




 本文详细介绍了HTTP参数污染(HPP)的概念,漏洞原理通过实例展示不同搜索引擎的行为,以及如何测试服务器处理差异。重点列举了逻辑漏洞(如IDOR、权限操作)和绕过检测(如SQL注入、XSS)的实战案例。同时,给出了挖掘HPP漏洞的技巧和修复方案,包括设备层面和代码层面的防范措施。
本文详细介绍了HTTP参数污染(HPP)的概念,漏洞原理通过实例展示不同搜索引擎的行为,以及如何测试服务器处理差异。重点列举了逻辑漏洞(如IDOR、权限操作)和绕过检测(如SQL注入、XSS)的实战案例。同时,给出了挖掘HPP漏洞的技巧和修复方案,包括设备层面和代码层面的防范措施。
概念:
HTTP参数污染,也叫HPP(HTTP Parameter Pollution)。简单地讲就是给一个参数赋上两个或两个以上的值,由于现行的HTTP标准没有提及在遇到多个输入值给相同的参数赋值时应该怎样处理,而且不同的网站后端做出的处理方式是不同的,从而造成解析错误。
漏洞原理:
通过简单的案例可以说明这种处理的差异:
在不同的搜索引擎中进行搜索,在地址栏输入URL:?p=usa&p=china,这里重复相同搜索参数,观察搜索结果的不同:
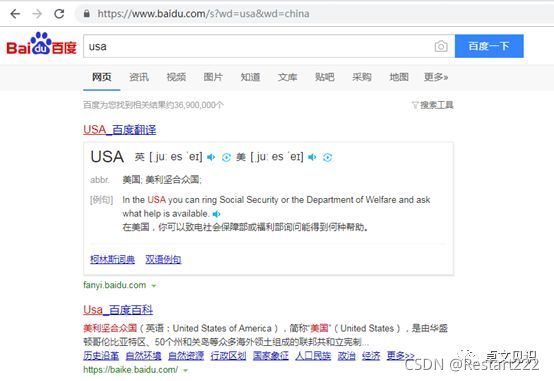
1)百度接受第一个参数(usa)而放弃第二个参数(china):
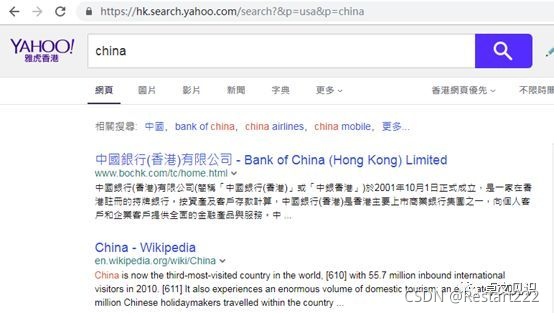
2)Yahho接受第二个参数(china)而放弃第一个参数(usa):
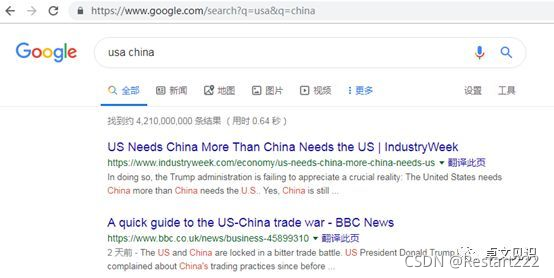
3)Google会将两个值都接受,并通过一个空格将两个参数连接起来,组成一个参数:
测试不同服务器对漏洞的处理方法:
1)对于PHP/Apache服务器,取最后一个值:

2)对于Flask服务器,取第一个值:
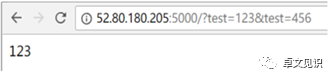
具体服务端对应的不同处理方式如下:
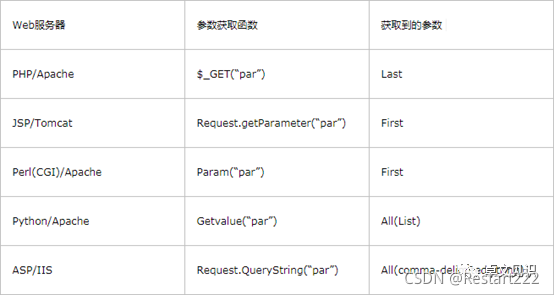
实战案例总结:
HPP漏洞的产生原因一方面来自服务器处理机制的不同,另一方面来自开发人员后端检测逻辑的问题。HTTP 参数污染的风险实际上取决于后端所执行的操作,以及被污染的参数提交到了哪里。总体上HPP一般有两种利用场景:
1)逻辑漏洞,通常会造成IDOR,信息泄露,越权等漏洞;
2)作为其他漏洞的辅助,用于绕过漏洞的检测和Waf等。
这里汇总了工作中和国内外遇到的一些典型案例:
1、 逻辑漏洞(IDOR)
1)敏感操作
SilverlightFox中,网站通过URL:
https://www.example.com/transferMoney.php?amount=1000&fromAccount=12345
进行转账操作,原本链接中是没有toAmount参数的,这个参数是后端固定的,但如果我们重复提交这个参数:
toAccount=9876&amount=1000&fromAccount=12345&toAccount=99999
第二个 toAccount 参数,会覆盖后端请求,并将钱转账给恶意账户( 99999 )而不是由系统设置的预期账户( 9876 )。
2)IDOR(不安全的对象引用)
一般的社交软件都有“关注”或”喜欢”功能,下面就是ID为5318415对5333003进行关注发送的数据包:
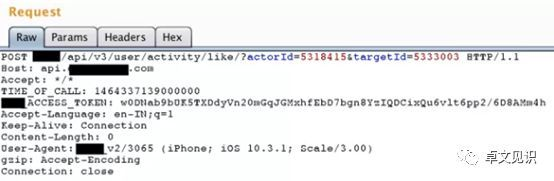
