







 本文提出了一种名为FLMAAcBD的防御方法,通过检测模型中异常的神经元激活行为来抵御联邦学习中的后门攻击。使用PCA降维和DBSCAN聚类技术,有效识别并移除恶意模型更新,同时保持模型性能。实验证明了该方法在多种攻击场景下的有效性与鲁棒性。
本文提出了一种名为FLMAAcBD的防御方法,通过检测模型中异常的神经元激活行为来抵御联邦学习中的后门攻击。使用PCA降维和DBSCAN聚类技术,有效识别并移除恶意模型更新,同时保持模型性能。实验证明了该方法在多种攻击场景下的有效性与鲁棒性。
FLMAAcBD: Defending against backdoors in Federated Learning via Model Anomalous Activation Behavior Detection(Knowledge-Based Systems 2024)
论文阅读笔记,保留自用
研究动机
现有的两类防御方法的基本思路与缺陷:
-
检测和消除潜在的恶意模型更新
- 排除聚合过程中与大多数模型更新存在显著偏差的可疑模型更新。可能会错误地将使用非独立同分布数据训练的模型识别为中毒模型。
-
限制后门攻击的影响
- 基于对模型参数进行裁剪和添加高斯噪声(受差分隐私技术启发)或去除潜在的恶意神经元,以最大程度地减少后门攻击的影响。模型的良性性能可能会受到影响
需要解决3个难题:
- 中毒样本和干净样本之间神经元激活值的差异并不总是反映在不同攻击场景下神经网络的倒数第二层,导致该层并不总是后门检测最关键的地方
- 不同攻击场景下获得的降维数据点具有不同的分布范围。此外,DBSCAN需要适当的超参数,这使得在不同的攻击场景中直接使用DBSCAN进行异常检测具有挑战性。
- 如何确定限幅阈值和噪声水平,同时有效消除后门并在全局模型上保持尽可能高的良性性能
技术原理
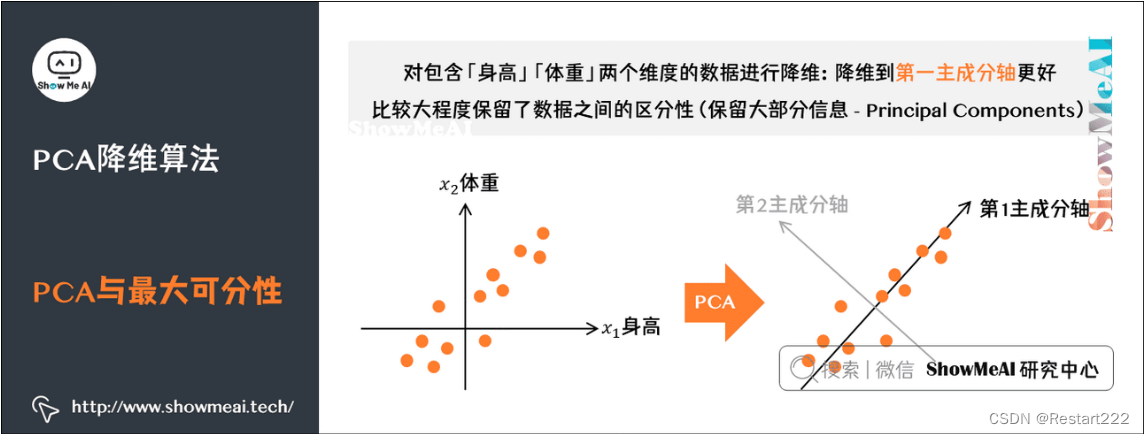
- PCA降维
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。
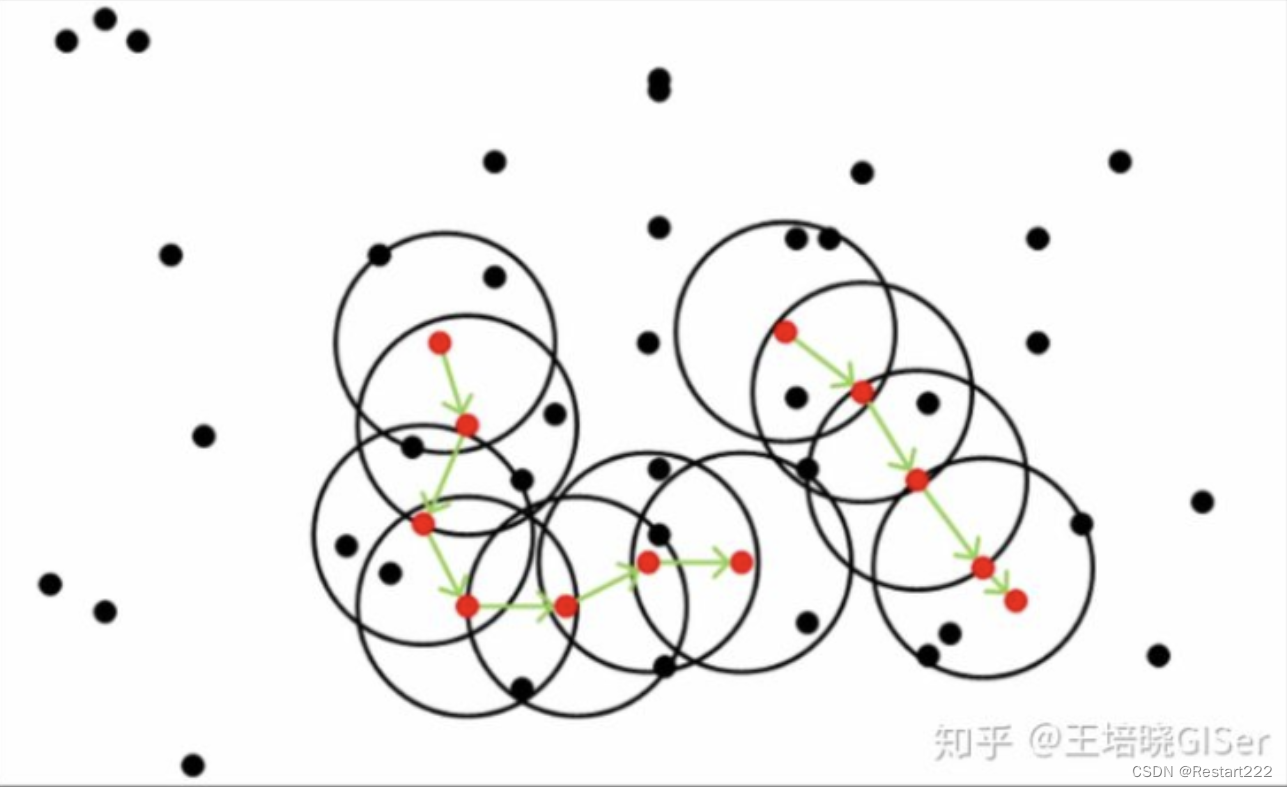
