







一、简介
1、MapReduce 应用广泛的原因之一在于它的易用性。它提供了一个因高度抽象化而变得异常简单的编程模型。
2、从MapReduce 自身的命名特点可以看出,MapReduce 由两个阶段组成:Map 和Reduce 。用户只需编写map( ) 和reduce( ) 两个函数,即可完成简单的分布式程序的设计。
1)map ( ) 函数以key/value 对作为输入,产生另外一系列key/value 对作为中间输出写入本地磁盘。MapReduce 框架会自动将这些中间数据按照k e y 值进行聚集,且k e y 值相同(用户可设定聚集策略,默认情况下是对k e y 值进行哈希取模)的数据被统一交给reduce( ) 函数处理。
2)reduce( ) 函数以k e y 及对应的v a l u e 列表作为输入,经合并k e y 相同的v a l u e 值后,产生另外一系列key/value 对作为最终输出写入H D F S 。
二、实例
下面以MapReduce 中的“hello world ”程序—Word Count 为例介绍程序设计方法。
其中M a p 部分如下:
// key:字符串偏移量
// value: 一行字符串内容
map(String key, String value) :
// 将字符串分割成单词
words = SplitIntoTokens(value);
for each word w in words:
EmitIntermediate(w, "1");
R e d u c e 部分如下:
// key:一个单词
// values:该单词出现的次数列表
reduce(String key, Iterator values):
int result = 0;
for each v in values:
result += StringToInt(v);
Emit(key, IntToString(result));
PS
1、用户编写完MapReduce 程序后,按照一定的规则指定程序的输入和输出目录,并提交到Hadoop 集群中。作业在Hadoop 中的执行过程如图1所示。Hadoop 将输入数据切分
成若干个输入分片(input split ,后面简称split ),并将每个split 交给一个Map Task 处理;Map Task 不断地从对应的split 中解析出一个个key/value ,并调用m a p ( ) 函数处理,处理完
之后根据Reduce Task 个数将结果分成若干个分片(partition )写到本地磁盘;同时,每个Reduce Ta s k 从每个M a p Ta s k 上读取属于自己的那个partition ,然后使用基于排序的方法将
key 相同的数据聚集在一起,调用Reduce ( ) 函数处理,并将结果输出到文件中。
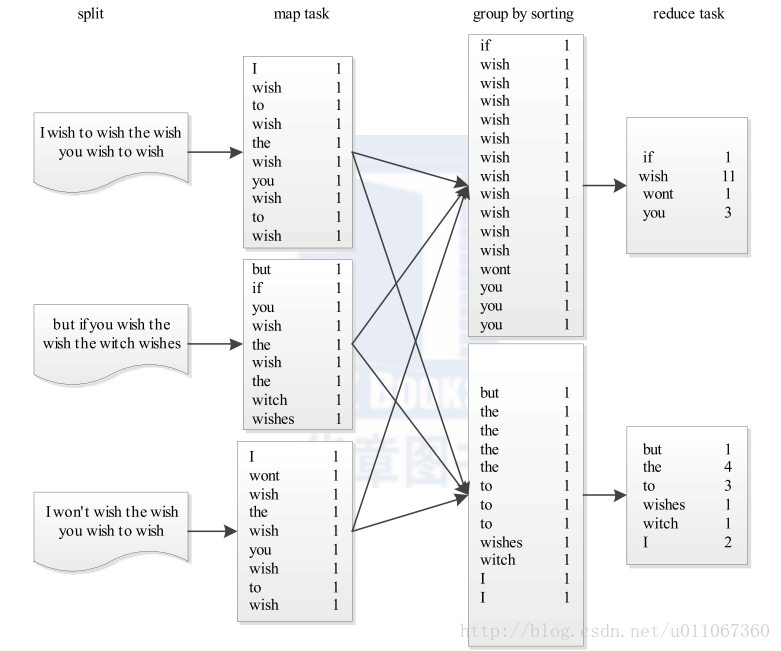
图1 Word Count 程序运行过程
2、上面的程序还缺少三个基本的组件,功能分别是:
①指定输入文件格式。将输入数据切分成若干个s p l i t ,且将每个s p l i t 中的数据解析成一个个m a p ( ) 函数要求的k e y / v a l u e 对。
②确定m a p ( ) 函数产生的每个k e y / v a l u e 对发给哪个R e d u c e Ta s k 函数处理。
③指定输出文件格式,即每个k e y / v a l u e 对以何种形式保存到输出文件中。
在Hadoop MapReduce 中,这三个组件分别是InputFormat 、Partitioner 和OutputFormat ,它们均需要用户根据自己的应用需求配置。而对于上面的Wo r d C o u n t 例子,默认情况下Hadoop 采用的默认实现正好可以满足要求,因而不必再提供。
