc-thread-caching-malloc.html)和[安装方法]
(http://blog.s135.com/post/349/)。这个只是对它历史发展的一个简单介绍,具体改动还需去官网查看.
2 mmap
2.1 mmap原理

通过page cache相关知识可知用户进程常规文件操作(read(),write())需要进行从磁盘到页缓,再到用户进程主存两次数据拷贝。那么用户进程在操控文件时,如何实现从磁盘直接拷贝到数据到进程主存?linux用mmap()函数解决上述问题。
mmap()是一种内存映射文件的方法。进程使用mmap函数映射磁盘文件过程如下:
- 先将文件的一部分内容映射到进程虚拟地址空间中的VMA区域。此时不会对该VMA映射物理内存。
- 进程访问该VMA时,触发缺页异常(page fault)
a. 若该文件对应内容在内存中有页缓存,则直接将VMA映射到对应的缓存页
b. 该文件对应的内容在内存中无页缓存,则linux先分配物理页,并将磁盘数据拷贝到这些刚分配的物理页中,然后将这些物理页添加到文件
对应的页缓存池中,最后将VMA虚拟地址映射到这些刚分配的物理页(以便进程通过虚拟地址直接访问拷贝进主存的文件数据)。

从上述流程可知进程通过mmap方式获取文件数据只进行了一次数据拷贝操作。但是进程访问mmap分配的VMA时,会触发大量page fault,所以mmap()的性能未必高于read()和write().
2.2 mmap映射分类
因为一个文件可以通过mmap被多个进程同时映射后进行读写操作,根据所做的读写操作是否对其他进程可见,mmap分为了文件页共享映射和文件页私有映射:
- mmap文件页共享映射:进程A和B通过mmap映射到同一文件的相同区域。当进程A修改某个page的内容,进程B之后感知到该page的内容是进程A修改后的内容。涉及到共享就存在进程间的竞争,mmap不提供互斥机制,需要调用者自己加锁。
- mmap文件页私有映射:进程A和B通过mmap映射到同一文件的相同区域,进程A对文件的修改进程B无法感知到。mmap私有映射是通过写时复制技术实现的:进程A,B通过mmap私有映射映射到同一个pageC上,当进程A修改pageC内容时,内核会将分配一个新物理页pageA,并将pageC的内容拷贝到pageA。内核还会将进程A中映射到pageC的虚拟空间重新映射到pageA上。这样B进程后续访问pageC,发现内容并未修改。
mmap除了基于文件的映射,还可以进行匿名映射。同文件映射一样,mmap匿名映射也分匿名页共享映射和匿名页私有映射两种情况。
- 共享匿名映射的一个典型应用是作为进程间通信机制的POSIX共享内存。在Linux中,POSIX共享内存是通过挂载在/dev/shm下的tmpfs内存文件系统实现的,创建的每一个共享内存都对应tmpfs中的一个文件,因此POSIX共享内存也可视为共享文件映射。
- 私有匿名映射可以用来实现glibc中的malloc()。传统的malloc()实现靠的是brk,通常brk用于分配小块内存,mmap则用于分配大块内存,这个分界的阈值默认是128KB(可通过mallopt函数调整)。
2.3 mmap函数使用
mmap()的函数原型如下所示:
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
2.3.1 参数介绍