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一基于密度的聚类算法,DBSCAN将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
与K-means聚类算法相比,基于密度的噪声应用空间聚类(DBSCAN)具有更好的噪声容忍度,并且可以自动计算任意形状的簇的数量,从而可以将数据点分为几个具有相似密度的聚类可以识别异常值,可用于异常检测。
防御流程
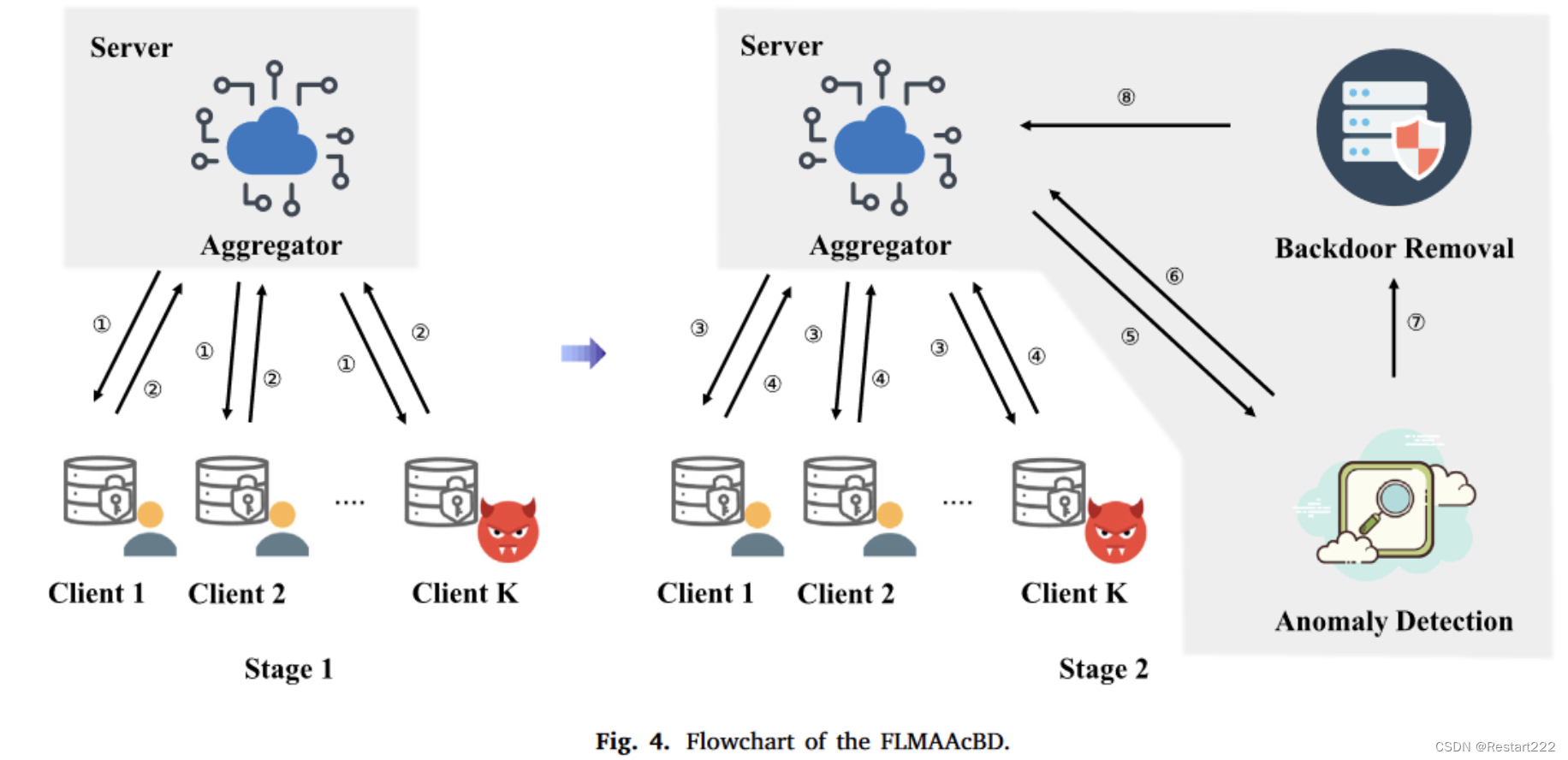
第一阶段:正常进行联邦学习
第二阶段:加入异常检测模块和后门移除模块
后门检测方法

服务器首先将模型 G t e m p t G_{temp}^t Gtempt 和 G t − 1 G^{t-1} Gt−1传递给客户端 k,并要求其计算激活值并执行必要的预处理。然后客户端k将结果发送回服务器进行异常检测。
样本j在第 l \text{l} l层神经元i的激活值由 a i , j k , l = ϕ ( ∑ z = 1 M w z l a z , j k , l − 1 + β i l ) a_{i,j}^{k,l}=\phi\left(\sum_{z=1}^{M}w_{z}^{l}a_{z,j}^{k,l-1}+\beta_{i}^{l}\right) ai,jk,l=ϕ(∑z=1Mwzlaz,jk,l−1+βil)计算
a z , j k , l − 1 a_{z,j}^{k,l-1} az,jk,l−1表示客户端 k 的样本 j 在第 l − 1 l-1 l−1层神经元 z 中的激活值。 w z l w_z^l wzl 和 β i l \beta_i^l βil表示对应的神经网络权重。M 是 l − 1 l-1 l−1层神经元的数量。 ϕ \boldsymbol{\phi} ϕ代表非线性激活函数。
对于卷积层,形状为(B, C, H ,W),B是批量大小,C表示输出通道数,H和W分别表示输出特征图的高度和宽度。将通道数 C 作为第L层神经元的数量,使得每个神经元的激活值是最后一个二维值的总和,即 (H, W ) 之和。
