







文章目录
1、简介
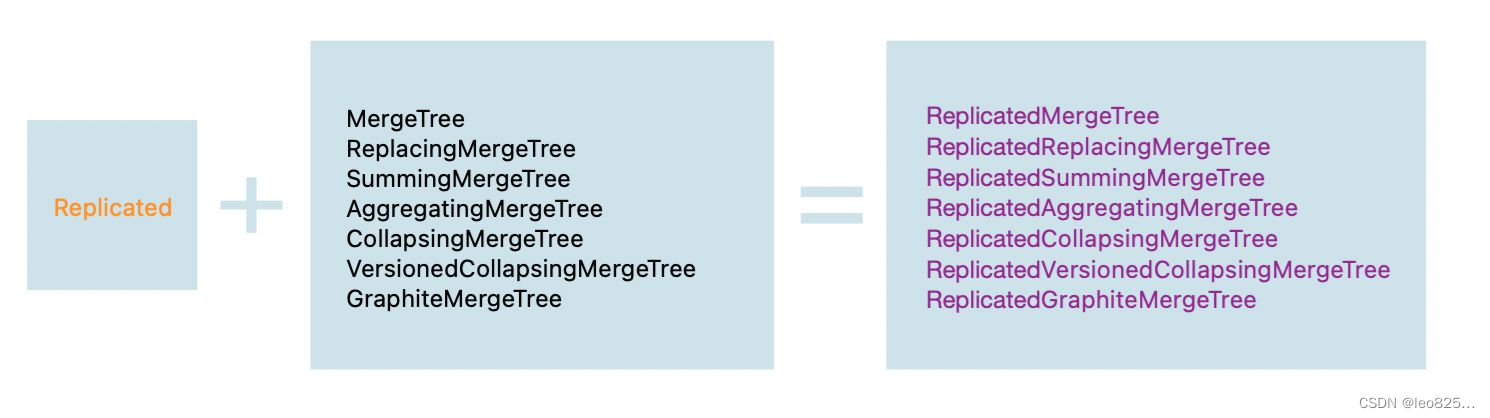
ClickHouse 有很多表引擎,而在众多的表引擎中,又属合并树(MergeTree)表引擎及其家族系列(*MergeTreee)最为强大,在生产环境的绝大部分场景中,都会使用此系列的表引擎。合并树表引擎家族如下图所示:
2、MergeTree 创建方式与存储结构
MergeTree 在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。ClickHouse 会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并数据名称的由来。
2.1、MergeTree 的创建方式
CREATE TABLE table_name (
...字段省略
) ENGINE = MergeTree()
[PARTITION BY xx]
[ORDER BY xx]
[PRIMARY KEY xx]
[SAMPLE BY xx]
[SETTINGS name=value]
(1)PARTITION BY [选填]:分区键,用于指定表数据以何种标准进行分区。