按我们通常挖掘逻辑漏洞的思路,我们可以篡改ID值,使对方关注我。这里5318415是我的ID,但将我的actorId替换为对方的ID,会收到“401 Unauthorized”错误,说明此处做了鉴权操作。
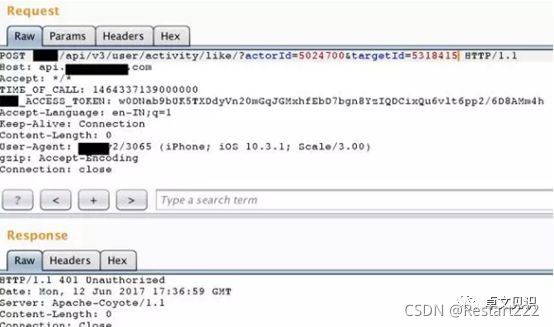
但是,如果请求2个actorId参数,第一个actorId参数是目标的actorId。这样5024700(受害者)会关注5318415(我)。这次得到的响应是202 Accepted。
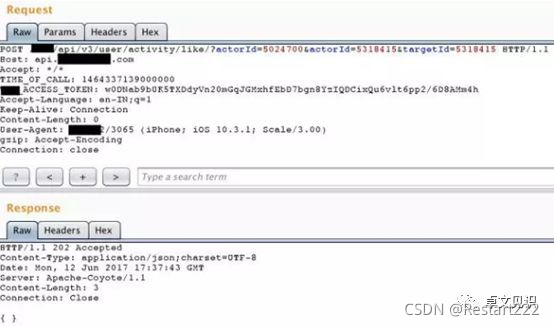
后台对于actorId的鉴权操作是对第二个,关注操作取的却是第一个。所以在测试越权类问题时未果不妨多试一步HPP,下面Twitter案例也是如出一辙:
https://twitter.com/i/u?iid=F6542&uid=2321301342&uid=1134885524&nid=22+26
通过添加第二个uid,取消Twitter的邮箱提醒。
3)社交分享链接
不少网站都有社交分享按钮,可以把内容分享到其他社交媒体,如Hackerone的链接为:https://hackerone.com/blog/introducing-signal,分享到FB上链接为:
https://www.facebook.com/sharer.php?u=https://hackerone.com/blog/introducing-signal
如果我们将要分享的Hackerone的链接改为:https://hackerone.com/blog/introducing-signal?&u=https://vk.com/durov,则最终的跳转会成为:
https://www.facebook.com/sharer.php?u=https://hackerone.com/blog/introducing-signal?&u=https://vk.com/durov
后一个参数u拥有比第一个更高的优先级,之后会用于 Fackbook 的发布,最终会跳转到恶意站点https://vk.com/durov。
4)页面跳转
一个Digits跳转的案例,跳转链接如下:
https://www.digits.com/login?consumer_key=xx&host=https://www.peiscope.tv
如果直接修改参数为http://attacker.com,由于注册域不匹配,因此页面将显示错误,但如果我们使用HPP:
https://www.digits.com/login?consumer_key=xx&host=https://www.peiscope.tv&host=http://attacker.com
从而第一个host参数绕过验证,取第二个host参数作为跳转源。
5)权限操作
以下代码:
<? $val=htmlspecialchars($_GET['par'],ENT_QUOTES); ?>
以下代码使用par参数取用户输入并生成URL:
http://host/page.php?action=view&par=123
但用户若输入par为
则最终生成的链接为:123&action=edit,则最终的请求则变成:
http://host/page.php?action=view&par=123&action=edit
通过重复提交action参数,会导致应用接受编辑操作而不是查看操作,实现权限的提升。
2、 绕过检测(WAF)