综上所述,Hadoop MapReduce 对外提供了5 个可编程组件,分别是InputFormat 、M a p p e r 、Partitioner 、Reducer 和OutputFormat 。
三、Hadoop MapReduce 作业的生命周期
本节主要讲解Hadoop MapReduce 作业的生命周期,即作业从提交到运行结束经历的整个过程。本节只是概要性地介绍MapReduce 作业的生命周期;
假设用户编写了一个MapReduce 程序,并将其打包成x x x . j a r 文件,然后使用以下命
令提交作业:
$HADOOP_HOME/bin/hadoop jar xxx.jar \
-D mapred.job.name="xxx" \
-D mapred.map.tasks=3 \
-D mapred.reduce.tasks=2 \
-D input=/test/input \
-D output=/test/output
则该作业的运行过程如图2所示。
这个过程分为以下5 个步骤:
步骤1 作业提交与初始化。用户提交作业后,首先由JobClient 实例将作业相关信息,比如将程序jar 包、作业配置文件、分片元信息文件等上传到分布式文件系统(一般为H D F S )上,其中,分片元信息文件记录了每个输入分片的逻辑位置信息。然后JobClient通过R P C 通知JobTracker 。JobTracker 收到新作业提交请求后,由作业调度模块对作业进行初始化:为作业创建一个J o b I n P r o g r e s s 对象以跟踪作业运行状况,而J o b I n P r o g r e s s 则会为每个Ta s k 创建一个TaskInProgress 对象以跟踪每个任务的运行状态,TaskInProgress 可能需要管理多个“Ta s k 运行尝试”(称为“Ta s k A t t e m p t ”)。
步骤2 任务调度与监控。前面提到,任务调度和监控的功能均由JobTracker 完成。TaskTracker 周期性地通过H e a r t b e a t 向JobTracker 汇报本节点的资源使用情况,一旦出现
空闲资源,JobTracker 会按照一定的策略选择一个合适的任务使用该空闲资源,这由任务调度器完成。任务调度器是一个可插拔的独立模块,且为双层架构,即首先选择作业,然后
从该作业中选择任务,其中,选择任务时需要重点考虑数据本地性。此外,JobTracker 跟踪作业的整个运行过程,并为作业的成功运行提供全方位的保障。首先,当TaskTracker 或者Ta s k 失败时,转移计算任务;其次,当某个Ta s k 执行进度远落后于同一作业的其他Ta s k 时,为之启动一个相同Ta s k ,并选取计算快的Ta s k 结果作为最终结果。
步骤3 任务运行环境准备。运行环境准备包括J V M 启动和资源隔离,均由TaskTracker 实现。TaskTracker 为每个Ta s k 启动一个独立的J V M 以避免不同Ta s k 在运行过程中相互影响;同时,TaskTracker 使用了操作系统进程实现资源隔离以防止Ta s k 滥用资源。
步骤4 任务执行。TaskTracker 为Ta s k 准备好运行环境后,便会启动Ta s k 。在运行过程中,每个Ta s k 的最新进度首先由Ta s k 通过R P C 汇报给TaskTracker ,再由TaskTracker汇报给JobTracker 。
步骤5 作业完成。待所有Ta s k 执行完毕后,整个作业执行成功。
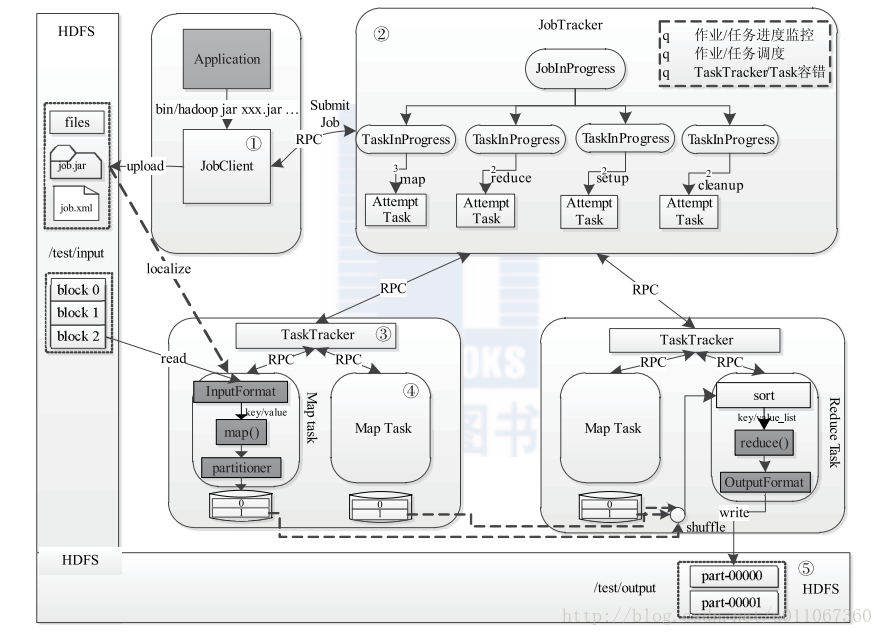
图2 Hadoop MapReduce 作业的生命周期
四、MapReduce 编程模型的实现
1、MapReduce 编程模型给出了其分布式编程方法,共分5 个步骤:
1 )迭代(iteration )。遍历输入数据,并将之解析成key/value 对。
2 )将输入key/value 对映射(m a p )成另外一些key/value 对。