(2)ORDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序字段既可以是单个列字段,也可以通过元组的形式使用多个列字段,顺序以ORDER BY 后面的字段先后顺序来排序。
(3)PRIMARY BY [选填]:主键,顾名思义,声明后会依照主键字段生成以及索引,用于加速表查询。
(4)SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标准进行采样。
(5)SETTINGS:index_granularity [选填]:index_granularity 对于 MergeTree 而言是一项非常重要的参数,他表示索引的粒度,默认值为 8192。也就是说,MergeTree 的索引在默认情况下,每间隔 8192 行数据才生成一条索引,具体声明方式如下所示:
CREATE TABLE table_name (
...字段省略
) ENGINE = MergeTree()
... 信息省略
SETTINGS index_granularity=8192;
(6)SETTINGS:index_granularity_bytes [选填]:index_granularity_bytes 每一批次写入数据的体量大小,自适应间隔大小,根据每一批次写入数据的体量大小,动态划分间隔大小,默认为 10M(10*1024*1024)。
2.2、MergeTree 的存储结构
MergeTree 表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上,其完整的存储结果如下所示:
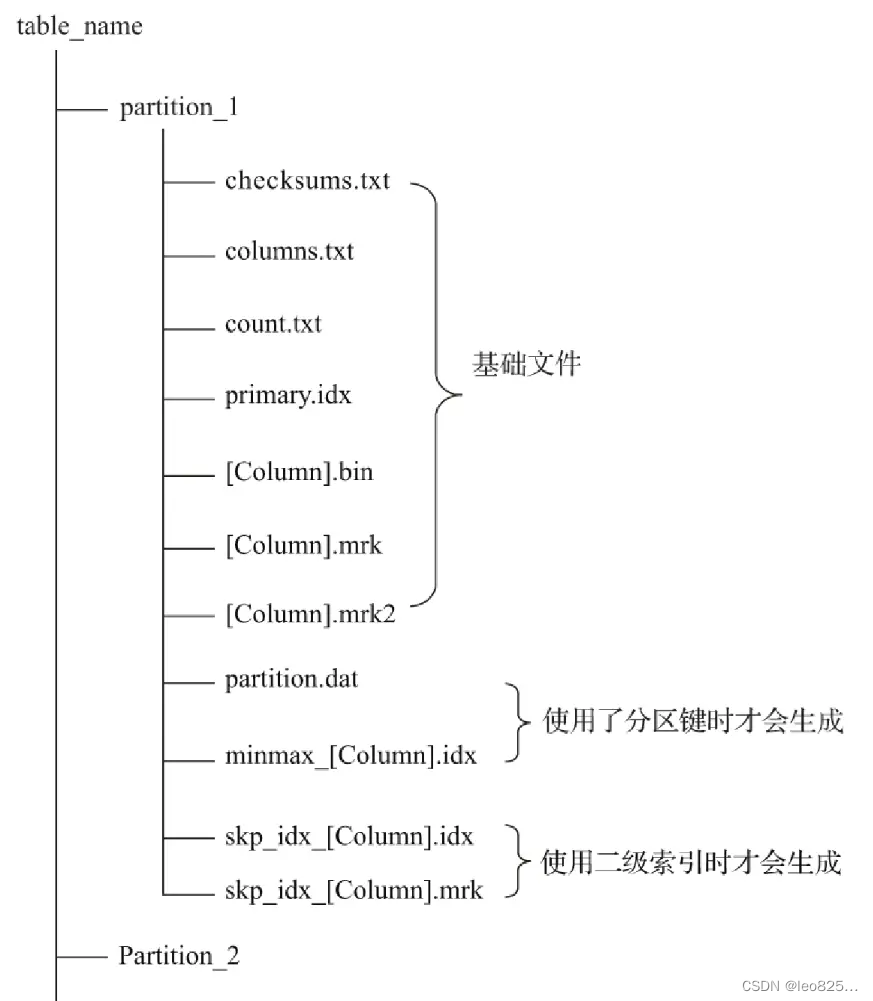
一张数表的完整物理结构分3个层级,依次是数据表目录、分区目录及各分区下具体的额数据文件。
(1)partition:分区目录,余下各类数据文件都是以分区目录的形式被组织存放的,属于相同分区的数据,最终会被合并到同一个分区目录。
(2)checksum.txt:校验文件,使用二进制格式存储。它保存了各类文件(primary.idx、count.txt等)的 size 大小及 size 的哈希值,用于快速检验文件的完整性和正确性。
(3)columns.txt:列信息文件。
(4)count.txt:计数文件,记录当前数据分区目录下数据总行数。
(5)primary.idx:一级索引文件,用于存放稀疏索引。
(6)[Column].bin:数据文件,使用压缩格式存储,默认为 LZ4 压缩格式,用于存储某一列数据。多个列就有多个 .bin 文件
