







awk命令 http://man.linuxde.net/awk
常用命令选项:
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-f scripfile 从脚本文件中读取awk命令
-v var=value 赋值一个用户定义变量,将外部变量传递给awk -f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
awk脚本的基本结构:
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file
{ }类似一个循环体,会对文件中的每一行进行迭代,通常变量初始化语句(如:i=0)以及打印文件头部的语句放入BEGIN语句块中,将打印的结果等语句放在END语句块中。
对输出求和:
$ seq 6 | awk 'BEGIN {sum=0; print "总和:"} {print $1"+"; sum+=$1} END{print "等于"; print sum}'
说明:begin和end必须要大写
示例:
(1)将外部变量值传递给awk
借助-v选项,可以将外部值(并非来自stdin)传递给awk:
VAR=10000
echo | awk -v VARIABLE=$VAR '{ print VARIABLE }'
另一种传递外部变量方法:
var1="aaa"
var2="bbb"
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2
当输入来自于文件时使用:
awk '{ print v1,v2 }' v1=$var1 v2=$var2 filename
以上方法中,变量之间用空格分隔作为awk的命令行参数跟随在BEGIN、{}和END语句块之后。
awk 内置变量(预定义变量)
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[N] ARGC 命令行参数的数目。
[G] ARGIND 命令行中当前文件的位置(从0开始算)。
[N] ARGV 包含命令行参数的数组。
[G] CONVFMT 数字转换格式(默认值为%.6g)。
[P] ENVIRON 环境变量关联数组。
[N] ERRNO 最后一个系统错误的描述。
[G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。
[A] FILENAME 当前输入文件的名。
[P] FNR 同NR,但相对于当前文件。
[A] FS 字段分隔符(默认是任何空格)。
[G] IGNORECASE 如果为真,则进行忽略大小写的匹配。
[A] NF 表示字段数,在执行过程中对应于当前的字段数。
[A] NR 表示记录数,在执行过程中对应于当前的行号。
[A] OFMT 数字的输出格式(默认值是%.6g)。
[A] OFS 输出字段分隔符(默认值是一个空格)。
[A] ORS 输出记录分隔符(默认值是一个换行符)。
[A] RS 记录分隔符(默认是一个换行符)。
[N] RSTART 由match函数所匹配的字符串的第一个位置。
[N] RLENGTH 由match函数所匹配的字符串的长度。
[N] SUBSEP 数组下标分隔符(默认值是34)。
示例:
(1)使用print $NF可以打印出一行中的最后一个字段,使用$(NF-1)则是打印倒数第二个字段,其他以此类推:
echo -e "line1 f2 f3n line2 f4 f5" | awk '{print $NF}'
f3
f5
(2)统计文件中的行数:
awk 'END{ print NR }' filename
————————————————————————————————————————————————————————
awk 高级输入输出
1、读取下一条记录
awk中next语句使用:在循环逐行匹配,如果遇到next,就会跳过当前行,直接忽略下面语句。而进行下一行匹配。next语句一般用于多行合并:
2、简单地读取一条记录 awk getline
awk getline用法:输出重定向需用到getline函数。getline从标准输入、管道或者当前正在处理的文件之外的其他输入文件获得输入。它负责从输入获得下一行的内容,并给NF,NR和FNR等内建变量赋值。如果得到一条记录,getline函数返回1,如果到达文件的末尾就返回0,如果出现错误,例如打开文件失败,就返回-1。
getline语法:getline var,变量var包含了特定行的内容。
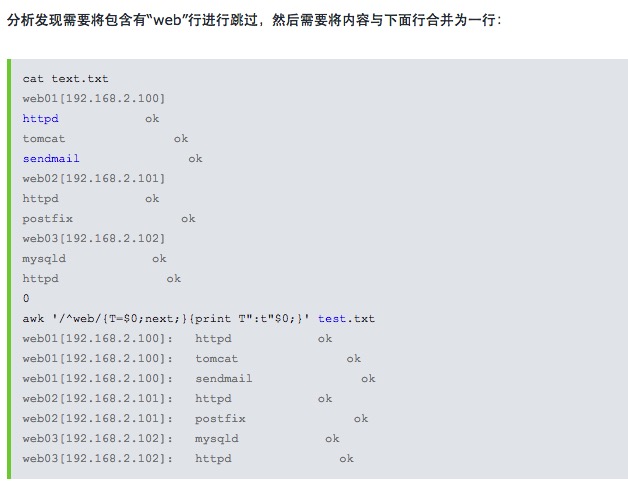
awk getline从整体上来说,用法说明:
(1)当其左右无重定向符|或<时:getline作用于当前文件,读入当前文件的第一行给其后跟的变量var或$0(无变量),应该注意到,由于awk在处理getline之前已经读入了一行,所以getline得到的返回结果是隔行的。
(2)当其左右有重定向符|或<时:getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
示例:
(1) 执行linux的date命令,并通过管道输出给getline,然后再把输出赋值给自定义变量out,并打印它:
awk 'BEGIN{ "date" | getline out; print out }'
结果:2016年11月24日 星期四 11时53分38秒 CST
(2)执行shell的date命令,并通过管道输出给getline,然后getline从管道中读取并将输入赋值给out,split函数把变量out转化成数组mon,然后打印数组mon的第二个元素:
awk 'BEGIN{ "date" | getline out; split(out,mon); print mon[2] }'
结果:星期四
(3)关闭文件
awk中允许在程序中关闭一个输入或输出文件,方法是使用awk的close语句。
close("filename")
(4)输出到一个文件
awk中允许用如下方式将结果输出到一个文件:
echo | awk '{printf("hello word!n") > "datafile"}'
或
echo | awk '{printf("hello word!n") >> "datafile"}'
—————————————————————————————————————————————————————————
awk 流程控制
1、条件判断: 每条命令语句后面可以用;分号结尾。
if(表达式)
{语句1}
else if (表达式)
{语句2}
else {语句3}
2、循环语句

