









KNN算法基础思想前面文章可以参考,这里主要讲解java和python的两种简单实现,也主要是理解简单的思想。
http://blog.csdn.net/u011067360/article/details/23941577
python版本:
这里实现一个手写识别算法,这里只简单识别0~9熟悉,在上篇文章中也展示了手写识别的应用,可以参考:机器学习与数据挖掘-logistic回归及手写识别实例的实现
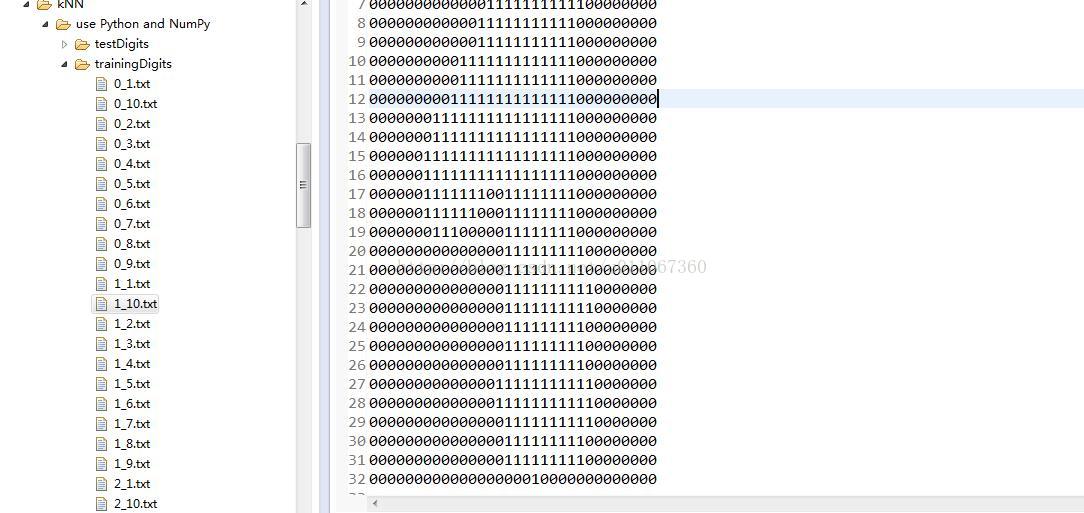
输入:每个手写数字已经事先处理成32*32的二进制文本,存储为txt文件。0~9每个数字都有10个训练样本,5个测试样本。训练样本集如下图:左边是文件目录,右边是其中一个文件打开显示的结果,看着像1,这里有0~9,每个数字都有是个样本来作为训练集。
第一步:将每个txt文本转化为一个向量,即32*32的数组转化为1*1024的数组,这个1*1024的数组用机器学习的术语来说就是特征向量。
<span style="font-size:14px;">def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect</span>第二步:训练样本中有10*10个图片,可以合并成一个100*1024的矩阵,每一行对应一个图片,也就是一个txt文档。
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
print trainingFileList
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#print hwLabels
#print fileNameStr
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#print trainingMat[i,:]
#print len(trainingMat[i,:])
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))第三步:测试样本中有10*5个图片,同样的,对于测试图片,将其转化为1*1024的向量,然后计算它与训练样本中各个图片的“距离”(这里两个向量的距离采用欧式距离),然后对距离排序,选出较小的前k个,因为这k个样本来自训练集,是已知其代表的数字的,所以被测试图片所代表的数字就可以确定为这k个中出现次数最多的那个数字。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
#-*-coding:utf-8-*-
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
print trainingFileList
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#print hwLabels
#print fileNameStr
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#print trainingMat[i,:]
#print len(trainingMat[i,:])
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
handwritingClassTest()
运行结果:源码文章尾可下载
java版本
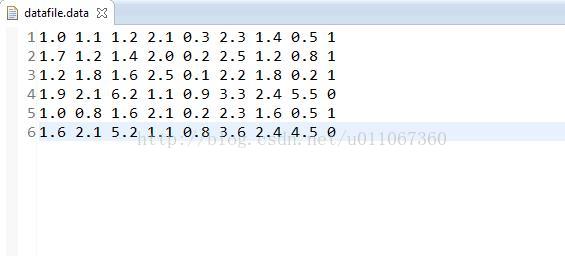
先看看训练集和测试集:
训练集:
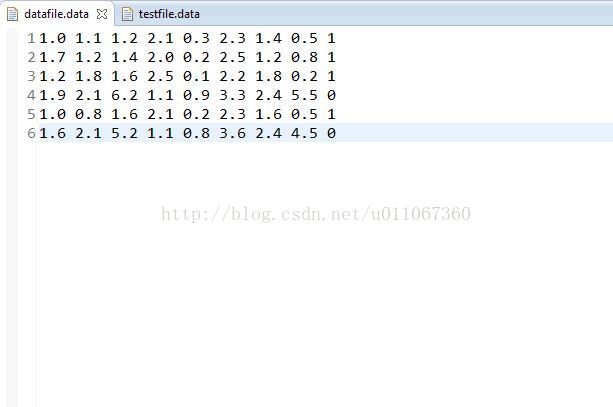
测试集:
训练集最后一列代表分类(0或者1)
代码实现:
KNN算法主体类:
package Marchinglearning.knn2;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
/**
* KNN算法主体类
*/
public class KNN {
/**
* 设置优先级队列的比较函数,距离越大,优先级越高
*/
private Comparator<KNNNode> comparator = new Comparator<KNNNode>() {
public int compare(KNNNode o1, KNNNode o2) {
if (o1.getDistance() >= o2.getDistance()) {
return 1;
} else {
return 0;
}
}
};
/**
* 获取K个不同的随机数
* @param k 随机数的个数
* @param max 随机数最大的范围
* @return 生成的随机数数组
*/
public List<Integer> getRandKNum(int k, int max) {
List<Integer> rand = new ArrayList<Integer>(k);
for (int i = 0; i < k; i++) {