(7)[Column].mrk:列字段标记文件,标记文件中保存了 .bin 文件中数量的偏移量信息。首先通过 primary.idx 找到对应数据偏移量,然后再通过偏移量直接从 .bin 中读取数据。.mrk 标记文件和 .bin 文件一一对应。
(8)[Column].mrk2: 如果使用了自适应大小的索引间隔,则标记文件会以 .mrk2 命名,作用原理和 .mrk 一样。
(9)partition.dat 与 minmax_[Column].idx: 用了分区键会产生,partition.dat 用于保存当前分区下分区表大师最终生成的值;minmax 索引用于记录当前分区下分区字段对应原始数据的最小和最大值,查询的时候可快速跳过不必要的分区目录,减少数据扫描范围。
(10)skp_idx_[Column].idx 与 skp_idx_[Column].mrk: 如果建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件。二级索引又称跳数索引。
3、MergeTree 数据分区
3.1、分区目录的命名规则
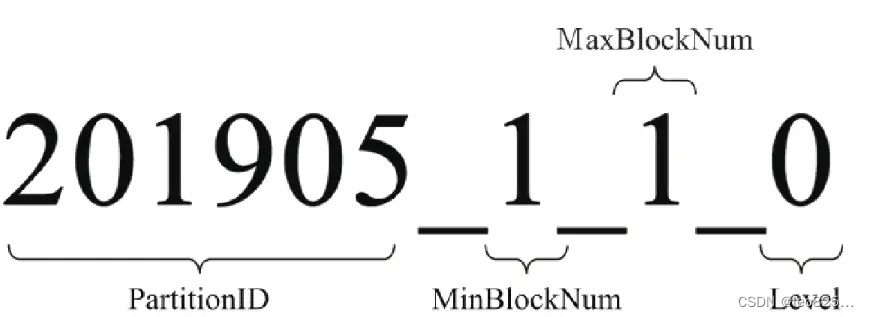
