







 本文介绍如何通过QQ音乐获取歌单ID,利用开发者工具抓取歌曲名,将其整理为文本文件,并通过Tunemymusic导入歌单。步骤包括浏览器操作、代码执行和在线平台操作。
本文介绍如何通过QQ音乐获取歌单ID,利用开发者工具抓取歌曲名,将其整理为文本文件,并通过Tunemymusic导入歌单。步骤包括浏览器操作、代码执行和在线平台操作。
一.获取歌单中的歌名及歌手
1.先是获取歌单ID
通过网页登录QQ音乐,然后点击对应的歌单
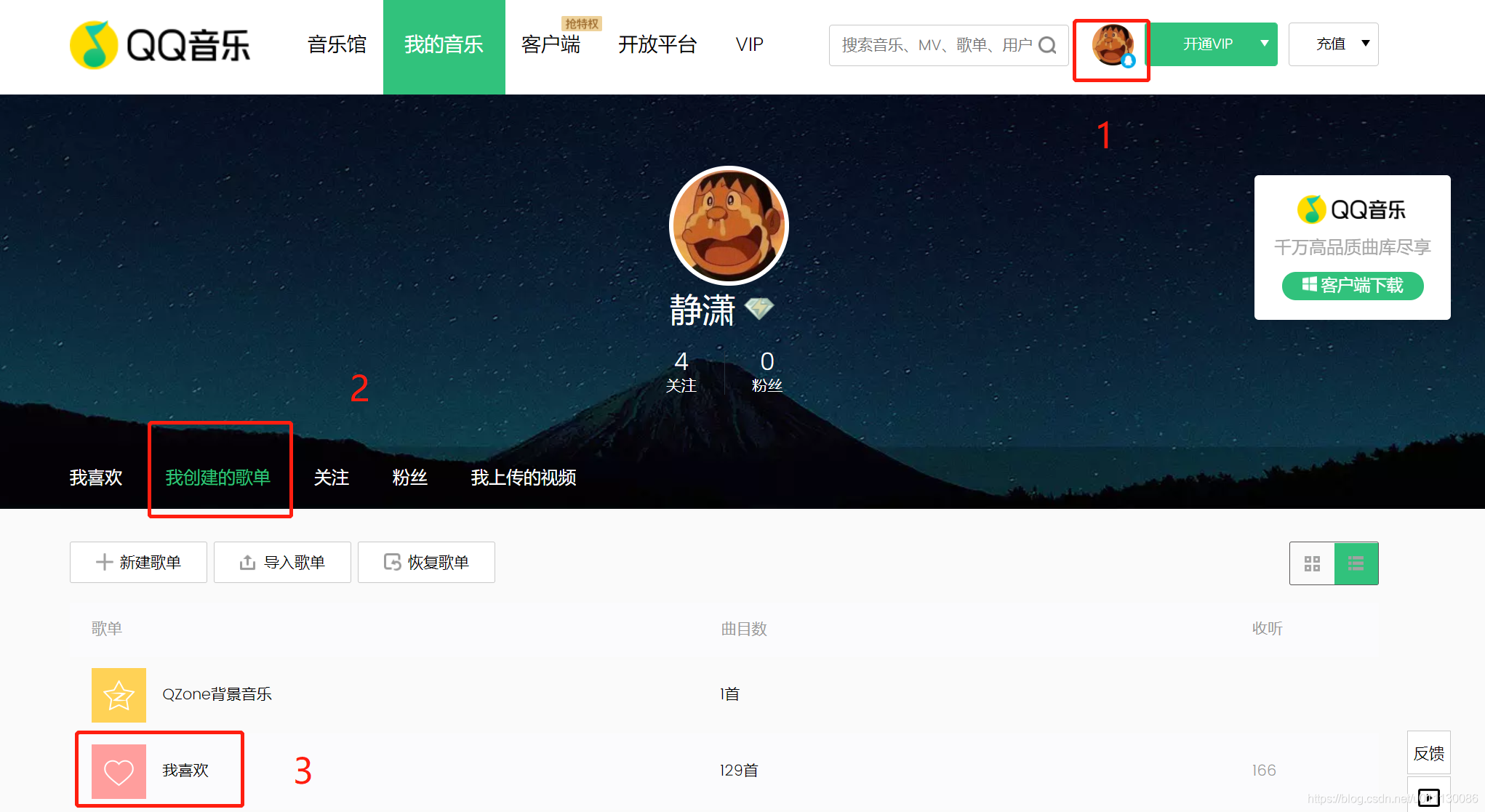
进入歌单后,通过url获取歌单ID
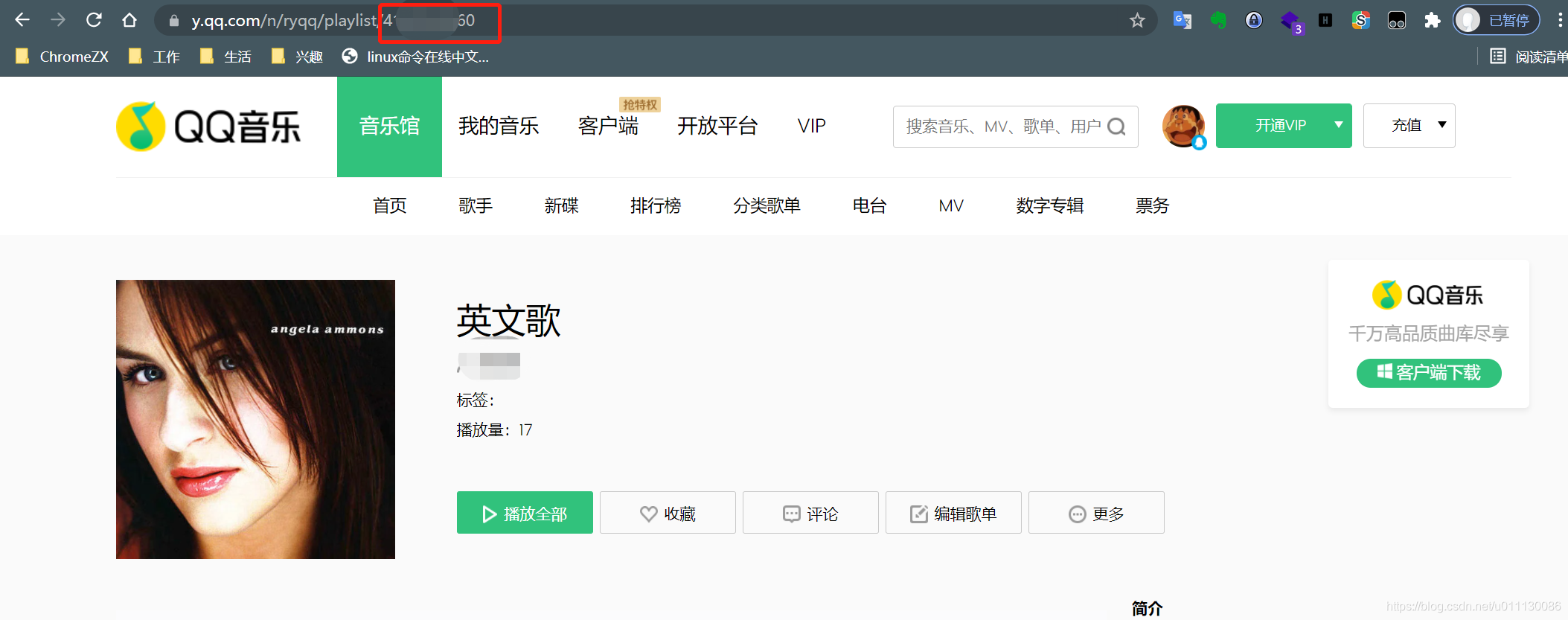
2.将歌单中的歌曲名导出
访问以下地址,并将上面得到的歌单ID替换掉下面的"您的歌单ID"
https://y.qq.com/musicmac/v6/playlist/detail.html?id=您的歌单ID