考虑到激活值的独特性可能并不总是反映在模型的固定层(例如模型的倒数第二层并非一定是后门检测的关键层),客户端k从 ⌊ L / 2 ⌋ + 1 \lfloor L/2\rfloor+1 ⌊L/2⌋+1层到模型的 L − 1 L-1 L−1层计算样本激活值,并按层顺序连接以获得激活值向量。解决难题1
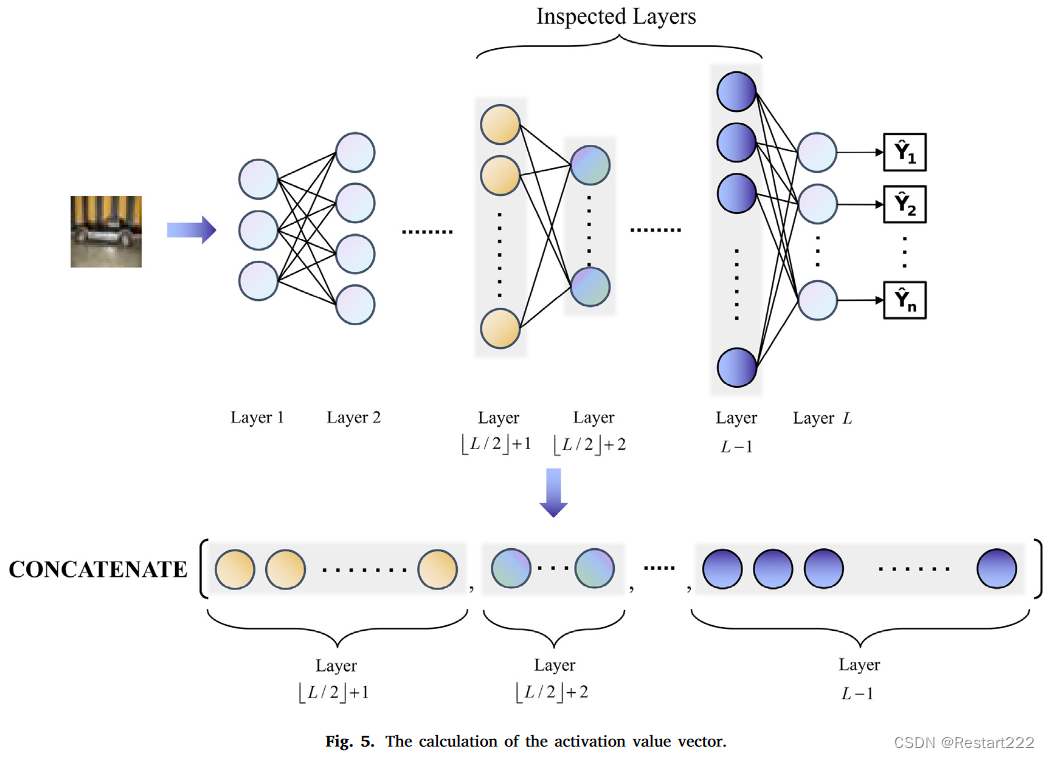
客户端的整个数据集在模型 G t e m p t G_{temp}^t Gtempt 和 G t − 1 G^{t-1} Gt−1上分别计算以获得激活值矩阵
A c t e m p k = [ a 1 1 a 2 1 ⋯ a q 1 a 1 2 a 2 2 ⋯ a q 2 ⋮ ⋮ ⋱ ⋮ a 1 ∣ D k ∣ a 2 ∣ D k ∣ ⋯ a q ∣ D k ∣ ] Ac_{temp}^k=\begin{bmatrix}a_1^1&a_2^1&\cdots&a_q^1\\a_1^2&a_2^2&\cdots&a_q^2\\\vdots&\vdots&\ddots&\vdots\\a_1^{\left|D^k\right|}&a_2^{\left|D^k\right|}&\cdots&a_q^{\left|D^k\right|}\end{bmatrix} Actempk= a11a12⋮a1∣Dk∣a21a22⋮a2∣Dk∣⋯⋯⋱⋯aq1aq2⋮aq∣Dk∣ 和 A c t − 1 k = [ b 1 1 b 2 1 ⋯ b q 1 b 1 2 b 2 2 ⋯ b q 2 ⋮ ⋮ ⋱ ⋮ b 1 ∣ D k ∣ b 2 ∣ D k ∣ ⋯ b q ∣ D k ∣ ] Ac_{t-1}^k=\begin{bmatrix}b_1^1&b_2^1&\cdots&b_q^1\\b_1^2&b_2^2&\cdots&b_q^2\\\vdots&\vdots&\ddots&\vdots\\b_1^{\left|D^k\right|}&b_2^{\left|D^k\right|}&\cdots&b_q^{\left|D^k\right|}\end{bmatrix} Act−1k= b11b12⋮b1∣Dk∣b21b22⋮b2∣Dk∣⋯⋯⋱⋯bq1bq2⋮bq∣Dk∣