**(1)PartitionID:**分区ID,这里是具体的日期。
**(2)MinBlockNum 和 MaxBlockNum:**最小数据块编号与最大数据块编号。计数在单张 MergeTree 数据表内全局累加。
**(3)Level:**合并的层级,相同分区发生合并,则相应分区内计数累计加1。
3.2、分区目录合并过程

(1)MergeTree 分区目录不是在数据表创建后就存在的,而是在数据写入过程中被创建的。
(2)伴随着每一批数据的写入,MergeTree 都会生成一批新的分区目录
4、一级索引
4.1、索引粒度
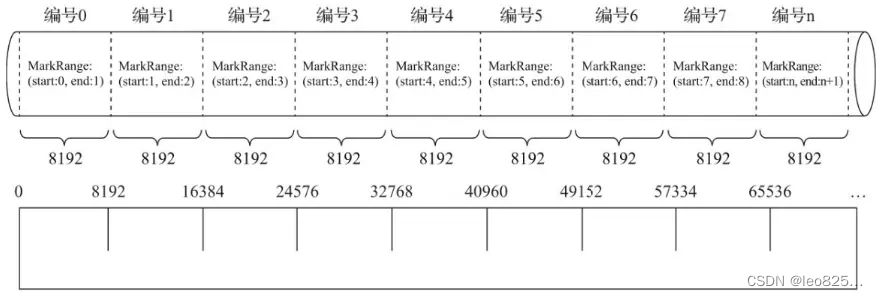
稀疏索引的优势在于使用少量的索引标记就能够记录大量数据的区间位置信息,而且数据量越大优势越为明显。
4.2、索引生成
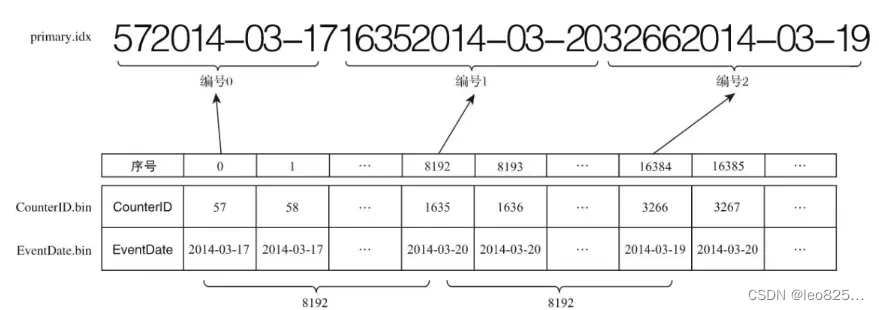
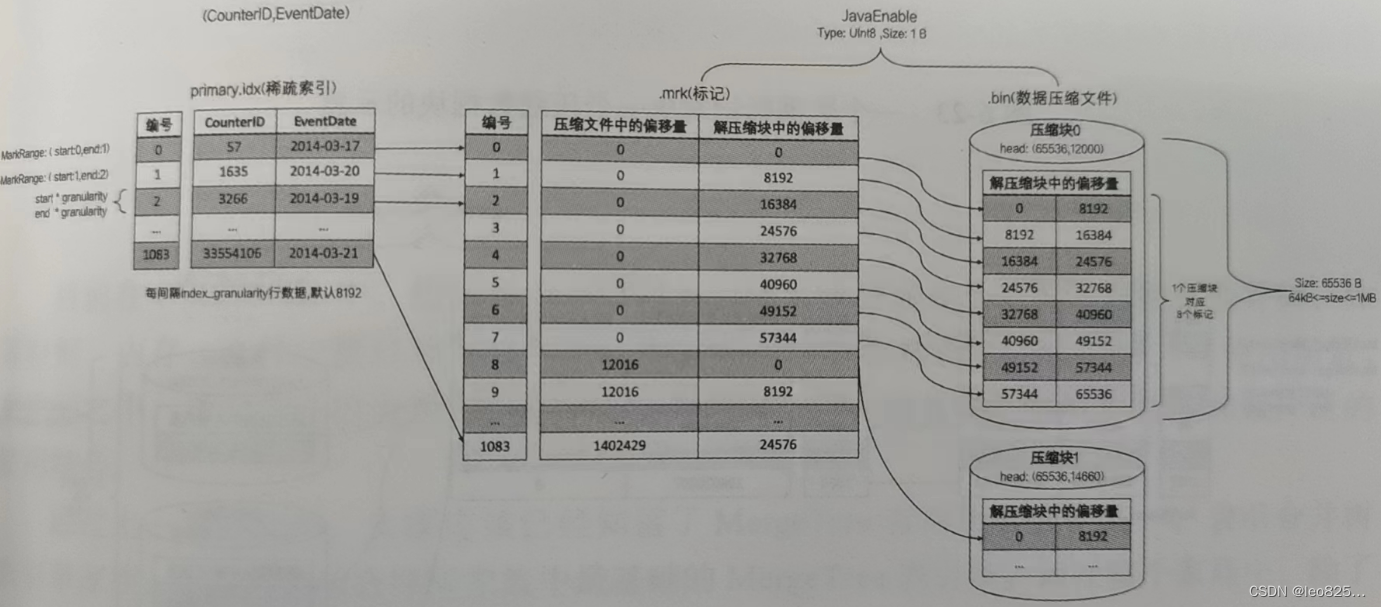
上面的例子是拿(CounterID+EventDate)作为主键生成的索引。
4.3、索引查询
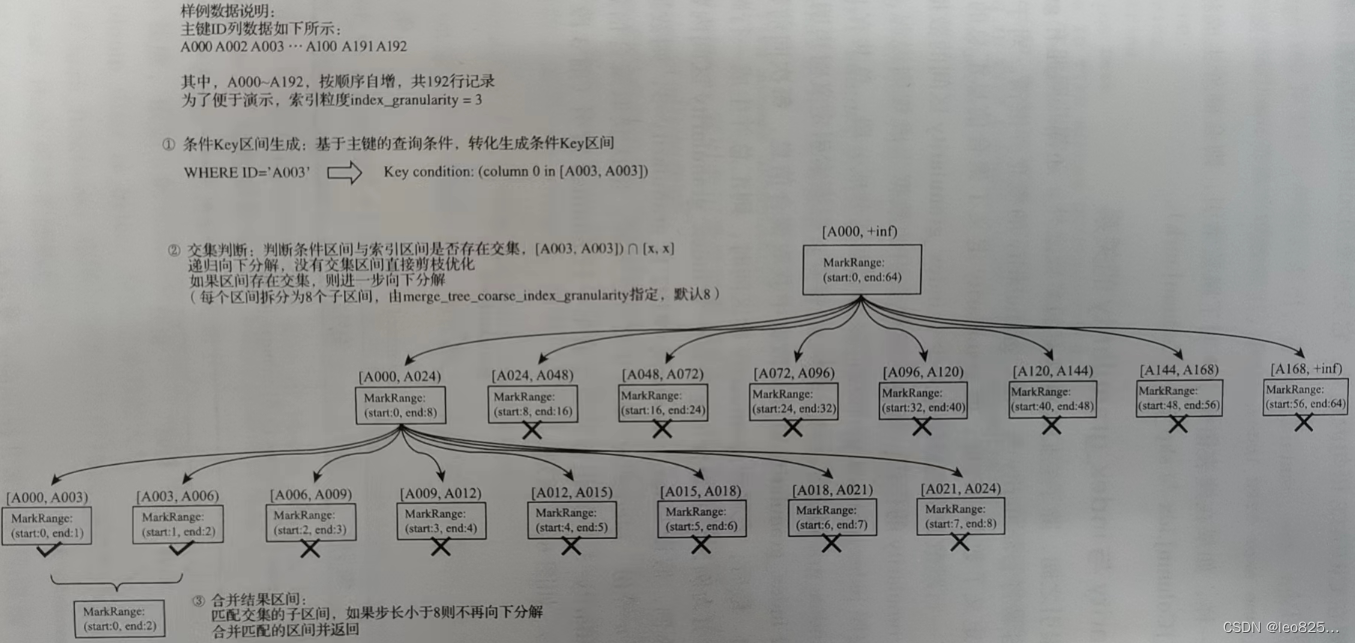
(1)生成查询条件区间:首先,将查询条件转换为条件区间。一个具体的数据段是一个 MarkRange,划分依据是间隔(默认8192)
(2)递归交际判断:以递归的形式,依次对 MarkRange 的数据区间与条件区间做交集判断。