int temp = (int) (Math.random() * max);
if (!rand.contains(temp)) {
rand.add(temp);
} else {
i--;
}
}
return rand;
}
/**
* 计算测试元组与训练元组之前的距离
* @param d1 测试元组
* @param d2 训练元组
* @return 距离值
*/
public double calDistance(List<Double> d1, List<Double> d2) {
System.out.println("d1:"+d1+",d2"+d2);
double distance = 0.00;
for (int i = 0; i < d1.size(); i++) {
distance += (d1.get(i) - d2.get(i)) * (d1.get(i) - d2.get(i));
}
return distance;
}
/**
* 执行KNN算法,获取测试元组的类别
* @param datas 训练数据集
* @param testData 测试元组
* @param k 设定的K值
* @return 测试元组的类别
*/
public String knn(List<List<Double>> datas, List<Double> testData, int k) {
PriorityQueue<KNNNode> pq = new PriorityQueue<KNNNode>(k, comparator);
List<Integer> randNum = getRandKNum(k, datas.size());
System.out.println("randNum:"+randNum.toString());
for (int i = 0; i < k; i++) {
int index = randNum.get(i);
List<Double> currData = datas.get(index);
String c = currData.get(currData.size() - 1).toString();
System.out.println("currData:"+currData+",c:"+c+",testData"+testData);
//计算测试元组与训练元组之前的距离
KNNNode node = new KNNNode(index, calDistance(testData, currData), c);
pq.add(node);
}
for (int i = 0; i < datas.size(); i++) {
List<Double> t = datas.get(i);
System.out.println("testData:"+testData);
System.out.println("t:"+t);
double distance = calDistance(testData, t);
System.out.println("distance:"+distance);
KNNNode top = pq.peek();
if (top.getDistance() > distance) {
pq.remove();
pq.add(new KNNNode(i, distance, t.get(t.size() - 1).toString()));
}
}
return getMostClass(pq);
}
/**
* 获取所得到的k个最近邻元组的多数类
* @param pq 存储k个最近近邻元组的优先级队列
* @return 多数类的名称
*/
private String getMostClass(PriorityQueue<KNNNode> pq) {
Map<String, Integer> classCount = new HashMap<String, Integer>();
for (int i = 0; i < pq.size(); i++) {
KNNNode node = pq.remove();
String c = node.getC();
if (classCount.containsKey(c)) {
classCount.put(c, classCount.get(c) + 1);
} else {
classCount.put(c, 1);
}
}
int maxIndex = -1;
int maxCount = 0;
Object[] classes = classCount.keySet().toArray();
for (int i = 0; i < classes.length; i++) {
if (classCount.get(classes[i]) > maxCount) {
maxIndex = i;
maxCount = classCount.get(classes[i]);
}
}
return classes[maxIndex].toString();
}
}
KNN结点类,用来存储最近邻的k个元组相关的信息