矩阵的每一行代表样本的激活值向量,q表示神经元总数。
接下来,计算两个矩阵对应元素之间的绝对差,以描述样本在两个模型上的激活值变化的幅度。 A c k = ∣ A c t e m p k − A c t − 1 k ∣ Ac^{k}=\left|Ac_{temp}^{k}-Ac_{t-1}^{k}\right| Ack= Actempk−Act−1k
由于 A c k Ac^{k} Ack的每一列代表了特定神经元跨样本的激活值变化的分布,因此如果计算 A c k Ac^{k} Ack的每一列的方差,就可以得到不同神经元跨不同样本的激活值变化的稳定性。在一轮训练中,如果模型 G t − 1 G^{t-1} Gt−1是良性的,而模型 G t e m p t G_{temp}^t Gtempt是后门模型,那么恶意客户端 k 通过上述过程计算出的特定神经元的方差将与其他良性客户端的方差显着不同。因此,恶意客户端k的异常激活特征可以在最终结果 A c f i n a l k Ac^{k}_{final} Acfinalk中得到体现。
服务器收集各个客户端的检测信息并整合到矩阵 A c = { A c f i n a l 1 , A c f i n a l 2 , … , A c f i n a l K } Ac=\left\{Ac_{final}^{1},Ac_{final}^{2},\ldots,Ac_{final}^{K}\right\} Ac={Acfinal1,Acfinal2,…,AcfinalK},然后使用PCA降维,最后通过DBSCAN对标准化数据进行聚类,如果获得的簇数量等于或大于两个(噪声也被视为一类),则表明可能存在后门攻击。否则视为正常,不采取进一步措施。经过降维和归一化后,可以为DBSCAN设置相同的超参数,以实现针对不同后门攻击场景的异常检测。解决难题2
后门移除方法
异常检测模块检测到异常情况时,服务器会剪辑客户端提交的所有模型更新并聚合它们以获得新的全局模型。然后,向模型中注入一定量的高斯噪声,完成后门清洗过程。
需要解决的问题:随着模型收敛,每个客户端上传的模型更新的 L2 范数将逐渐减小,简单地设置固定的限幅阈值很难解决上述情况。