(3)合并 MarkRange 区间:将最终匹配的 MarkRange 聚合在一起,合并它们的范围。
5、二级索引
MergeTree 支持二级索引,二级索引又称跳数索引,由数据的聚合信息构建而成,目的也是帮助查询减少数据的扫描范围。
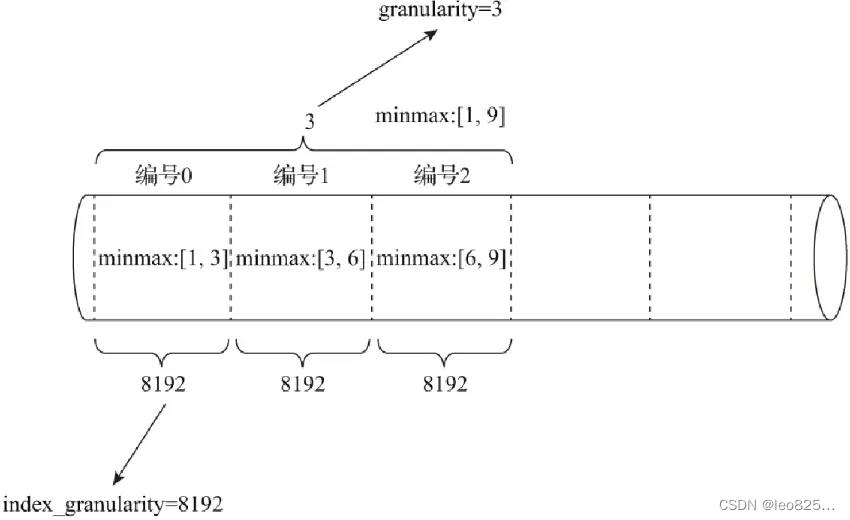
index_granularity:按照设置的粒度值的大小将数据分成 n 段,总共有 [0, n-1] 个区间(n=total_rows/index_granularity)。
granularity:定义了一行跳数索引能够跳过多少个 index_granularity 区间的数据。
6、数据存储
- 数据按列存储,具体到每一列数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件;
- 数据写入之前是经过压缩的,目前支持 LZ4、ZSTD、Multiple 和 Delta 几种算法,默认使用 LZ4 算法;
- 数据会事先依照 ORDER BY 的声明排序,最后以压缩数据块的形式被组织并写入 .bin 文件中。
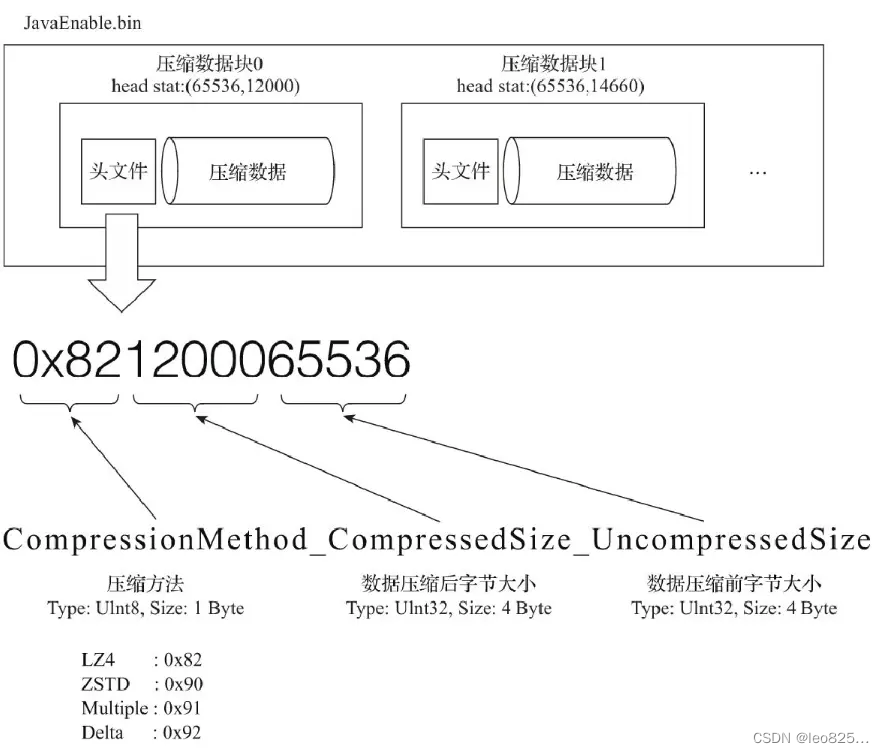
压缩数据块示意图:
