XML示例
<?xml version = "1.0" encoding = "UTF-8"?>
<bookstore>
<books>
<book id ="1">
<name>解忧杂货店</name>
<year>2016</year>
<price>27</price>
</book>
<book id ="2">
<name>罗生门</name>
<author>日本人</author>
</book>
</books>
</bookstore>
四种解析方式比较
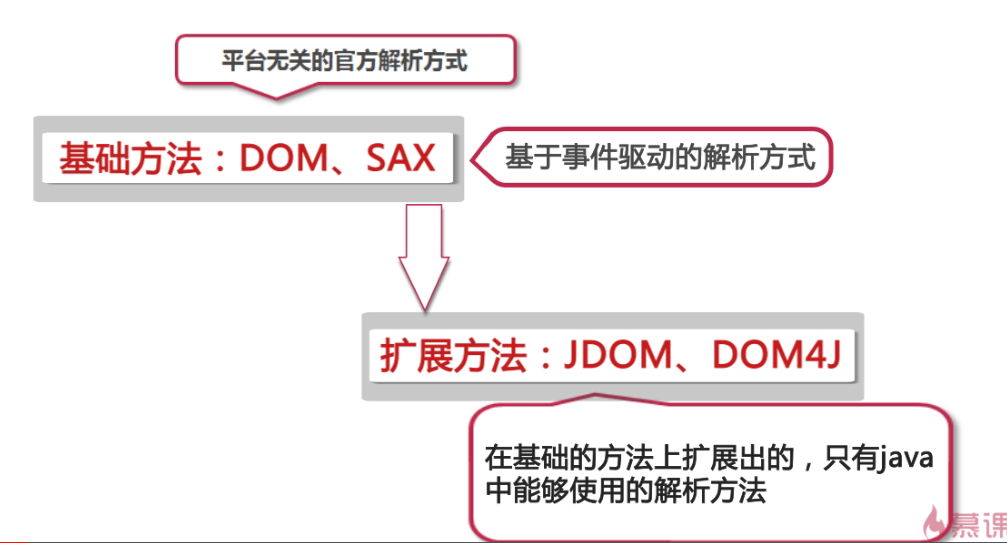
DOM
SAX
1. DOM方式解析XML
3中节点类型
- 三种节点类型以及静态方法返回值
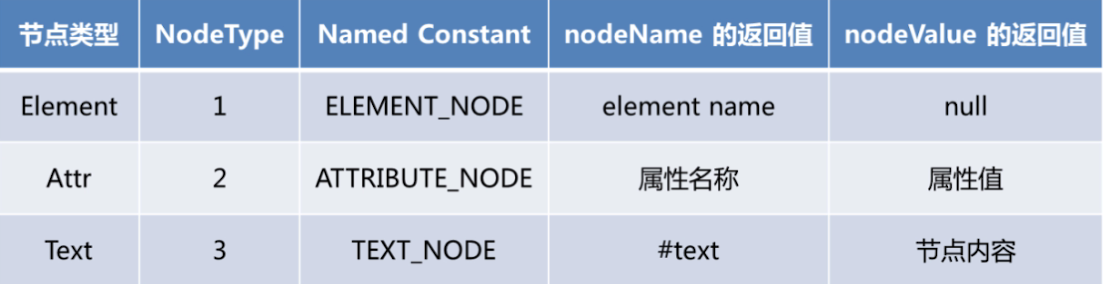
DOM解析示例
public static void parse() throws ParserConfigurationException, SAXException, IOException {
// DOM解析xml文件
// 创建工厂模式对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance()
// 通过DocumentBuilderFactory对象dbf创建
DocumentBuilder db = dbf.newDocumentBuilder()
// 通过DocumentBuilder对象db解析xml文件,返回Document类型文件
Document docu = db.parse("books.xml")
// 从docu对象中获取以关键字索取的节点元素
NodeList booklist = docu.getElementsByTagName("book")
for (int i = 0
System.out.println("-----第" + i + "书------")
org.w3c.dom.Node book = booklist.item(i)
System.out.println(book.getNodeName())
// System.out.println(book.getNodeValue())
NamedNodeMap bookmap = book.getAttributes()
System.out.print(bookmap.item(0).getNodeName() + ":")
System.out.println(bookmap.item(0).getNodeValue())
NodeList childNode = book.getChildNodes()
System.out.println(childNode.getLength())
for (int j = 0
org.w3c.dom.Node child = childNode.item(j)
System.out.print(child.getNodeName() + ":")
System.out.print(child.getTextContent() + "\t")
}
}
- 方法示例2,未知节点名称。
由于空格与换行处理方法忘记,所以程序不完整待改善。
public static void yiyi() throws ParserConfigurationException, SAXException, IOException {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance()
DocumentBuilder db = dbf.newDocumentBuilder()
Document docu = db.parse("books.xml")
Element element = docu.getDocumentElement()
// Document docu1 = element.getOwnerDocument()
NodeList nodeList = element.getChildNodes()
// System.out.println(nodeList.getLength())
org.w3c.dom.Node node = nodeList.item(1)
NodeList childList = node.getChildNodes()
System.out.println(childList.getLength())
System.out.println(node.getNodeName())
}
2.SAX方式解析XML
public class SAXT {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
SAXParserHandler handler = new SAXParserHandler();
parser.parse("books.xml", handler);
System.out.println(handler.getBookList().size());
}
}
/***
* SAX 解析是按照顺序一步步来的 该类对应重写4个方法就 ,从最后连个方法调用顺序体会解析过程 public void
* startDocument()//开始解析标志 public void endDocument()//结束解析表示 public void
* startElement//开始解析元素 public void characters//检测到一个节点结束就会调用
*/
public class SAXDefaultHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("开始解析===========");
}
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("结束解析==========");
}
@Override
/***
* qName 节点名称
*/
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if (qName.equals("book")) {
System.out.println("解析一本书==========");
} else if (!qName.equals("bookstore")) {
System.out.println("节点名是:" + qName);
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String value = new String(ch, start, length);
if (!value.trim().equals("")) {
System.out.println("节点值是:" + value);
}
}
}
3.JDOM方式解析XML
- 导入外部jar包为了使其跟随工程走,可以先在项目下建立一个文件夹,将jar包存到文件夹下,再通过builder path 加入到工程中来jdom&dom4j包
- 示例
public class jdom {
public static void main(String[] args) throws JDOMException, IOException {
SAXBuilder saxbuilder = new SAXBuilder();
InputStreamReader in = new InputStreamReader(new FileInputStream("books.xml"), "utf-8");
Document docu = saxbuilder.build(in);
org.jdom2.Element rootDocu = docu.getRootElement();
List<org.jdom2.Element> elementList = rootDocu.getChildren();
for (org.jdom2.Element element : elementList) {