提出的自适应裁剪阈值:假设共有K个客户端,对于客户端k的第t轮,模型更新表示为 Δ w k t \Delta w_k^t Δwkt,裁剪阈值表示为
c t = M E D I A N ( ∥ Δ w 1 t ∥ 2 , ∥ Δ w 2 t ∥ 2 , … , ∥ Δ w K t ∥ 2 ) c_{t}=MEDIAN\left(\left\|\Delta w_{1}^{t}\right\|_{2},\left\|\Delta w_{2}^{t}\right\|_{2},\ldots,\left\|\Delta w_{K}^{t}\right\|_{2}\right) ct=MEDIAN(∥Δw1t∥2,∥Δw2t∥2,…,∥ΔwKt∥2)
全局模型更新变为 G ∗ = G t − 1 + l r g l o b a l K ∑ i = 1 K Δ w i t . min ( 1 , c t ∥ Δ w i t ∥ 2 ) G^{*}=G^{t-1}+\frac{lr_{global}}{K}\sum_{i=1}^{K}\Delta w_{i}^{t}.\min\left(1,\frac{c_{t}}{\left\|\Delta w_{i}^{t}\right\|_{2}}\right) G∗=Gt−1+Klrglobal∑i=1KΔwit.min(1,∥Δwit∥2ct)
为了进一步移除残留后门,会向 G ∗ G^{*} G∗再注入少量高斯噪声 N ( 0 , σ G ∗ 2 ) \mathcal{N}\left(0,\sigma_{G^*}^2\right) N(0,σG∗2)
最终的全局模型表示为 G t = G ∗ + N ( 0 , σ G ∗ 2 ) G^t=G^*+\mathcal{N}(0,\sigma_{G^*}^2) Gt=G∗+N(0,σG∗2),其中 σ G ∗ = c t ⋅ λ \sigma_{G^*}=c_t\cdot\lambda σG∗=ct⋅λ, λ = 1 ε 2 ln 1.25 δ \lambda=\frac1\varepsilon\sqrt{2\ln\frac{1.25}\delta} λ=ε12lnδ1.25 。解决难题3
实验
-