MergeTree 在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取 8192 行),按批次获取数据并处理。如果把一批数据的未压缩大小设置为 size,切割过程则如下图所示。
切割压缩数据块的逻辑示意图:
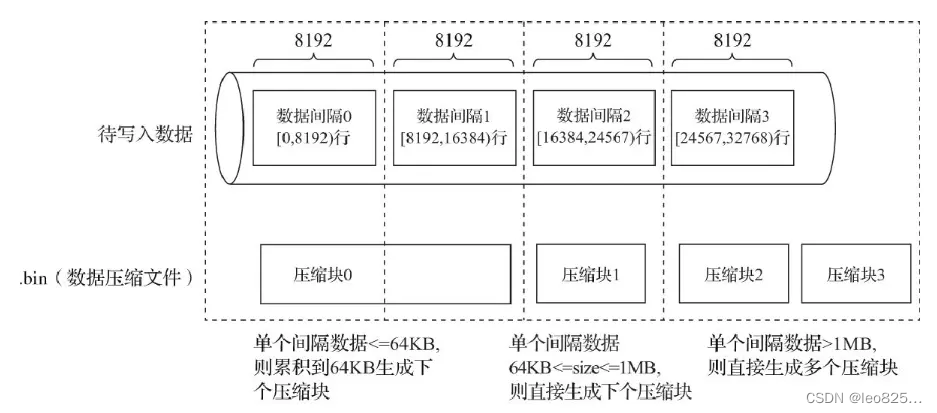
在 .bin 文件中引入压缩数据块的目的:
(1) 数据压缩后可以有效减少数据大小,但是数据压缩解压会带来性能损耗,控制压缩数据的大小以求在性能损耗和压缩率之间寻求一种平衡
(2)读取数据文件的时候可以不用读取整个 .bin 文件,缩小数据读取的范围。
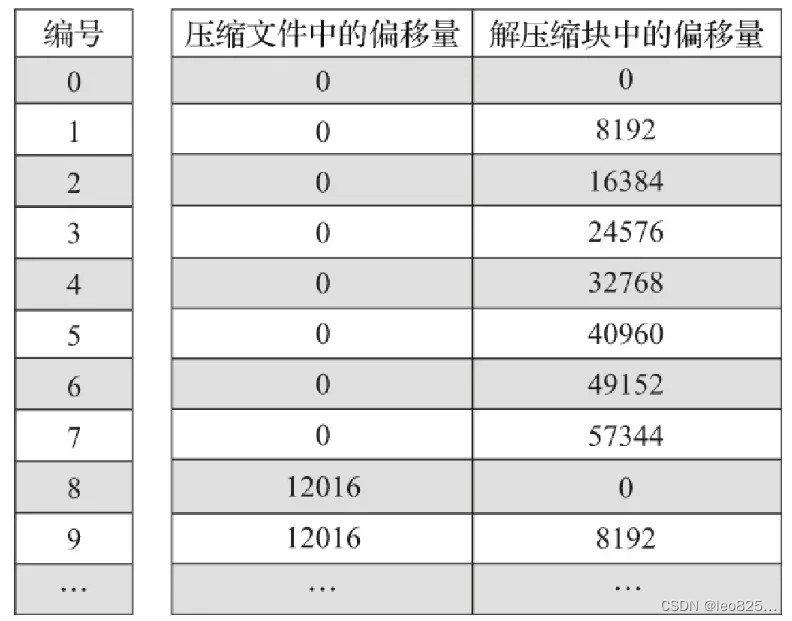
7、数据标记
- 数据标记根据便宜读取赌赢的压缩数据块
- 以 index_granularity 粒度加载特定的一小段
(1)通过索引下标编号找到对应的数据标记:

(2)标记数据示意图
(3)JavaEnable 字段的标记文件和压缩文件的对应关系:
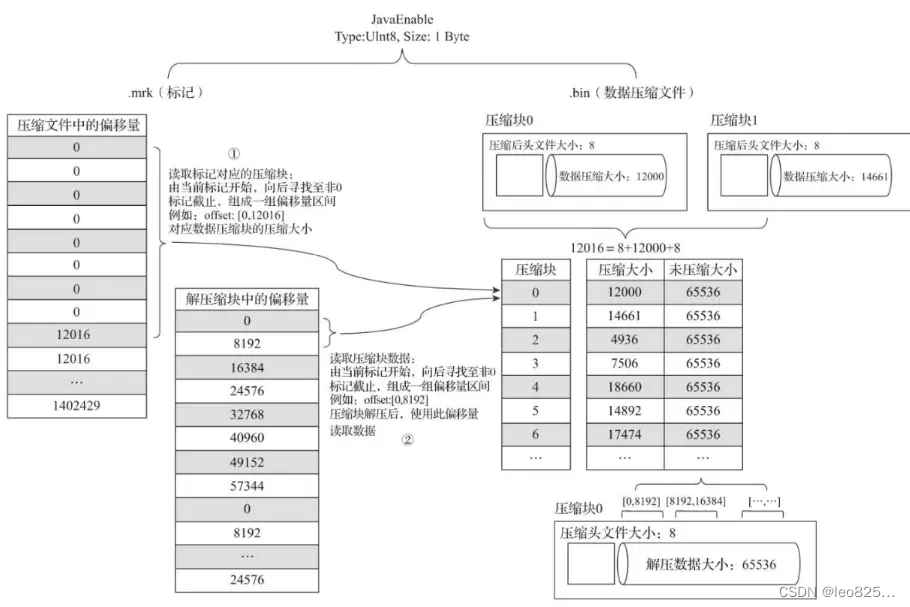
提问:在 .mrk 文件中,第 0 个压缩数据块的截止偏移量是 12016 ,在 .bin 数据文件中第 0 个压缩数据块的压缩大小是 12000 为什么不一样呢?