结合图3来理解mmap函数参数
- fd,offset和length用于描述映射的文件区域:
- fd是文件描述符,对于匿名映射fd取值-1(通过打开/dev/zero这个特殊的文件来创建匿名映射,则它也是有不为-1的正常fd值的)
- offset:文件中映射的起始位置
- length:映射长度,访问超过该长度可能触发SIGSEGV异常(segmentation fault),但是若访问地址超过length长度,但是落在了进程VMA的地址区间里,就不会报SIGSEGV异常,但后续后续出现bug,会难于排查。
- prot用于对映射内存区域的权限控制,包括PROT_READ(可读),PROT_WRITE(可写)和PROT_EXEC(可执行),还有一个很特殊的PROT_NONE,就是既不可读也不可写更不可执行,用来实现防范攻击的guard page。如果攻击者访问了某个guard page,就会触发SIGSEV,作用和地雷是差不多的。prot属性是可以通过mprotect()动态修改的(mprotect并不局限于操作由mmap映射的内存区域,它可以操作任意区域的内存)
- "flags"用于指定映射是基于文件的还是匿名(MAP_ANONYMOUS)的,是共享的(MAP_SHARED)还是私有的(MAP_PRIVATE)
- addr用于指定映射到的VMA的起始地址,这个地址也必须按page size对齐。映射是由内核完成的,但进程可以通过addr参数建议一个它认为的最佳地址(没有这种要求就设置addr为NULL)。如果addr和addr+length之间的虚拟内存空间恰好是可用的,那么内核会满足进程的这一要求。如果flags中加上MAP_FIXED,那就是进程要求必须映射到这个addr起始的区域,当然,这会增加映射失败的概率。
2.3.2函数返回值
mmap()的返回值是实际映射到的VMA起始地址
2.3.3 函数mmap使用细节和场景分析
2.3.3.1 mmap使用细节:
- 内存的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。为了匹配内存的操作,mmap从磁盘到虚拟地址空间的映射也必须是页。
- offset参数必须按照page size对齐
- length若不按page size对齐,linux内核会填充一部分长度确保length按page size对齐
- 文件长度是一定的,使用mmap函数时offset和length+offset的大小都应该小于文件长度。实际上mmap并不会对offset和length + offset的长度进行检查,因此mmap建立的映射区域可能不在文件长度范围内。
- mmap映射建立之后,即使文件关闭,映射依然存在。因为映射的是磁盘的地址,不是文件本身,和文件句柄无关。同时可用于进程间通信的有效地址空间不完全受限于被映射文件的大小,因为是按页映射。
2.3.3.2 mmap函数场景分析:
场景1:一个文件的大小是6000字节,mmap函数从一个文件的起始位置开始,映射6000字节到虚拟内存中(页大小为4K)。
因为mmap函数对应进程虚拟地址空间和内存的映射是以页为单位(4096字节),虽然被映射的文件只有6000,但是mmap对应进程的虚拟地址区域需要页对齐,所以mmap函数执行后,实际映射到的虚拟内存区域不许是8192字节,映射后对应关系如图4所示。

此时:
- (1)读/写前6000个字节,会返回操作文件内容。
- (2)读字节60008191时,返回数据结果全为0。写60008191时,进程不会报错,但是所写的内容不会写入原文件中 。
- (3)读/写字节8192以外的磁盘部分,会返回一个SIGSECV错误。
场景2:一个文件长度为10240字节,mmap函数从文件的起始位置开始,映射了5120字节(页大小为4K)
同理因为需要页对齐,内核会将mmap映射的内存区域扩充到8196字节,映射后对应关系如图5所示.访问mmap映射范围内的内存区域都能正常返回文件内容。但是我们不能保证mmap映射的区域完全落在文件的长度范围内,映射区域就能正常访问,因为事务具有变化性,文件页不例外,比如它可以通过truncate()/ftruncate()截断,截断之后文件的长度如果减小了(truncate也是可以增大的),然后你刚好访问了被截断的这段区域,依然会抛出SIGBUS异常信号。

场景3:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射15000字节到虚拟内存中,即映射大小超过了原始文件的大小。
分析:由于文件的大小是5000字节,和情形一一样,其对应的两个物理页。那么这两个物理页都是合法可以读写的,只是超出5000的部分不会体现在原文件中。由于程序要求映射15000字节,而文件只占两个物理页,因此8192字节~15000字节都不能读写,操作时会返回异常。如图6所示

此时:
(1)进程可以正常读/写被映射的前5000字节(0~4999),写操作的改动会在一定时间后反映在原文件中。
(2)对于5000~8191字节,进程可以进行读写过程,不会报错。但是内容在写入前均为0,另外,写入后不会反映在文件中。
(3)对于8192~14999字节,进程不能对其进行读写,会报SIGBUS错误。
(4)对于15000以外的字节,进程不能对其读写,会引发SIGSEGV错误。
场景4:一个文件初始大小为0,使用mmap操作映射了1000*4K的大小,即1000个物理页大约4M字节空间,mmap返回指针ptr。
分析:如果在映射建立之初,就对文件进行读写操作,由于文件大小为0,并没有合法的物理页对应,如同场景3一样,会返回SIGBUS错误。
但是如果,每次操作ptr读写前,先增加文件的大小,那么ptr在文件大小内部的操作就是合法的。例如,文件扩充4096字节,ptr就能操作ptr ~ [ (char)ptr + 4095]的空间。只要文件扩充的范围在1000个物理页(映射范围)内,ptr都可以对应操作相同的大小。
这样,方便随时扩充文件空间,随时写入文件,不造成空间浪费。















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