chrome浏览器进入页面后,F12调出开发者页面>console
然后执行以下代码
Array.from(document.querySelectorAll(".songlist__item"))
.map(
v =>
v.querySelector(".singer_name").title +
" - " +
v.querySelector(".mod_songname__name").title
)
.reduce((s1, s2) => s1 + "\n" + s2);
结果如图:
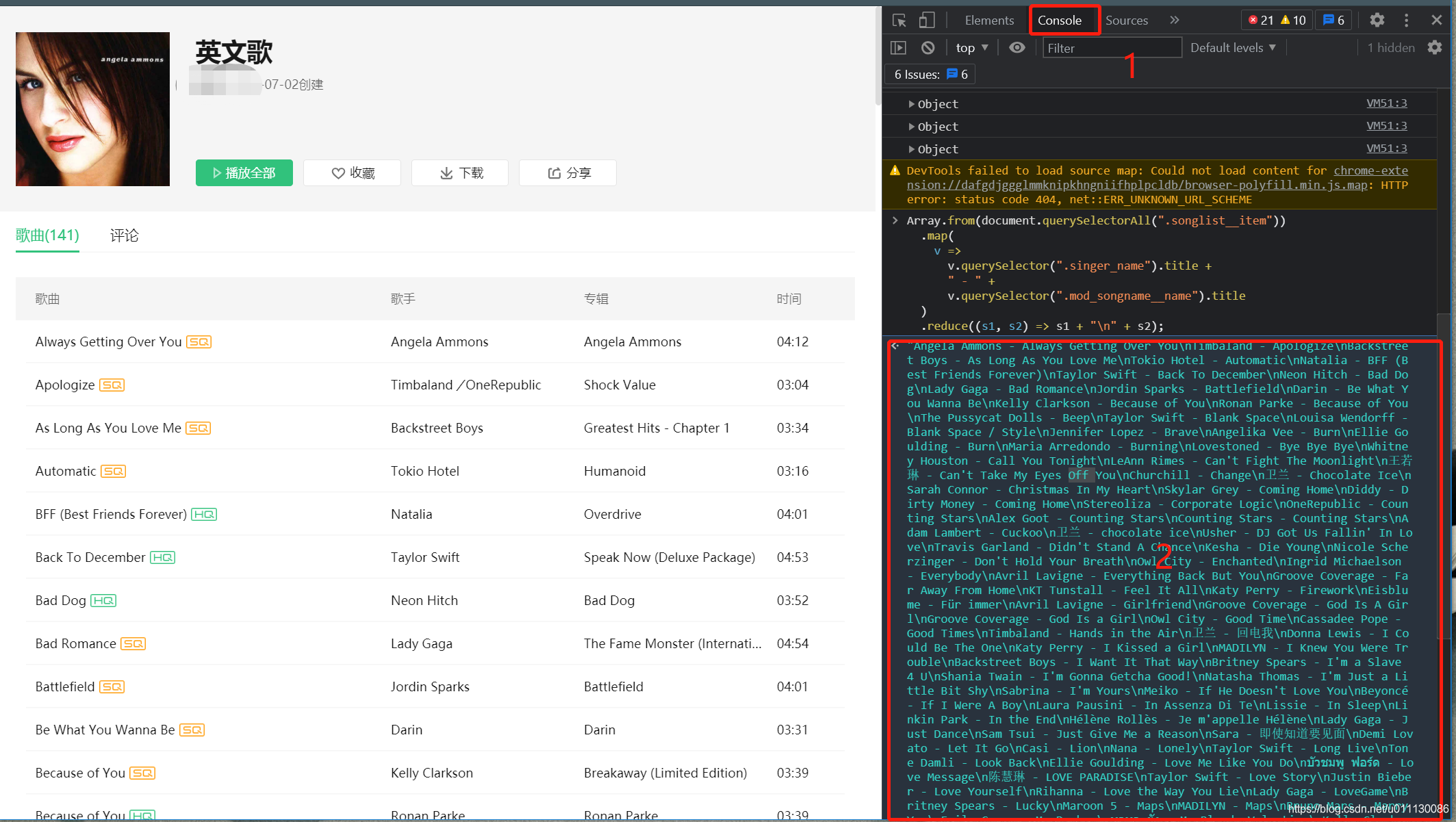
图中2原本是输入代码窗户,输入命令后就会获得歌单里的歌曲
然后将获取到的歌曲名单复制保存到本地文档中
二.将获取到的歌名保存到文件并设置成一行一首歌
上面获取到的所有歌名在一行,必须要设置成一首歌一行才行,这个方法很多,会的就不用看这步了
方法一:
