







Redis解决数据一致性方案
背景
我们在日常碰到高并发的的场景或者是一些读多写少场景的时候,我们可以使用缓存来提升查询速度。当我们使用Redis来做缓存的时候大概流程如下图:
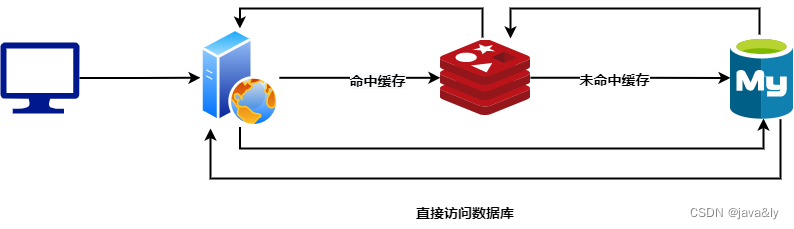
大部分用缓存的场景基本上都符合2-8定律,所以这些数据很少被修改的所以在大部分情况下都会命中缓存。一旦缓存数据发生变化的时候,我们既要更新数据库又要更新Redis缓存,那么就会引发新的问题:
- 先操作Redis,再操作数据库;
- 先操作数据库,再操作Redis;
方案选择
选择思路
首先我们的目标是数据最终一致性,不管选择哪个方案都希望的结果是要么全部成功,要么全部失败。否则,就会引发Redis缓存跟数据库不一致的问题。
其次,现实问题就是Redis和数据库不可能通过事物来解决。
最后,根据我们的目标和客观事实就要去衡量,通过一些其他的方式代价来降低数据不一致的问题出现的概率,在数据一致性和性能之间权衡。
例如:我们对数据库的实时性要求不是特别高的场景,可以采用定时任务查询并同步到Redis的方案。或者给缓存设置一个过期时间等。
Redis缓存是删除还是更新
当我们需要对Rdis缓存进行操作的时候,会有两种方案:
- 直接更新,调用Redis
set;- 简单直接,一般情况下我们也会推荐使用此方案。
- 直接删除缓存,下次应用在调用的时候直接查询数据库,并写入缓存;
- 我们要衡量下复杂度,判断是否需要经过连表查询、接口调用、计算等场景才能得到最新的数据。而不是直接从数据库拿到的值。
最后
当我们确认上面的问题后,此时解决Redis缓存和数据库一致性问题就剩下两个问题:
- 先更新数据库,再删除缓存;
- 先删除缓存,再更新数据库;
先更新数据库,再删除缓存
正常
更新数据库成功---->成功---->删除缓存---->成功
异常
- 更新数据库失败,这里不会走到删除缓存,所以不会出现程序不一致;
- 更新数据库成功,删除Redis缓存失败。此时,数据库是新数据,缓存是旧数据,引发了数据不一致。
怎么解决?
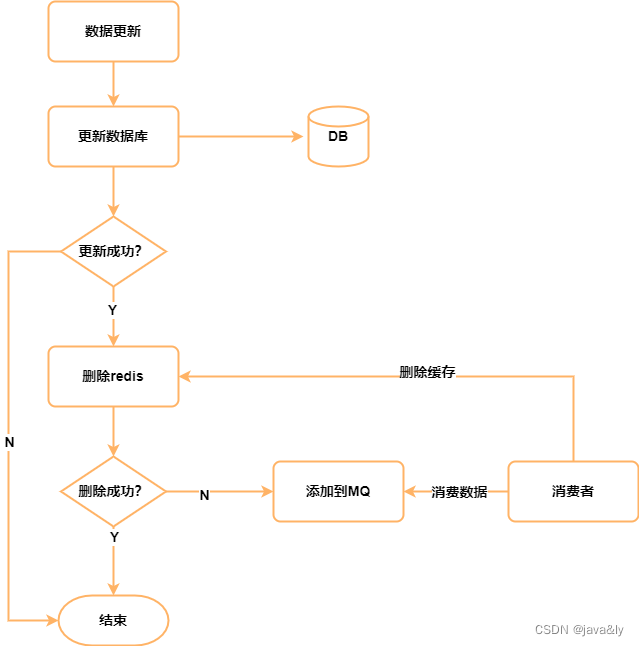
重试机制
原理: 当我们删除缓存失败时捕获这个异常,并且把这个删除的key发送到消息队列中。然后自己创建一个消费者去尝试再次删除这个key。
如下图:
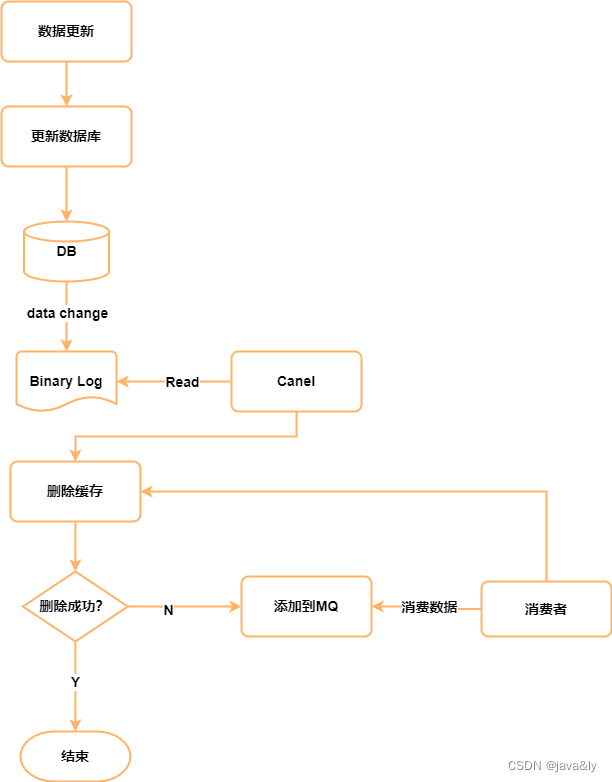
异步更新缓存
原理: 更新数据库时binlog会写入日志,所以我们可以通过一个服务(阿里canal)来监听binlog的变化,然后在客户端完成删除key的操作。如果删除失败的话再发送到消息队列中。
总结
目标就是通过重试机制来解决后删除缓存失败的情况,直到删除成功。无论是重试还是异步删除,都是最终一致性的思想。
先删除缓存,再更新数据库
正常
删除缓存---->成功---->更新数据库---->成功
异常
- 删除缓存异常,程序捕获,此时不会走到下一步,所以数据一致
- 删除缓存成功,更新数据库失败。此时,以数据库的数据为准,所以不存在数据不一致的情况。
以上情况看似没有问题,但是并发就会暴露:
- 线程1,更新数据,先删除了Redis缓存;
- 线程2,查询数据,发现缓存不存在,直接查询数据库得到旧值并且又写入到了Redis返回;
- 线程1,更新了数据库。
此时,Redis是旧的值,数据库是新的值。发生了数据不一致的情况。
怎么解决?
真遇到这种情况就比较难搞了,只有针对同一条数据进行串行化访问,才能解决这个问题,但是这种实现起来对性能影响比较大。所以,我们一般情况下不会采用这种做法。
备注:个人感觉 延迟双删策略 不适合在业务开发中使用,所以这里不再进行描述。
总结
我们在使用Redis缓存时,优先选择先更新数据库,再删除缓存并且同步设置key的过期时间。
在一些对数据一致性要求比较强的业务中,适当的借助MQ或者Canel来做重试。















 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









