







一 Flink概念
1.1 Flink的概念
Flink是一个框架和分布式处理引擎,用于对无界和有解数据流进行状态计算。Flink 是一个分布式的流处理框架, DataSet API 可以很容易地实现批处理;与之对应,流处理当然可以用 DataStream API 来实现。
如下图所示:
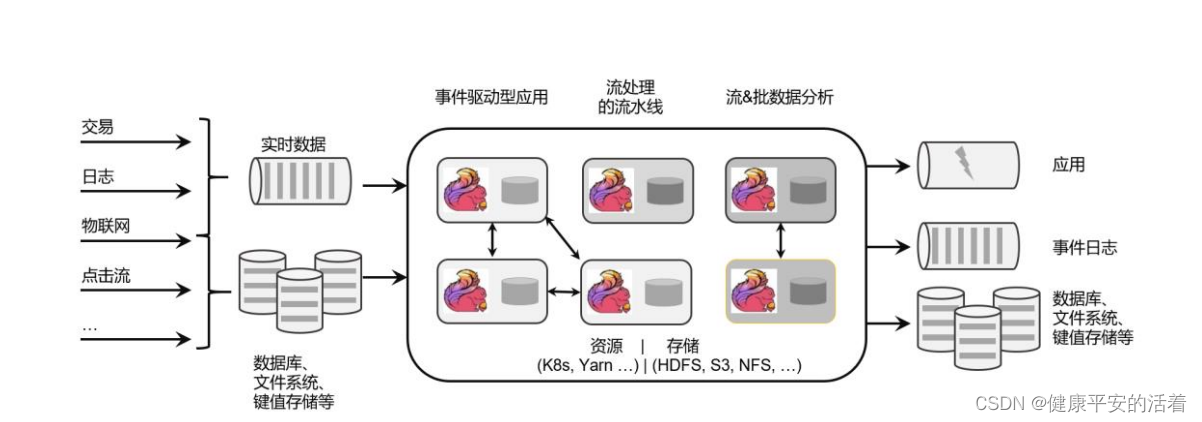
1.2 Flink的应用场景
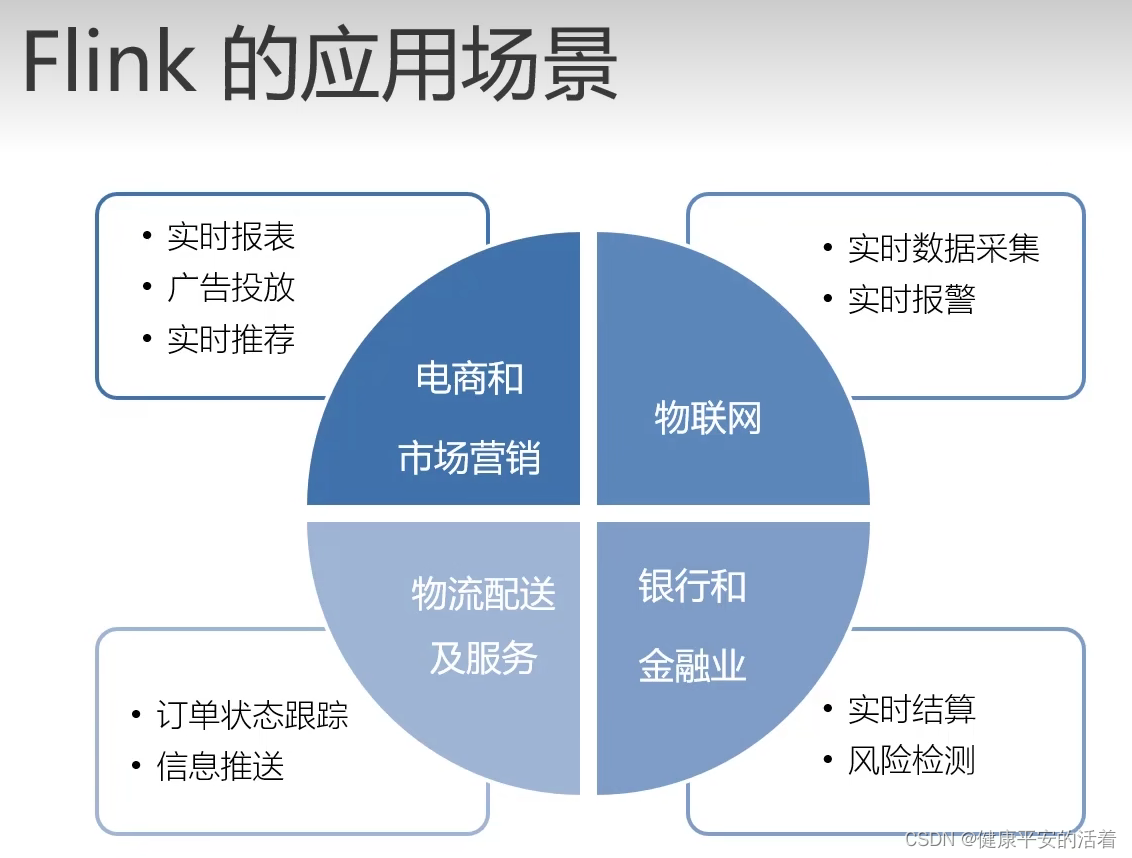
1.3 Flink的目标
1.高吞吐量 2.低延迟 3,结果的准确性和良好的容错性。
1.4 Flink与spark的区别联系
Spark
和
Flink
可以说目前是各擅胜场,批处理领 域 Spark
称王,而在流处理方面
Flink
当仁不让。
1.数据模型上,sprak采用RDD模型,spark streaming的Dstream实际上就是一组组小批数据RDD的集合。
2.flink的基本数据类型是数据流。
工作中需要从
Spark
和
Flink
这两个主流框架中选择一个来进行实时流处理,我们
更加推荐使用
Flink
,主要的原因有:
⚫
Flink
的延迟是毫秒级别,而
Spark Streaming
的延迟是秒级延迟。
⚫
Flink
提供了严格的精确一次性语义保证。
⚫
Flink
的窗口
API
更加灵活、语义更丰富。
⚫
Flink
提供事件时间语义,可以正确处理延迟数据。
⚫
Flink
提供了更加灵活的对状态编程的
API
1.5 Flink的组件
客户端(
Client) 是提供任务需求给JobManager。
JObManager 是任务集中管理调度。
TaskManager是执行处理具体任务。















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