用Notepad++打开保存的文档,
将文本中\n这个关键字替换成特殊符号,只要是歌名中没有的就行,我这里换的是英文逗号
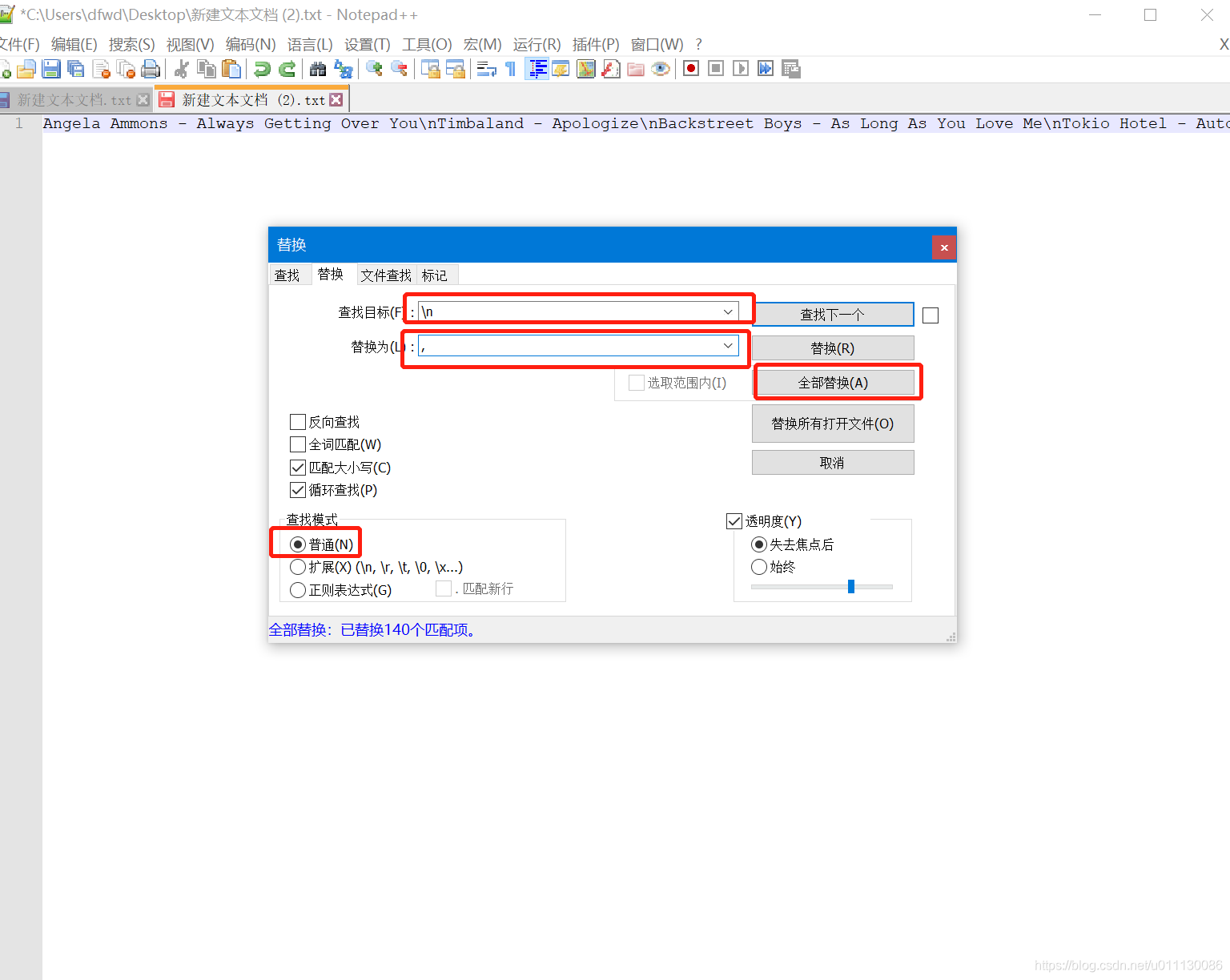
成功后再替换一次
将英文逗号替换成\r\n,注意切换成正则表达式
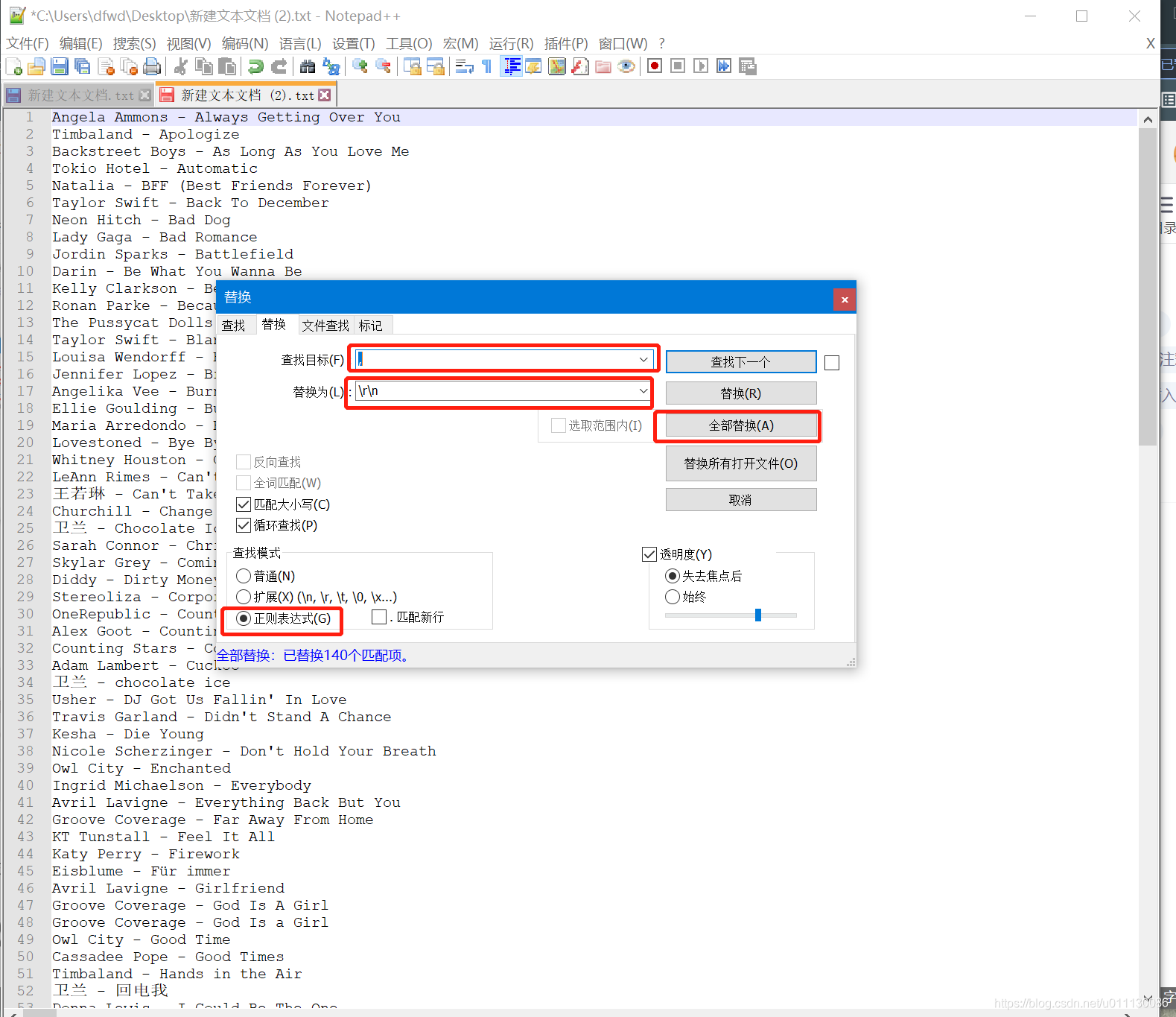
最后就会得到完整的歌曲名
方法二:
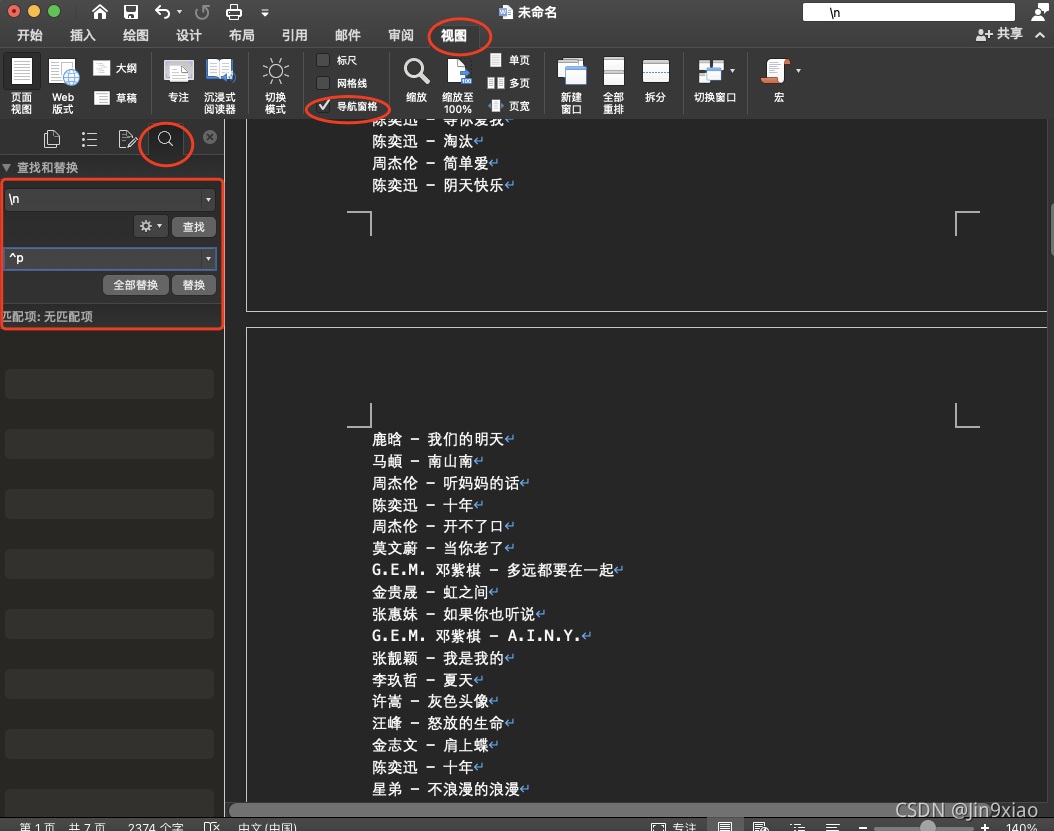
再分享一个换行的方法,因为最近换了macos,字符换行居然折腾了1个小时。
使用word.(对,微软的word,这个跨平台,以后不用操心操作系统的问题了)
打开word,将得到所有歌曲在一行的歌单复制进去,然后替换windows端是ctrl+H
macos端是菜单栏>视图>导航窗口>放大镜
三.通过第三方网站导入歌单
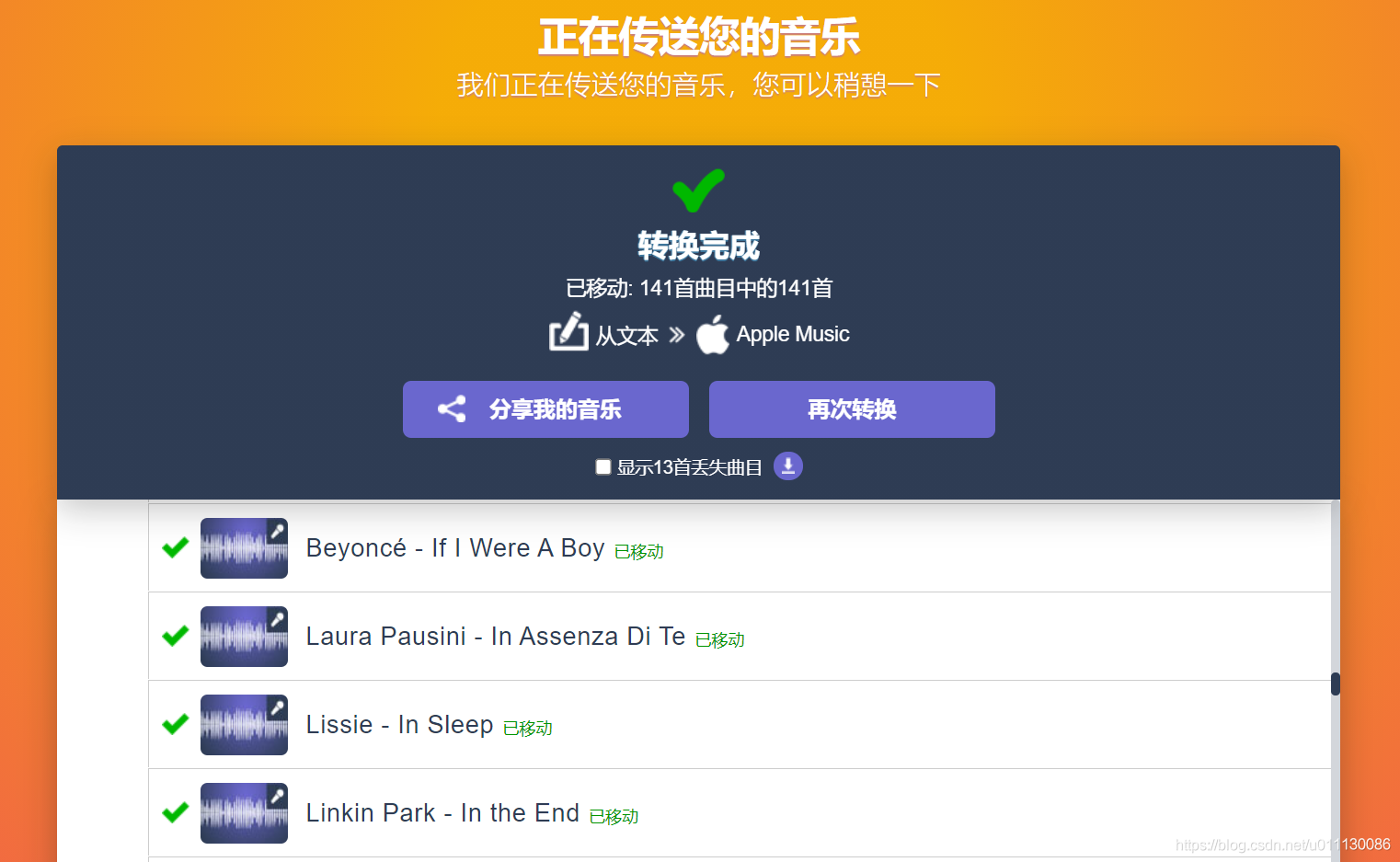
然后进入该网站
https://www.tunemymusic.com/zh-cn/
自行进行歌单添加,全中文操作,没有什么好说的,就说下大概流程
开始>选择来源(文本)>根据提示复制粘贴刚才得到的歌单>然后选择要导入的平台>输入对应平台的账号密码>等待完成


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