3 )依据k e y 对中间数据进行分组(grouping )。
4 )以组为单位对数据进行归约(reduce )。
5 )迭代。将最终产生的key/value 对保存到输出文件中。
MapReduce 将计算过程分解成以上5 个步骤带来的最大好处是组件化与并行化。为了实现MapReduce 编程模型,Hadoop 设计了一系列对外编程接口。用户可通过实现这些接口完成应用程序的开发。
2、MapReduce 编程接口体系结构
MapReduce 编程模型对外提供的编程接口体系结构如图3 所示,整个编程模型位于应用程序层和MapReduce 执行器之间,可以分为两层。第一层是最基本的J a v a A P I ,主要有5 个可编程组件,分别是InputFormat 、Mapper 、Partitioner 、Reduce r 和OutputFormat 。
Hadoop 自带了很多直接可用的InputFormat 、Partitioner 和OutputFormat ,大部分情况下,用户只需编写Mapper 和Reducer 即可。第二层是工具层,位于基本J a v a A P I 之上,主要是为了方便用户编写复杂的MapReduce 程序和利用其他编程语言增加MapReduce 计算平台的兼容性而提出来的。在该层中,主要提供了4 个编程工具包。
J o b C o n t r o l :方便用户编写有依赖关系的作业,这些作业往往构成一个有向图,所以 通常称为DAG (Directed Acyclic Graph )作业,如第2 章中的朴素贝叶斯分类算法实现便是4 个有依赖关系的作业构成的DAG 。
C h a i n Mapper / Chain Reduce r :方便用户编写链式作业,即在M a p 或者Reduce 阶段存在多个Mapper ,形式如下:
[MAPPER+ REDUCER MAPPER*]
Hadoop Streaming :方便用户采用非J a v a 语言编写作业,允许用户指定可执行文件或者脚本作为Mapper / Reduce r 。
Hadoop Pipes :专门为C / C + + 程序员编写MapReduce 程序提供的工具包。
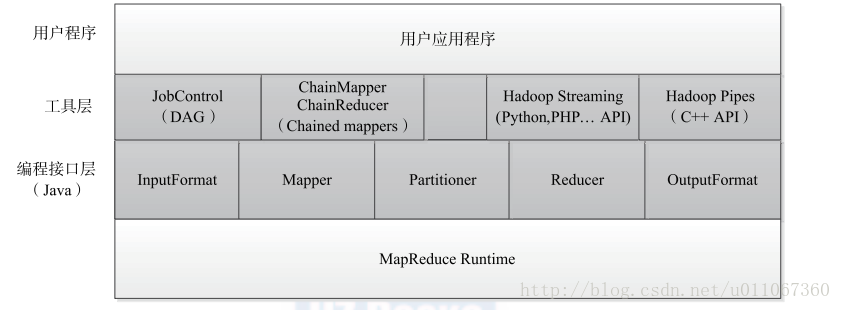
图3 MapReduce 编程接口体系结构
五、小结:
1、Hadoop MapReduce 直接诞生于搜索领域,以易于编程、良好的扩展性和高容错性为设计目标。它主要由两部分组成:编程模型和运行时环境。其中,编程模型为用户提供了5
个可编程组件,分别是InputFormat 、Mapper 、Partitioner 、Reduce r 和OutputFormat ;运行时环境则将用户的MapReduce 程序部署到集群的各个节点上,并通过各种机制保证其成功
运行。
2、Hadoop MapReduce 处理的数据一般位于底层分布式文件系统中。该系统往往将用户的文件切分成若干个固定大小的block 存储到不同节点上。默认情况下,MapReduce 的每
个Task 处理一个block 。 MapReduce 主要由四个组件构成,分别是C l i e n t 、JobTracker 、TaskTracker 和Ta s k ,它们共同保障一个作业的成功运行。一个MapReduce 作业的运行周期是,先在C l i e n t 端被提交JobTracker 上,然后由JobTracker 将作业分解成若干个Ta s k ,并对这些Ta s k 进行调度和监控,以保障这些程序运行成功,而TaskTracker 则启动JobTracker 发来的Ta s k ,并向JobTracker 汇报这些Task 的运行状态和本节点上资源的使用情况。















 2575
2575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