数据集和模型:Fashion-MNIST—LeNet-5 model、CIFAR-10—Resnet18、CINIC-10—Resnet18
-
metrics:
- backdoor task accuracy (BA), B A = c r a d { x b a c k d o o r ∣ f ( x b a c k d o o r ) = l t arg e t , x b a c k d o o r ∈ D b a c k d o o r } c r a d { x b a c k d o o r ∣ x b a c k d o o r ∈ D b a c k d o o r } × 100 % BA=\frac{crad\left\{x_{backdoor}|f\left(x_{backdoor}\right)=l_{t\arg et},x_{backdoor}\in D_{backdoor}\right\}}{crad\left\{x_{backdoor}|x_{backdoor}\in D_{backdoor}\right\}}\times100\% BA=crad{xbackdoor∣xbackdoor∈Dbackdoor}crad{xbackdoor∣f(xbackdoor)=ltarget,xbackdoor∈Dbackdoor}×100%
- main task accuracy (MA), M A = c r a d { x b e n i g n ∣ f ( x b e n i g n ) = l s o u r c e , x b e n i g n ∈ D b e n i g n } c r a d { x b e n i g n ∣ x b e n i g n ∈ D b e n i g n } × 100 % MA=\frac{crad\begin{Bmatrix}x_{benign}|f&(x_{benign})=l_{source},x_{benign}\in D_{benign}\end{Bmatrix}}{crad\begin{Bmatrix}x_{benign}|x_{benign}\in D_{benign}\end{Bmatrix}}\times100\% MA=crad{xbenign∣xbenign∈Dbenign}crad{xbenign∣f(xbenign)=lsource,xbenign∈Dbenign}×100%