System.out.println("=========解析——" + element.getName() + elementList.indexOf(element));
List<org.jdom2.Element> childList = element.getChildren();
for (org.jdom2.Element element2 : childList) {
System.out.print(element2.getName() + ":");
System.out.println(element2.getValue());
}
}
}
4.DOM4J方式解析XML
// 创建SAXReader对象
SAXReader saxreader = new SAXReader()
// 通过read方法解析XML文件
Document docu = saxreader.read("books.xml")
// 通过docu获取xml属性
// 获取根节点元素
Element element = docu.getRootElement()
//通过方法获取元素迭代器
Iterator it = element.elementIterator()
//通过迭代器便利获取每一个子节点元素
while (it.hasNext()) {
Element element2 = (Element) it.next()
List<Attribute> attrs = element2.attributes()
System.out.println("parse:" + element2.getName() + attrs.get(0).getValue() + "=================")
Iterator it2 = element2.elementIterator()
while (it2.hasNext()) {
Element element3 = (Element) it2.next()
System.out.print(element3.getName() + ":")
System.out.println(element3.getText())
}
}
附:参考DOM解析程序
package com.imooc.domtest.test
import java.io.IOException
import javax.xml.parsers.DocumentBuilder
import javax.xml.parsers.DocumentBuilderFactory
import javax.xml.parsers.ParserConfigurationException
import org.w3c.dom.Document
import org.w3c.dom.Element
import org.w3c.dom.NamedNodeMap
import org.w3c.dom.Node
import org.w3c.dom.NodeList
import org.xml.sax.SAXException
public class DOMTest {
public static void main(String[] args) {
// 创建一个DocumentBuilderFactory的对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance()
// 创建一个DocumentBuilder的对象
try {
// 创建DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder()
// 通过DocumentBuilder对象的parser方法加载books.xml文件到当前项目下
Document document = db.parse("books.xml")
// 获取所有book节点的集合
NodeList bookList = document.getElementsByTagName("book")
// 通过nodelist的getLength()方法可以获取bookList的长度
System.out.println("一共有" + bookList.getLength() + "本书")
// 遍历每一个book节点
for (int i = 0
System.out.println("=================下面开始遍历第" + (i + 1) + "本书的内容=================")
// 通过 item(i)方法 获取一个book节点,nodelist的索引值从0开始
Node book = bookList.item(i)
// 获取book节点的所有属性集合
NamedNodeMap attrs = book.getAttributes()
System.out.println("第 " + (i + 1) + "本书共有" + attrs.getLength() + "个属性")
// 遍历book的属性
for (int j = 0
// 通过item(index)方法获取book节点的某一个属性
Node attr = attrs.item(j)
// 获取属性名
System.out.print("属性名:" + attr.getNodeName())
// 获取属性值
System.out.println("--属性值" + attr.getNodeValue())
}
// //前提:已经知道book节点有且只能有1个id属性
// //将book节点进行强制类型转换,转换成Element类型
// Element book = (Element) bookList.item(i)
// //通过getAttribute("id")方法获取属性值
// String attrValue = book.getAttribute("id")
// System.out.println("id属性的属性值为" + attrValue)
// 解析book节点的子节点
NodeList childNodes = book.getChildNodes()
// 遍历childNodes获取每个节点的节点名和节点值
System.out.println("第" + (i + 1) + "本书共有" + childNodes.getLength() + "个子节点")
for (int k = 0
// 区分出text类型的node以及element类型的node
if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) {
// 获取了element类型节点的节点名
System.out.print("第" + (k + 1) + "个节点的节点名:" + childNodes.item(k).getNodeName())
// 获取了element类型节点的节点值
System.out.println("--节点值是:" + childNodes.item(k).getFirstChild().getNodeValue())
// System.out.println("--节点值是:" +
// childNodes.item(k).getTextContent())
}
}
System.out.println("======================结束遍历第" + (i + 1) + "本书的内容=================")
}
} catch (ParserConfigurationException e) {
e.printStackTrace()
} catch (SAXException e) {
e.printStackTrace()
} catch (IOException e) {
e.printStackTrace()
}
}
}























 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