答:一个完整的是压缩数据块是由头信息加上压缩数据组成的,它的头信息由 9 个字节组成,压缩后大小是 8 个字节。所以,8 + 12000 + 8 = 12016。
8、协同总结
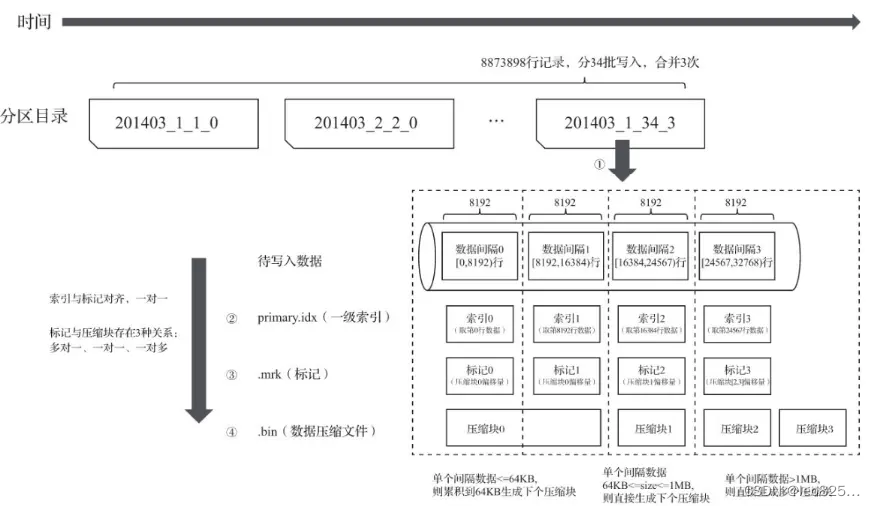
8.1、写入过程
(1)生成分区目录,写入第一批数据;
(2)相同分区的目录依照规则合并到一起;
(3)按照 index_granularity 索引粒度生成 primary.idx 一级索引、二级索引、每一列的 .mrk 数据标记、.bin压缩文件。
分区目录、索引、标记和压缩数据的生成过程示意图:
8.2、查询过程
(1)依次借助分区索引、一级索引、二级索引,将数据扫描范围缩至最小;
(2)借助数据标记将需要解压与计算的数据范围缩小至最小;
将扫描数据范围最小化的过程:
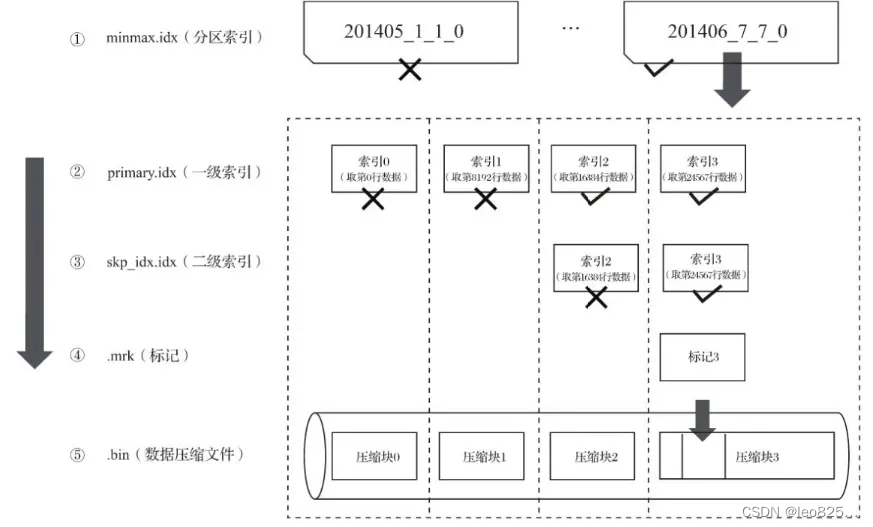
8.3、数据标记与压缩块对应关系
- 多对一、一对一关系比较好理解
- 一个标记对应多个压缩块(一对多),说明 index_granualarity 间隔的数据很大。
多个数据标记对应同一个压缩块的示意图:















 5075
5075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