- true positive rate (TPR), T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
- false positive rate (FPR), F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
实验结果
Fashion-MNIST,IID,像素后门
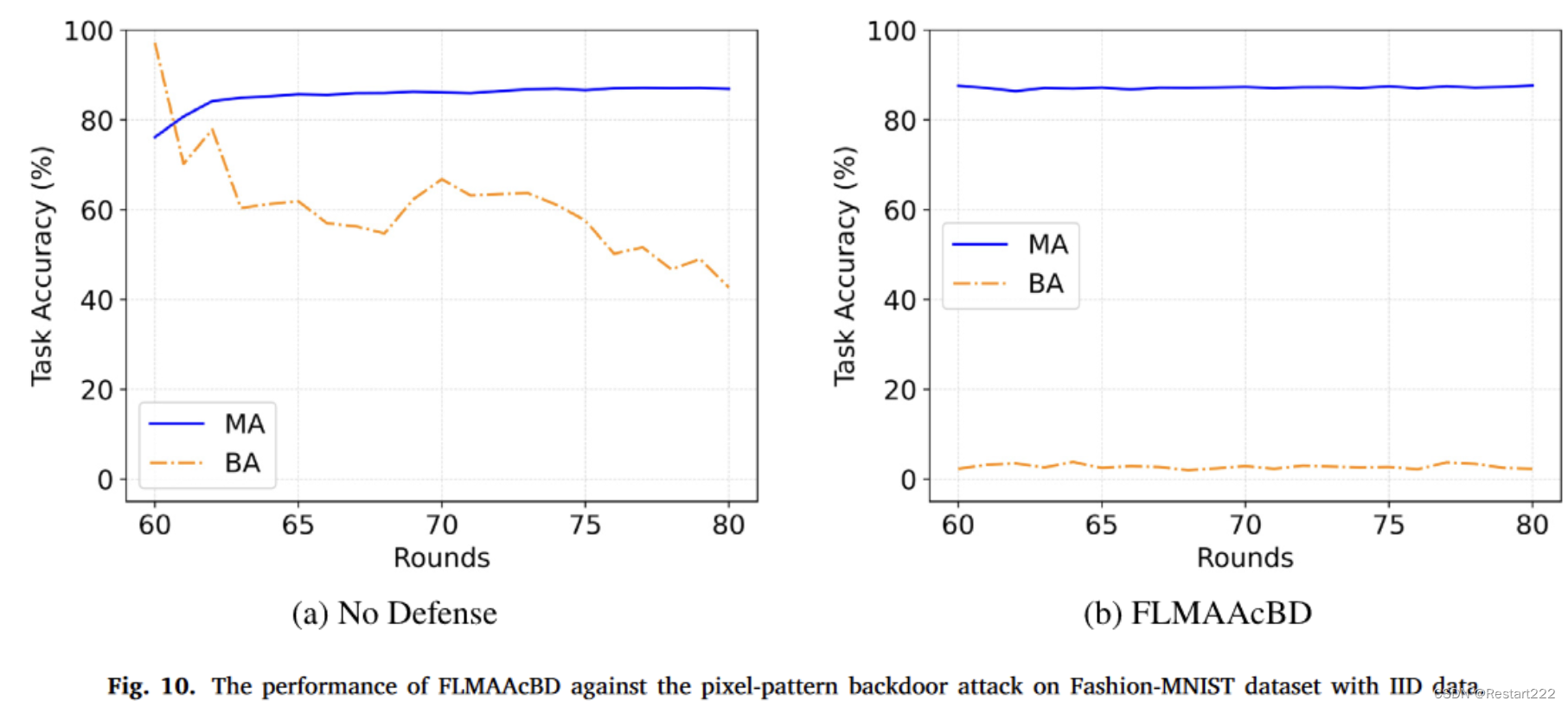
CIFAR10,non-IID,像素后门
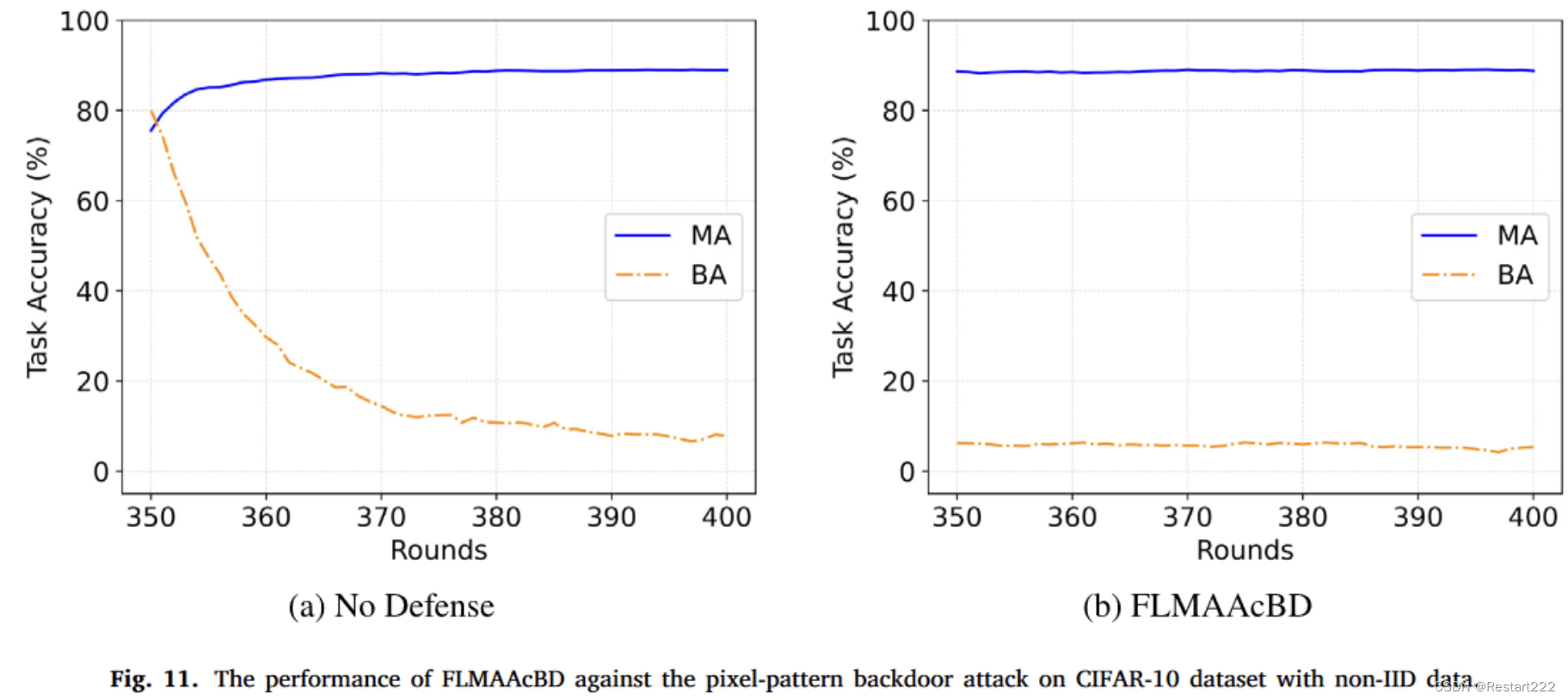
CINIC-10,non-IID,像素后门
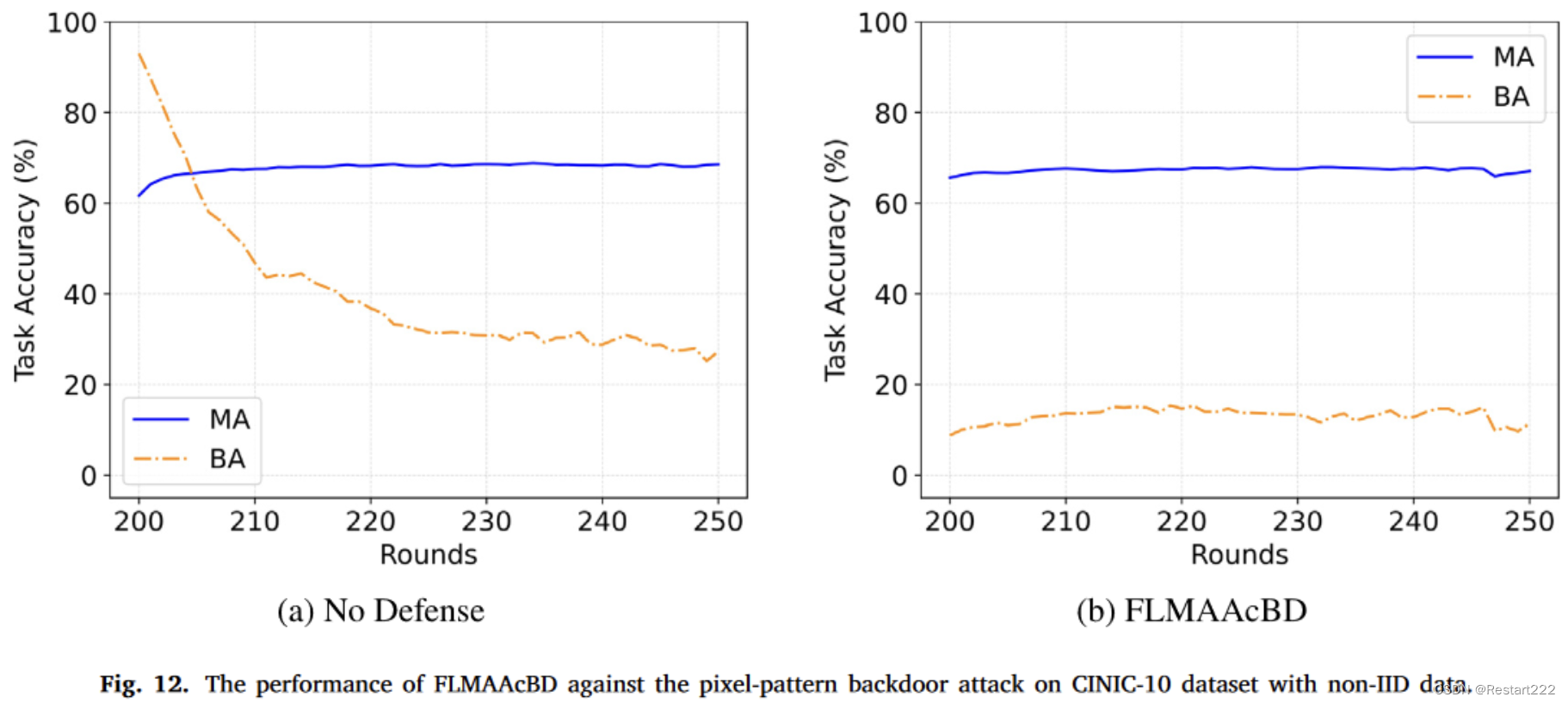
CIFAR-10,non-IID,语义后门
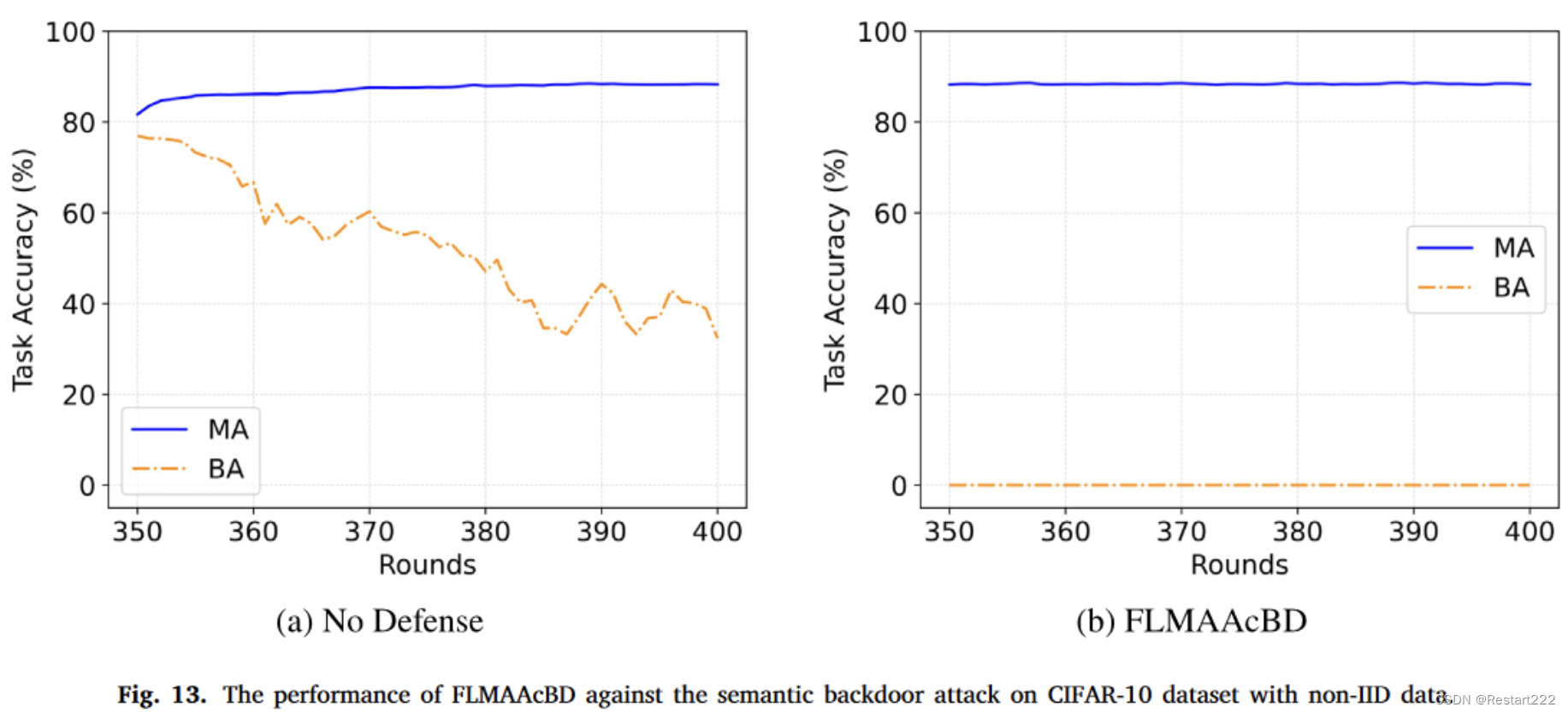
CIFAR-10,non-IID data,DBA攻击
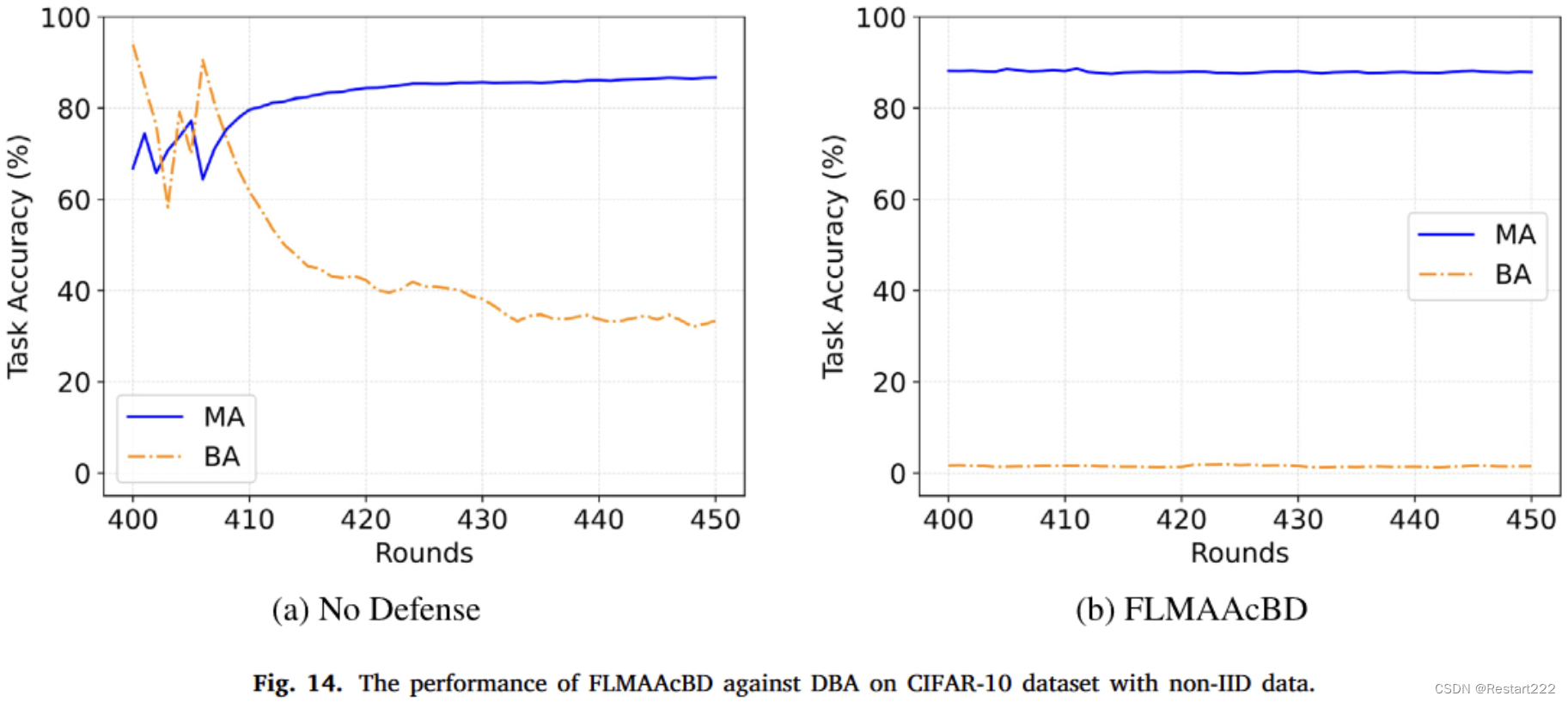
和其他防御进行对比
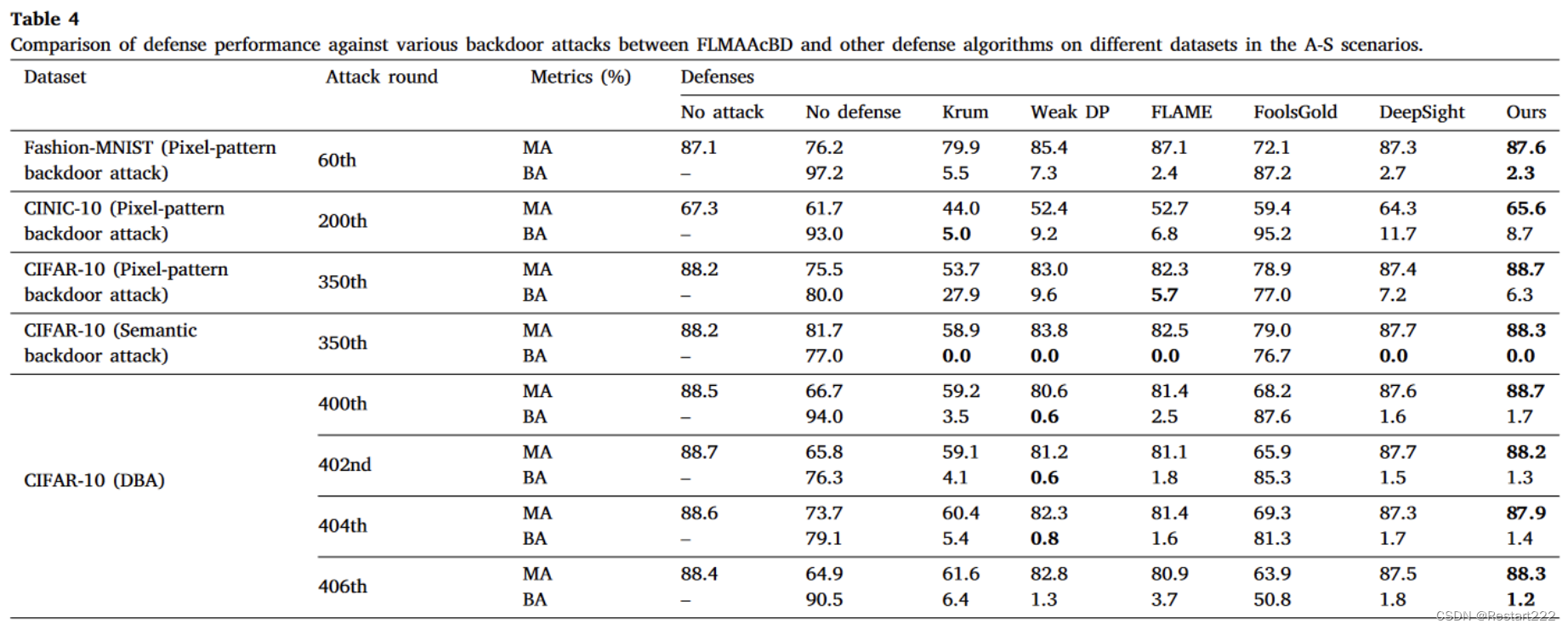
单次攻击
多次攻击
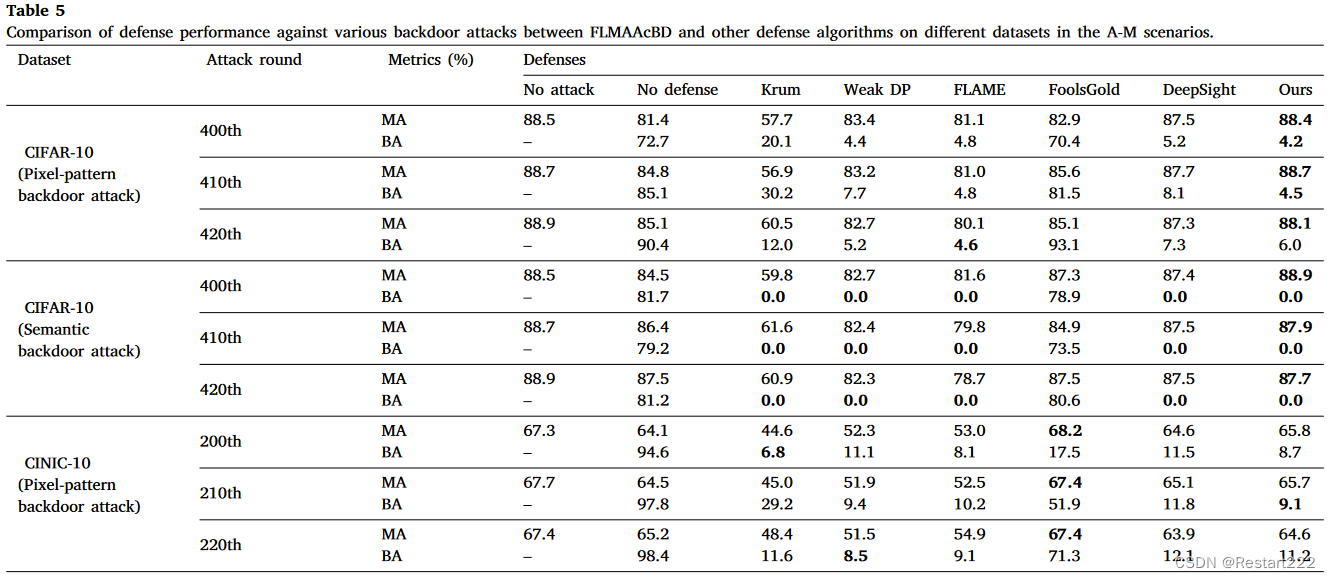
实验结果表明,在各种攻击场景中,所比较的方法要么在对抗后门攻击方面表现不足(例如 FoolsGold),要么对模型的可用性产生不同程度的影响(例如 Krum、Weak DP、FLAME 和 DeepSight)
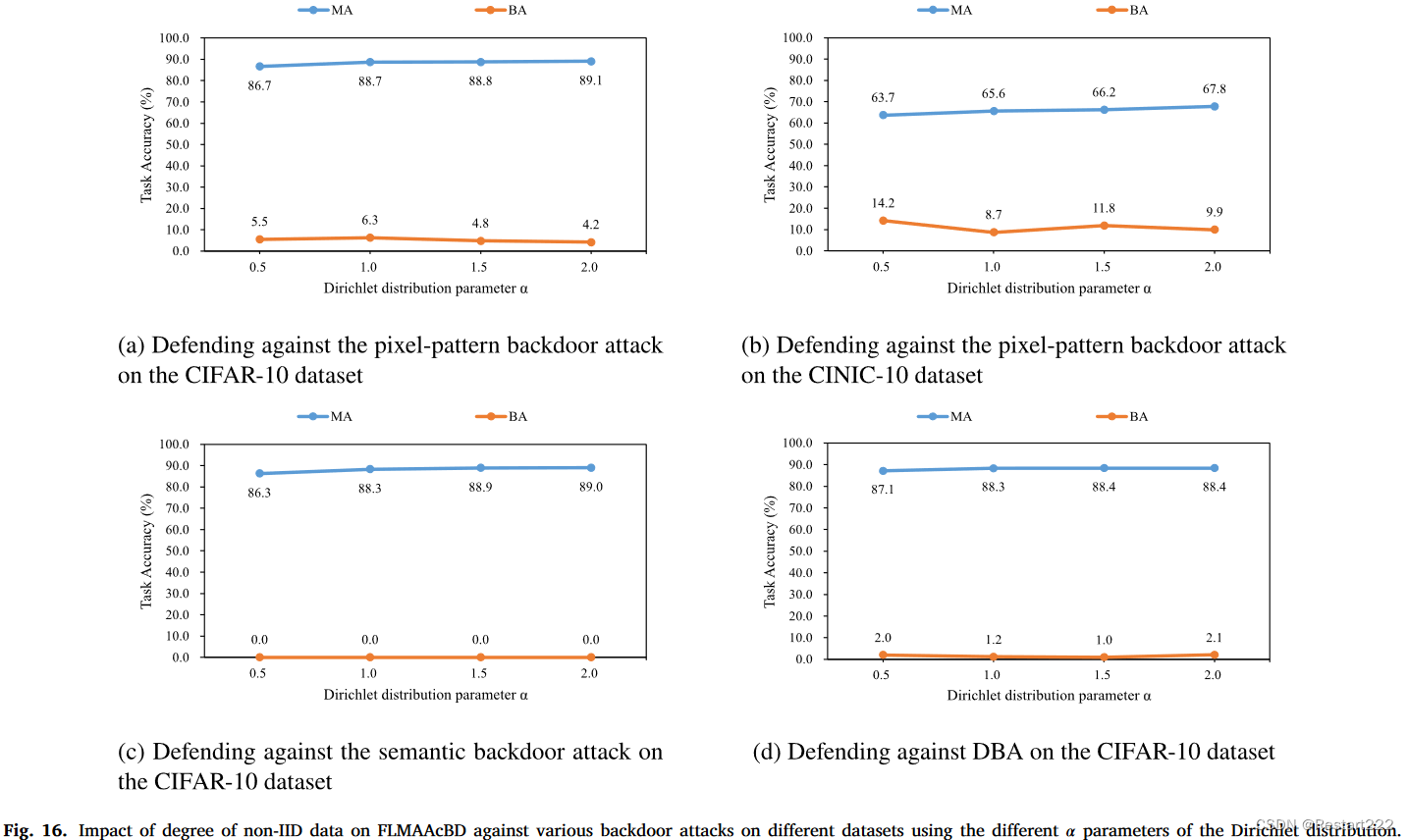
非独立同分布程度对防御效果的影响
对自适应攻击的防御能力
