







文章转自http://blog.csdn.net/happyer88/article/details/46625639
Fisher vector学习笔记》中介绍了fisher vector相关知识,本文接着这片学习笔记,来记录论文《Improving the Fisher Kernel for Large-Scale Image Classification》中第三部分提出的对fisher vector的3种改进。
1,L2 Normalization
首先假设一幅图像的特征们
X=xt,t=1...T
服从一个分布p,对于Large-Scale image,根据大数定律,样本数T增大时,样本均值收敛于样本期望
Ex−p
,所以可将(1)式的fisher vector写成(2)式:
现在假设能把p分解成两部分:
属于图像背景的部分(a back-ground image-independent part) ,这部分样本服从分布 uλ ;
属于图像特征的部分(an image-specific part),这部分样本服从分布q.
定义 0<=w<=1 是image-specific信息在图像中所占的比率,则有:
则(2)式可以写成:
参数 λ 是在GMM建模时通过解最大似然问题得到的,也就是说,这个 λ 使得:
所以(4)式为:
从(6)式可以看出:
独立于图像的信息(image-independent information)在fisher vector的表示中被丢弃掉了;
fisher vector的表示仍然与image-specific信息所占比率w有关。
总结来说就是,两个包含相同目标(object),但有不同背景的图,会有不同的fisher vector表示。
但是对于较小的object有较小的w值,这样的object在fisher vector表示中容易被忽略。所以要消除对w值的依赖。
要消除对w值的依赖,可以对fisher vector GXλ 做L2 normalization,也就等价于把原来的核函数 K(X,Y) 替换为
2,Power Normalization
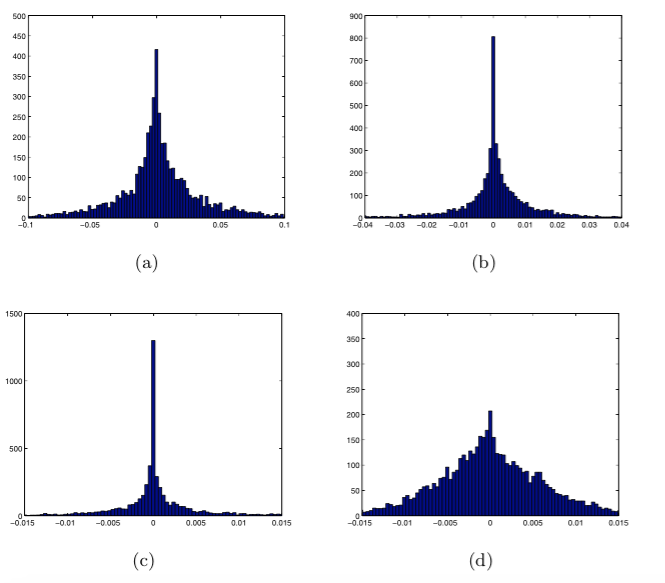
这种改进方法来自观察得到的经验:GMM中的Gaussian component数目增加时,Fisher vector会变得稀疏。这是因为component增加时,样本
xt
由component i生成的概率
γt(i)
会变小,当这个概率接近0时,
GXμ,i,GXσ,i
也接近null。
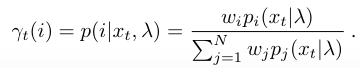

此时,特征在一个维度上的值的分布变得更尖锐,如下图。图(a)(b)(c)是没有做power normalization时,GMM component数为16、64、256的情况。图(d)是有256 Gaussian,且做了power normalization(
α
=0.5)的情况。
α
是optimal value,随Gaussian的数目变化而变化,这里作者是通过实验得到0.5这个值。
这里说的power normalization就是对每一维应用如下函数:
因为注意到L2 normalized vector的内积就是L2 距离,而对于稀疏向量(就是power normalize之前的fisher vector)相似性(similarity)的度量,L2距离是一种poor measure,所以用来做分类效果不好。所以要unsparsify,也就是应用上式。
如果要对fisher vector做L2 normalization和power normalization,可先做power后再做L2,后做L2照样是会消除对w值的依赖。
3,Spatial Pyramids
首先把原图多次划分,得到多个子区域,然后对每个子区域提取fisher vector,再对这些fisher vector做average pooling。论文中是有8个子区域,得到8个fisher vector,对于整幅图提取一个fisher vector, 然后将图划分为上中下3部分,这3个子区域各提取一个fisher vector,然后将原图划分为4个象限,每个象限计算一个fisher vector。这8个fisher vector都可以通过L2 normalization来消除对w值的依赖。















 7826
7826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