1)SQL绕过1
一个常见的SQL注入payload如:
http://xxx/horse.php?id=7 union select 1,2,3,current_user
探测发现网站配置了WAF来阻止任意包含“select”或“union”等常用的SQL查询关键字,通过HPP绕过:
http://xxx/horse.php?id=0&id=7%20union%20select%201,2,3,current_user
注入语句被写到第二个参数值的位置,不会被waf解析。
2)SQL绕过2
ModSecurity过滤器会将类似于select1,2,3 from table这类的语句归类为黑名单。但是这个web服务器在遇到为同一个参数赋值不同数值时,会采取类似谷歌的处理方式,将参数连接起来,以此来绕过黑名单。例如提交如下的URL:
http://xxx/index.aspx?page=select 1&page=2,3 from table
3)Apple Cups的XSS
Apple Cups是被许多UNIX系统利用的打印系统。系统对kerberos进行了黑名单过滤,通过前置一个重复参数可以触发xss:
http://xxx/?kerberos=οnmοuseοver=alert(1)&kerberos=
这个方法可以绕过系统的验证机制,原因是这个验证系统只采纳了第二个kerberos的值,这个值为空,因此不会触发。而第一个kerberos直到被用于构建动态HTML内容前都没有被验证。最终在web站点的上下文中javascript语句被执行。
4)URL重定向+HPP+XSS
在点击网站的链接时,会将用户重定向到一个页面,链接为:
xxx.aspx?dest=http://whitelistedWebsite.com
这容易想到URL重定向漏洞,经过探测,发现dest参数接受的协议有http:// ftp:// http:/ javascript:/,所以尝试构造xss:
dest=javascript://alert(document.domain)
发现存在白名单限制,尝试绕过:
dest=javascript:/whitelistedWebsite.com/i;alert(document.domain
但分号;会无法解析,导致报错,最终使用HPP绕过:
dest=javascript:/whitelistedWebsite.com/i&dest=alert(1)
原理和例1类似,接受两个参数值进行拼接:javascript://alert(1)
挖掘技巧:
根据上面的实战案例总结,在挖掘HPP漏洞的时候,需要注意以下几点:
1、和IDOR漏洞挖掘类似,关注与用户权限紧密相关的参数,有些场景可能防范了IDOR,但重复提交参数可能就会产生奇效;
2、在挖掘其他漏洞的时候,如果进行了检测又无法绕过的情况下,可以尝试通过重复提交参数/参数拼接方式绕过检测。
修复方案:
概括地讲,防范这类攻击的方法有两种:
1、设备层面,让WAF或其他网关设备(比如IPS)在检查URL时,对同一个参数被多次赋值的情况进行特殊处理。由于HTTP协议允许相同参数在URL中多次出现,因此这种特殊处理需要注意避免误杀的情况;
2、代码层面,编写WEB程序时,要通过合理的$_GET方法获取URL中的参数值,而尝试获取web服务器返回给程序的其他值时要慎重处理,结合其他漏洞的产生进行组合排查。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









