






最终结果在第三步里
1.准备工作
1.1准备 score表
CREATE TABLE `score` (
`st_id` varchar(4) NOT NULL,
`course_id` varchar(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`score` int NOT NULL,
PRIMARY KEY (`st_id`,`course_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `score` VALUES ('0001', '数学', 40);
INSERT INTO `score` VALUES ('0001', '英语', 80);
INSERT INTO `score` VALUES ('0001', '语文', 30);
INSERT INTO `score` VALUES ('0002', '数学', 60);
INSERT INTO `score` VALUES ('0002', '英语', 80);
INSERT INTO `score` VALUES ('0003', '数学', 80);
INSERT INTO `score` VALUES ('0003', '英语', 77);
INSERT INTO `score` VALUES ('0003', '语文', 80);| st_id | course_id | score |
|---|---|---|
| 0001 | 语文 | 30 |
| 0001 | 数学 | 40 |
| 0001 | 英语 | 80 |
| 0002 | 数学 | 60 |
| 0002 | 英语 | 80 |
| 0003 | 语文 | 80 |
| 0003 | 数学 | 80 |
| 0003 | 英语 | 77 |
2.按课程查询出所有数据,根据分数进行排名
SELECT *,
row_number() over(PARTITION BY course_id ORDER BY score desc) pm
FROM scorerow_number函数根据字段course_id进行分组,在分组内部根据字段score进行排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内的排序是连续且唯一的)
这里我们用到了窗口函数over,窗口函数又名开窗函数,属于分析函数的一种。用于解决复杂报表统计需求的功能强大的函数。窗口函数用于计算基于组(GROUP BY)的某种聚合值,它和聚合函数的不同之处是:窗口函数可以在分组之后的返回多行结果,而聚合函数对于每个组只返回一行。
想深入学习窗口函数的建议去这里看看:https://zhuanlan.zhihu.com/p/514345120
此时得到的结果是
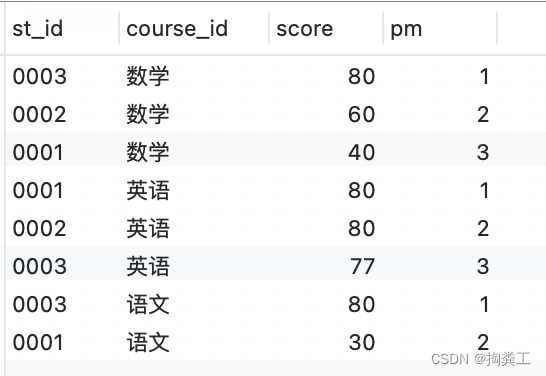
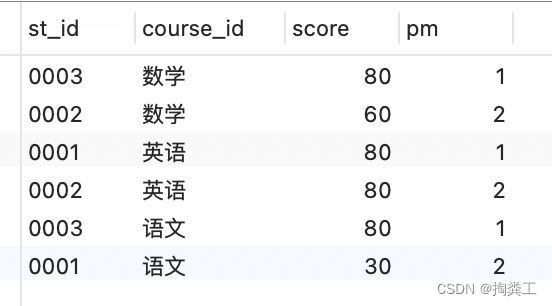
3.以步骤2的查询结果做为子查询的表
select * from (步骤2中的sql) as t where t.pm <3;我是此文章的最终结果
select *
FROM (SELECT *,row_number() over(PARTITION BY course_id ORDER BY score desc) as pm FROM score) AS t
WHERE t.pm<3;查询到的结果
4.进阶
需求:查出每门课的前两名,分数相同的算并列第一,此时英语查询出的应该是3条数据
这里就应该将row_number 换成 dense_rank()
dense_rank函数根据字段course_id进行分组,在分组内部根据字段score进行连续排序,有相同的排名时,相同排名的数据有相同的序号,但是排序序号连续
rank函数根据字段course_id进行分组,在分组内部根据字段score进行跳跃排序,有相同的排名时,相同排名的数据有相同的序号,排序序号不连续;
select *
FROM (SELECT *,dense_rank() over(PARTITION BY course_id ORDER BY score desc) as pm FROM score) AS t
WHERE t.pm<3;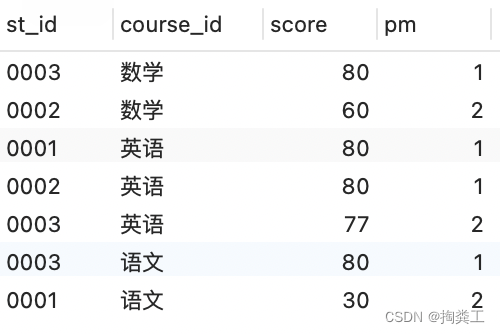















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









