







 这篇博客详细记录了四个OpenCL主机端同步实验,包括事件状态查询、异步回调、命令同步以及主机与设备命令同步。实验展示了不同同步方法的效果,如异步执行、命令间的依赖关系,并通过clFinish()和clWaitForEvents()函数控制主机线程的执行。文章提供了实验结果和相关代码,供读者参考。
这篇博客详细记录了四个OpenCL主机端同步实验,包括事件状态查询、异步回调、命令同步以及主机与设备命令同步。实验展示了不同同步方法的效果,如异步执行、命令间的依赖关系,并通过clFinish()和clWaitForEvents()函数控制主机线程的执行。文章提供了实验结果和相关代码,供读者参考。
关于主机端同步,我一共进行了四个实验;主要是对四中方法的实验;
实验一
cl_int clGetEventInfo(cl_event event,
cl_event_info para_name,
size_t param_value_size,
void* para_value,
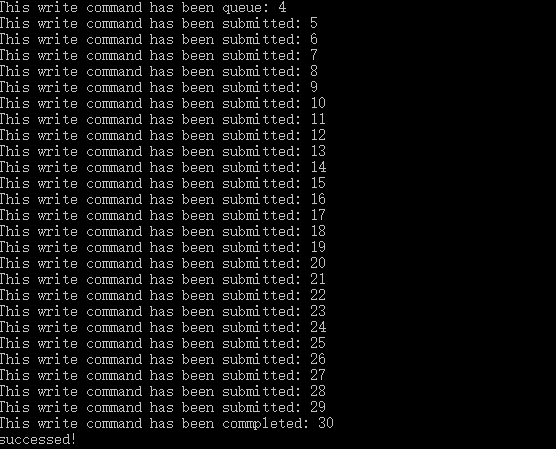
size_t * para_value_size_ret);该函数主要用于查询事件状态;代码中主要是对event1状态的读取;
注意:
clEnqueueWriteBuffer()函数要采用非阻塞方式来调用;
程序中的后两个状态不是在主机端维护,所以读不到;所以要同步当前的事件对象的话,需要使用后面介绍的方法;
在Windows与Linux系统下,如果使用AMD的OpenCL实现可以在主机端捕获到CL_COMPLETE状态,但是RUNNING捕获不到。
实验结果
实验二
该实验采用异步回调的方式来跟踪当前事件状态
cl_int clSetEventCallback(cl_event event,
cl_int command_exec_callback_type,
void (*pfn_notify)(cl_event, cl_int,void *),
void * user_data);该函数的优点在于可以异步回调;最好在clEnqueueWriteBuffer之后就调用该函数,否则可能需要捕获的状态已经过去了;
实验结果
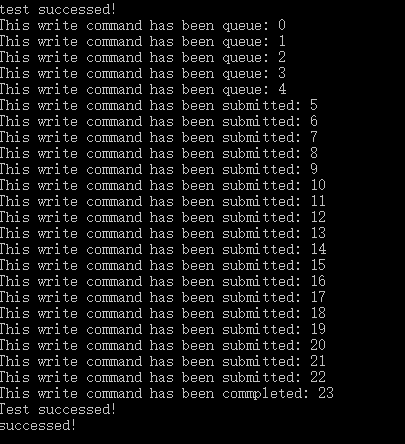
从实验结果可以明显看到是异步执行的。
实验三
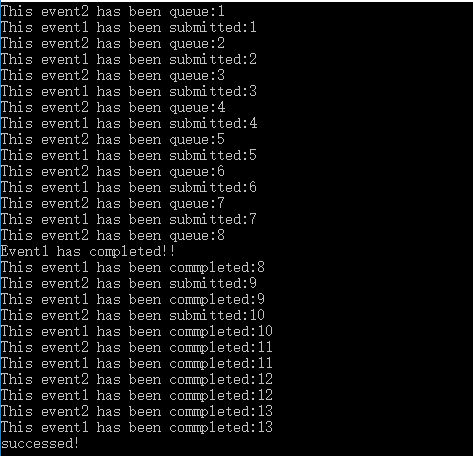
该实验是通过设置clEnqueueWriteBuffer函数的后三个参数,分别是事件数量,等待事件列表,当前命令同步事件;
将evt1设置为第一个写缓存命令的同步事件。调用第二个clEnqueueWriteBuffer,把evt1作为它的等待事件列表,evt2作为同步事件;
为了看到evt1先于evt2执行,我用到了前面两个实验中的状态查询和异步回调函数。在实验结果中除了能看到本实验效果以外,还能看到异步回调函数的异步执行效果。
实验结果
实验四
前面三个实验介绍的是命令之间的同步;本实验主要介绍主机线程与设备命令之间的同步。如果在某个命令完成之前,我们不希望主机线程继续往下执行,可以使用clFinish()函数来将主机线程挂起,知道该命令队列所有命令执行结束。
当然如果我们只希望某一个命令执行结束之前主机线程挂起,那么我们可以使用clWaitForEvents函数;
实验四可以采用获取系统时间的方法,检测该函数等待的时间以验证试验效果;
本试验是通过在clWaitForEvents函数之后捕获事件状态,注释掉该函数以后获得以下效果:

我们可以捕获到入列状态;但是如果不注释该函数
获得如下效果:

可以看出,只能捕获到完成状态;
下面是实验程序代码,有错误的地方欢迎大家指正;
host.c
#include<stdio.h>
#include<windows.h>
#include<CL/cl.h>
#pragma warning( disable : 4996 )
#define MIXSIZE 8192
static volatile int canContiue = 0;
static __stdcall MyEvent(cl_event event, cl_int status, void *userdata) {
// if (status == CL_SUBMITTED) {
if (status == CL_COMPLETE) {
//实验二
/* printf("test successed!\n");
canContiue = 1;*/
//实验三
printf("Event1 has completed!!\n");
canContiue = 1;
}
}
int main() {
cl_int error;
cl_platform_id platforms;
cl_device_id devices;
cl_context context;
FILE *program_handle;
size_t program_size;
char *program_buffer;
cl_program program;
size_t log_size;
char *program_log;
char kernel_name[] = "createBuffer";
cl_kernel kernel;
cl_command_queue queue;
//获取平台
error = clGetPlatformIDs(1, &platforms, NULL);
if (error != 0) {
printf("Get platform failed!");
return -1;
}
error = clGetDeviceIDs(platforms, CL_DEVICE_TYPE_GPU,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