(1)while
while(表达式)
{语句}

(2)for
for循环有两种格式:
for(变量 in 数组)
{语句}
或者:
for(变量;条件;表达式)
{语句}


(3)do
do
{语句}
while(条件)

3、其他语句:
break 当 break 语句用于 while 或 for 语句时,导致退出程序循环。
continue 当 continue 语句用于 while 或 for 语句时,使程序循环移动到下一个迭代。
next 能能够导致读入下一个输入行,并返回到脚本的顶部。这可以避免对当前输入行执行其他的操作过程。
exit 语句使主输入循环退出并将控制转移到END,如果END存在的话。如果没有定义END规则,或在END中应用exit语句,则终止脚本的执行。
4、数组
数组是awk的灵魂,处理文本中最不能少的就是它的数组处理。因为数组索引(下标)可以是数字和字符串在awk中数组叫做关联数组(associative arrays)。awk 中的数组不必提前声明,也不必声明大小。数组元素用0或空字符串来初始化,这根据上下文而定。
注意:数组下标是从1开始,与C数组不一样。
(1)数字做数组索引(下标):
Array[1]="sun"
Array[2]="kai"
(2)字符串做数组索引(下标):
Array["first"]="www"
Array["last"]="name"
Array["birth"]="1987"
(3)读取数组的值
{ for(item in array) {print array[item]}; } #输出的顺序是随机的
{ for(i=1;i<=len;i++) {print array[i]}; } #Len是数组的长度
—————————————————————————————————————————————————————————
用法示例:
1、打印文件的第一列(域) : awk '{print $1}' filename
2、打印文件的前两列(域) : awk '{print $1,$2}' filename3、打印完第一列,然后打印第二列 : awk '{print $1 $2}' filename
4、打印文本文件的总行数 : awk 'END{print NR}' filename
5、打印文本第一行 :awk 'NR==1{print}' filename
6、打印文本第二行第一列 :sed -n "2, 1p" filename | awk 'print $1'
7、shell里面的赋值方法有两种,格式为
1) arg=`(命令)`2) arg=$(命令)
因此,如果想要把某一文件的总行数赋值给变量nlines,可以表达为:
1) nlines=`(awk 'END{print NR}' filename)`
或者
2) nlines=$(awk 'END{print NR}' filename)















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