package Marchinglearning.knn2;
/**
* KNN结点类,用来存储最近邻的k个元组相关的信息
*/
public class KNNNode {
private int index; // 元组标号
private double distance; // 与测试元组的距离
private String c; // 所属类别
public KNNNode(int index, double distance, String c) {
super();
this.index = index;
this.distance = distance;
this.c = c;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public double getDistance() {
return distance;
}
public void setDistance(double distance) {
this.distance = distance;
}
public String getC() {
return c;
}
public void setC(String c) {
this.c = c;
}
}
KNN算法测试类
package Marchinglearning.knn2;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
/**
* KNN算法测试类
*/
public class TestKNN {
/**
* 从数据文件中读取数据
* @param datas 存储数据的集合对象
* @param path 数据文件的路径
*/
public void read(List<List<Double>> datas, String path){
try {
BufferedReader br = new BufferedReader(new FileReader(new File(path)));
String data = br.readLine();
List<Double> l = null;
while (data != null) {
String t[] = data.split(" ");
l = new ArrayList<Double>();
for (int i = 0; i < t.length; i++) {
l.add(Double.parseDouble(t[i]));
}
datas.add(l);
data = br.readLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 程序执行入口
* @param args
*/
public static void main(String[] args) {
TestKNN t = new TestKNN();
String datafile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator + "datafile.data";
String testfile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator +"testfile.data";
System.out.println("datafile:"+datafile);
System.out.println("testfile:"+testfile);
try {
List<List<Double>> datas = new ArrayList<List<Double>>();
List<List<Double>> testDatas = new ArrayList<List<Double>>();
t.read(datas, datafile);
t.read(testDatas, testfile);
KNN knn = new KNN();
for (int i = 0; i < testDatas.size(); i++) {
List<Double> test = testDatas.get(i);
System.out.print("测试元组: ");
for (int j = 0; j < test.size(); j++) {
System.out.print(test.get(j) + " ");
}
System.out.print("类别为: ");
System.out.println(Math.round(Float.parseFloat((knn.knn(datas, test, 3)))));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
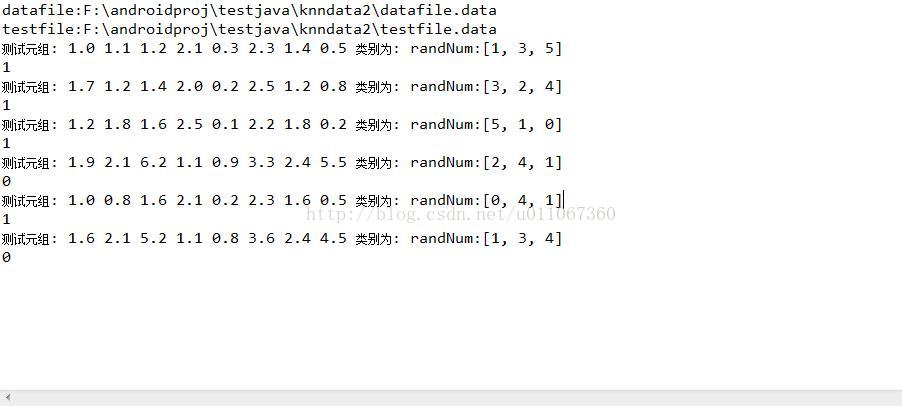
运行结果为:
资源下载:















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









