







注明:图片以及相关资料均来自Scalable Machine Learning from BerkelyX,只是个人总结使用,侵权即删
整体框架
1. Map-Reduce
MR的价值体现在对大数据集的分布式处理上。
如下面的图例:(图片来自Scalable Machine Learning from BerkelyX)
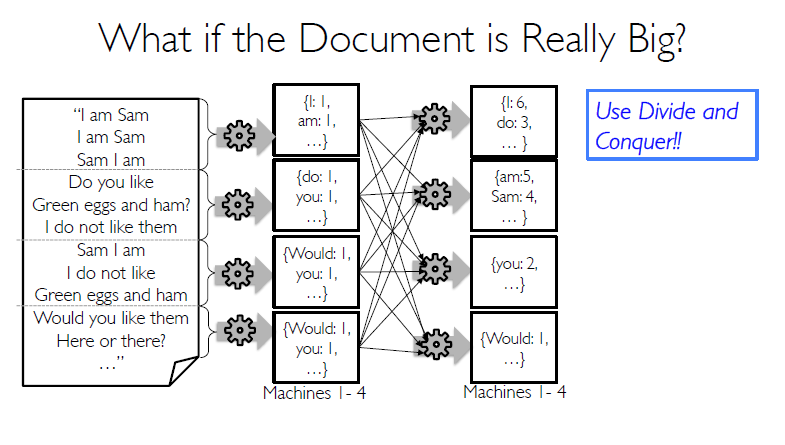
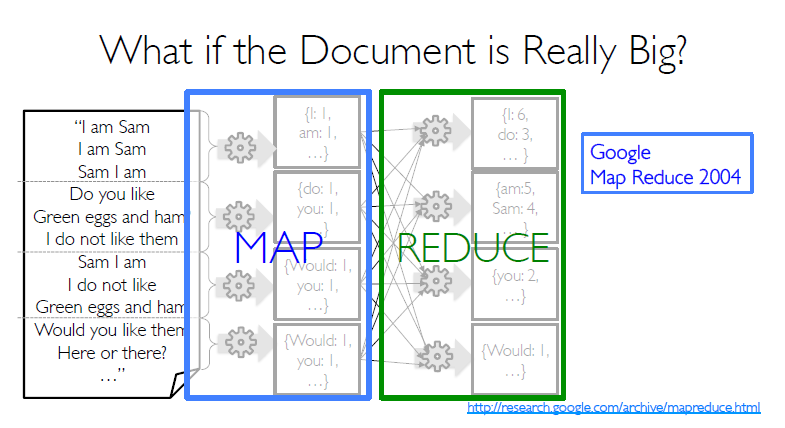
将大规模的文档先分开成不同的partitions到不同的worker;再通过map,对每一个worker的文档进行映射处理;最后一步通过Reduce操作,分而治之。
- 不仅仅是Map-Reduce
当然,在Spark,还提供了更多的transformation 函数,比方说 filter 和 join。以及其他很多很多的操作,极大提升了灵活性。

2. Spark Driver and Workers
一张图表示Spark整体架构:
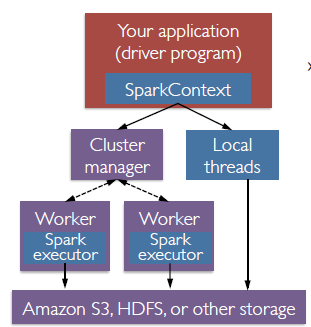
RDDs就是分布在workers上的
Spark Context一开始就要定义
内设对象
1. RDDs
Resilient Distributed Datasets
存在样式:
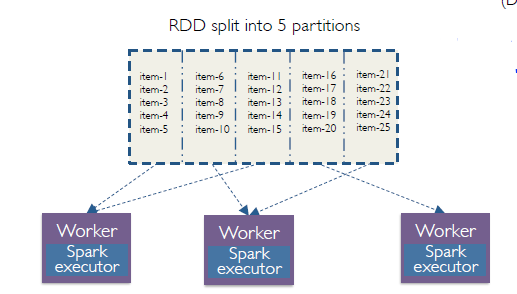
一旦创建不可更改!
可以通过如下方式创建:
parallelize 一个数据集
transform 另一个RDDs
从HDFS或者其他存储系统中读取操作:
- Transformations:
比如map, flatmap, filter等
属性:lazy,非立刻执行,而是等到actions发生才会被执行 - Actions:
比如:collect,count, reduce
- Transformations:
- 总结
RDDs的整体流程就是
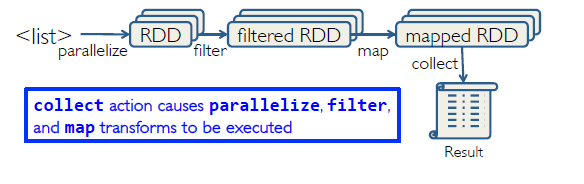
对RDDs的操作实例可参见我的另一篇文章Spark+Python lab2
2. Key-Value RDDs
3. Closures
4.Shared Variables
<未完待续>















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









