







一、反向传播的特点
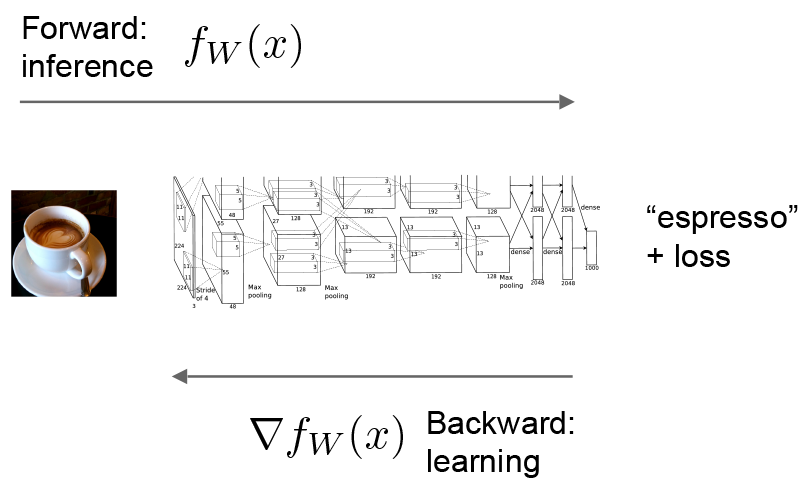
CNN进行前向传播阶段点,依次调用每个Layer的Forward函数,得到逐层的输出,最后一层与目标函数比较得到损失函数,计算误差更新值,通过反向传播路径层达到第一层,所有的权值层在反向传播结束后一起更新。
二、损失函数
损失层(lossLayer)是CNN的终点,接受两个Blob作为输入,其中一个为CNN的预测值,另一个是真实标签。损失层将这两个输入进行一系列的运算,得到当前网络的损失函数(Loss Function),一般记为L(Θ),其中Θ表示当前网络权值构成的向量空间。机器学习的目的是在权值空间中找到让损失函数L(Θ)最小的权值Θ,可以采取一系列的优化方法(如SGD)逼近权值Θ。
Note:损失函数是在前向传播计算中得到的,同时也是反向传播的起点。
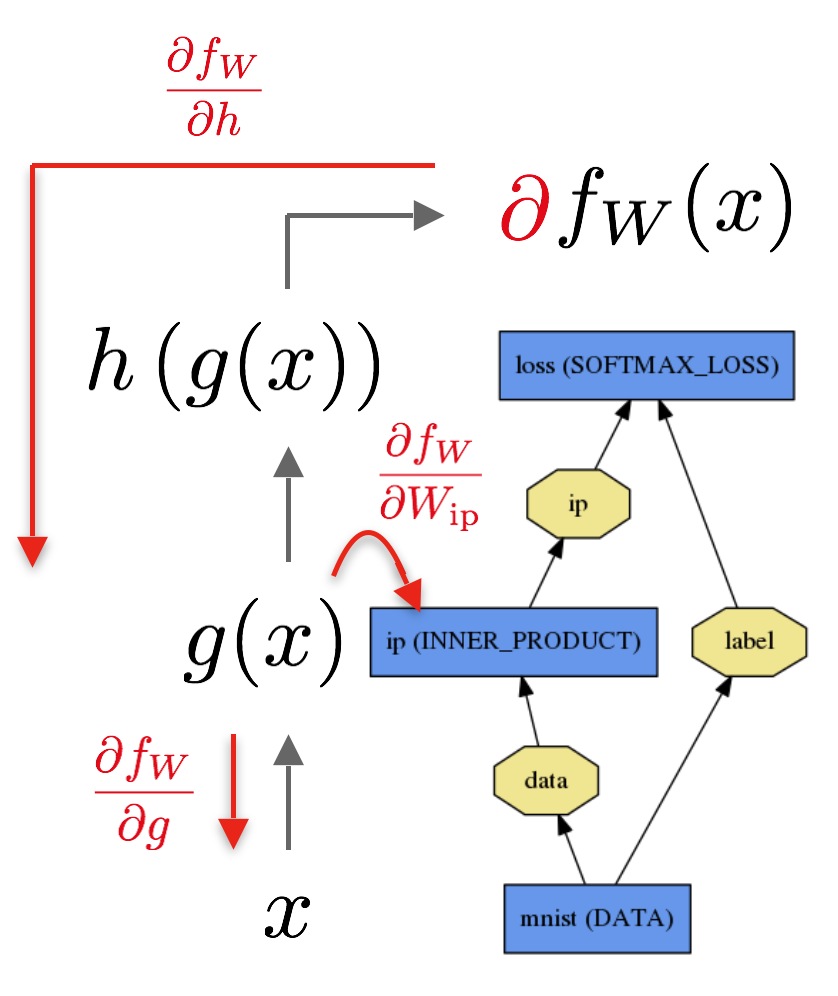
前向传播:通过网络的输入计算输出结果的过程,在前向传播中,caffe整合每一层的计算得到整个模型的计算函数,这个过程是个自底向上的过程。数据x通过通过内积层得到g(x),然后通过softmax得到h(g(x))和损失函数(softmax loss)fw(x).
反向传播网络:根据损失计算梯度,在反向传播过程中,Caffe通过自动求导计算逆向组合每一层的梯度得到整个模型的梯度,在反向传播中,这个过程是自顶向下的。如图:
三、算法描述
Caffe中实现了多种损失层,分别用于不同的场合。其中SoftmaxWithLossLayer实现了Softmax+交叉熵损失函数计算的过程,适用于单lable 的分类问题;另外欧式损失函数(用于回归问题)、Hinge损失函数(最大间隔分类,SVM)、Sigmoid+交叉熵损失函数(用于多属性,多分类问题)















02-22
 569
569
569
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