- 假设攻击者对 FLMAAcBD 有一定的了解,他们可以自适应地调整攻击策略来绕过 FLMAAcBD。攻击者在中毒数据集中的干净样本子集上训练良性模型,然后在整个中毒数据集上训练后门模型,并在损失函数中添加额外的惩罚项。利用良性模型来约束后门模型参数的调整方向,以最小化后门模型与良性模型之间的差异。 L a n o m a l y _ e v a s i o n = ∥ w b e n i g n t − w b a c k d o o r t ∥ 2 \mathcal{L}_{anomaly\_evasion}=\left\|w_{benign}^t-w_{backdoor}^t\right\|_2 Lanomaly_evasion= wbenignt−wbackdoort 2
- 共谋的适应性攻击。目的是通过自适应攻击和共谋攻击相结合,进一步增强攻击的有效性和隐蔽性

无论是语义后门攻击还是像素模式后门攻击,FLMAAcBD都有效减轻了后门的影响。因此,这种攻击策略对防御方法无效。
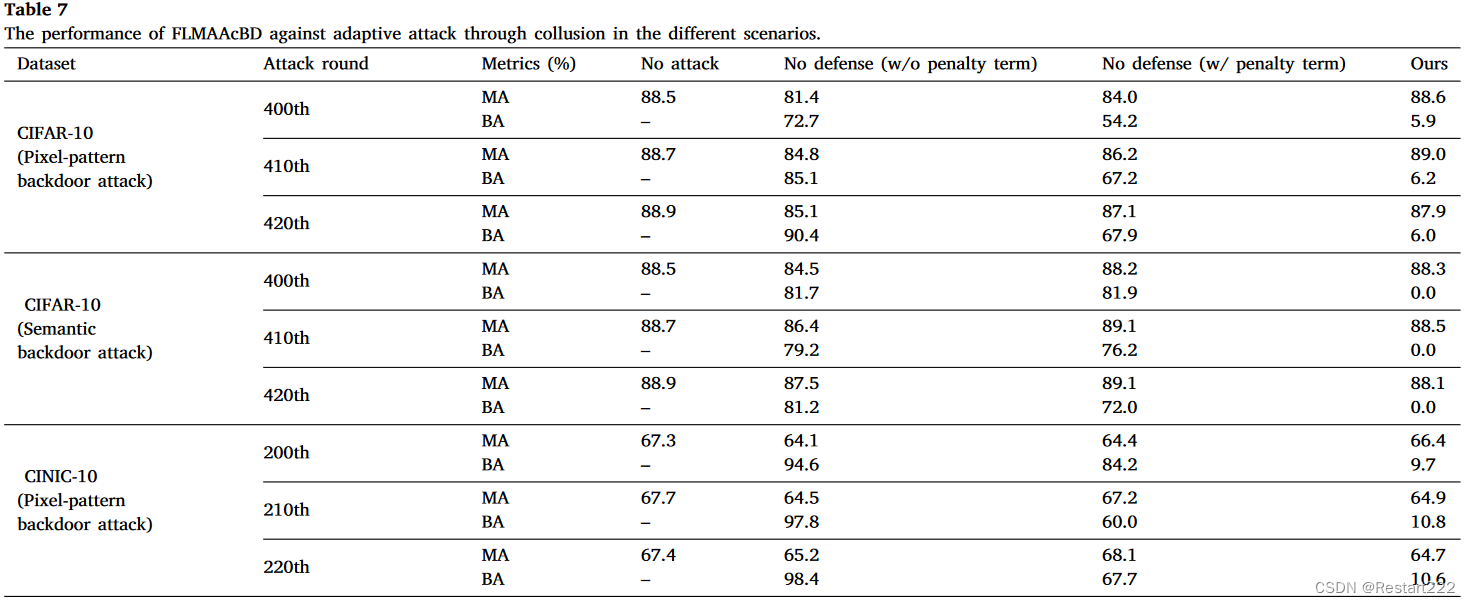
即使攻击者通过共谋完成自适应攻击, FLMAAcBD也可以有效缓解后门攻击,进一步验证了FLMAAcBD的鲁棒性。
DBSCAN 中的参数对 FLMAAcBD 的影响
较大的邻域半径ε使得FLMAAcBD在检测过程中对数据点密度的容忍度更高。虽然较大的ε会降低良性案例的FPR,但也会增加未能检测到后门攻击的风险,而较小的ε则使FLMAAcBD的检测更加严格,使攻击更容易检测到,但也提高了良性案例的FPR。
PCA和DBSCAN的有效性分析
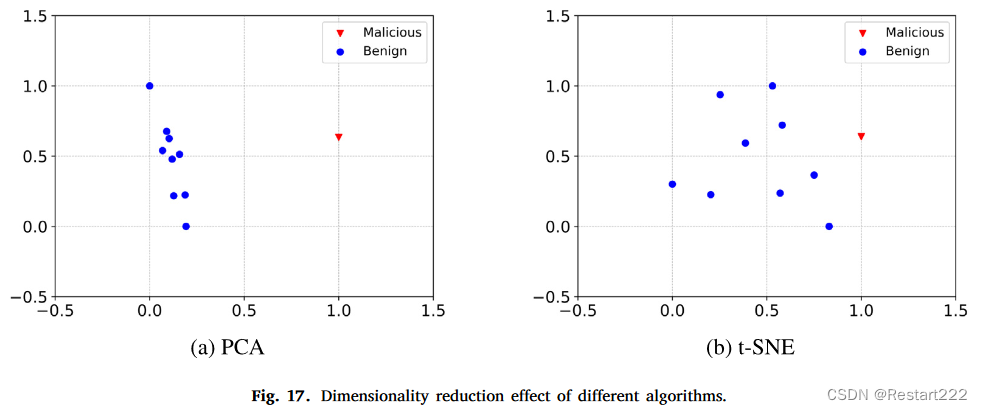
图17(b)显示,当使用t-SNE进行降维时,恶意客户端和良性客户端之间没有明显的区别。然而,在应用 PCA 后(参见图 17(a)),恶意客户端和良性客户端之间存在显着差异。因此,与t-SNE相比,PCA更适合作为数据处理的降维技术。另外,在使用DBCSAN集群之前需要对数据进行降维。这不仅减少了冗余信息并提取更鲁棒的特征,而且还减轻了为 DBSCAN 选择合适的超参数的难度。
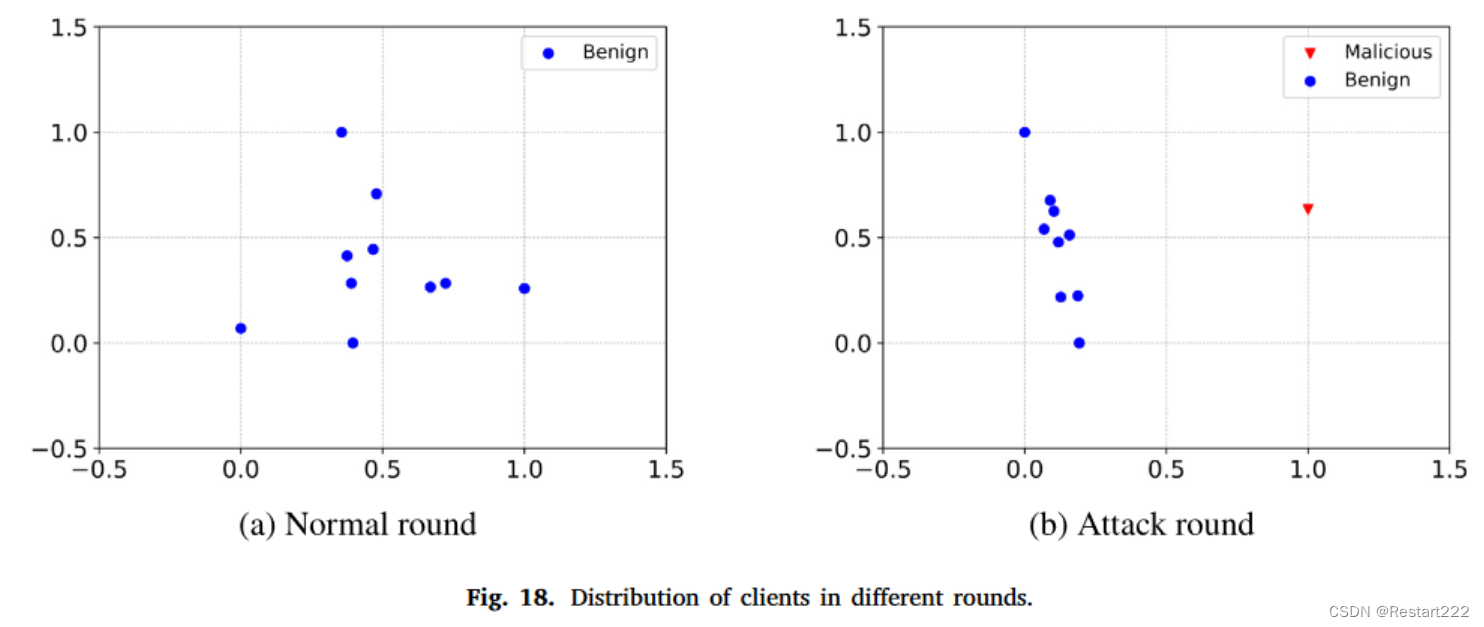
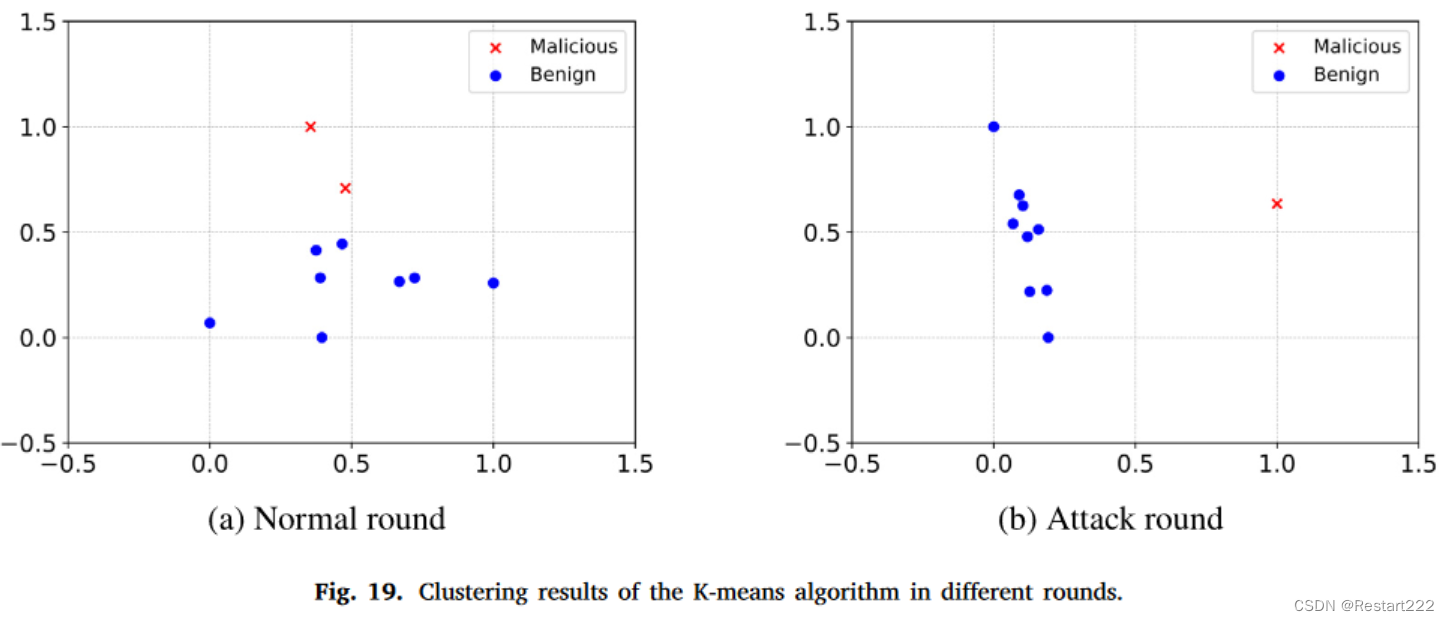
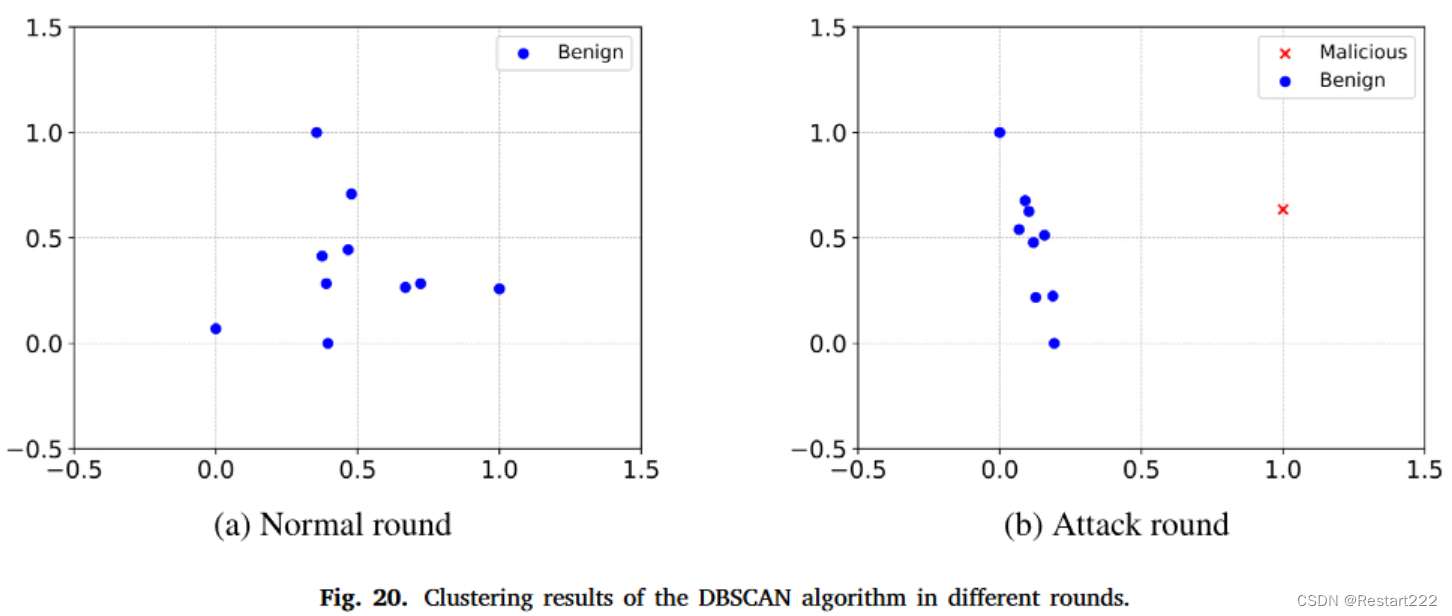
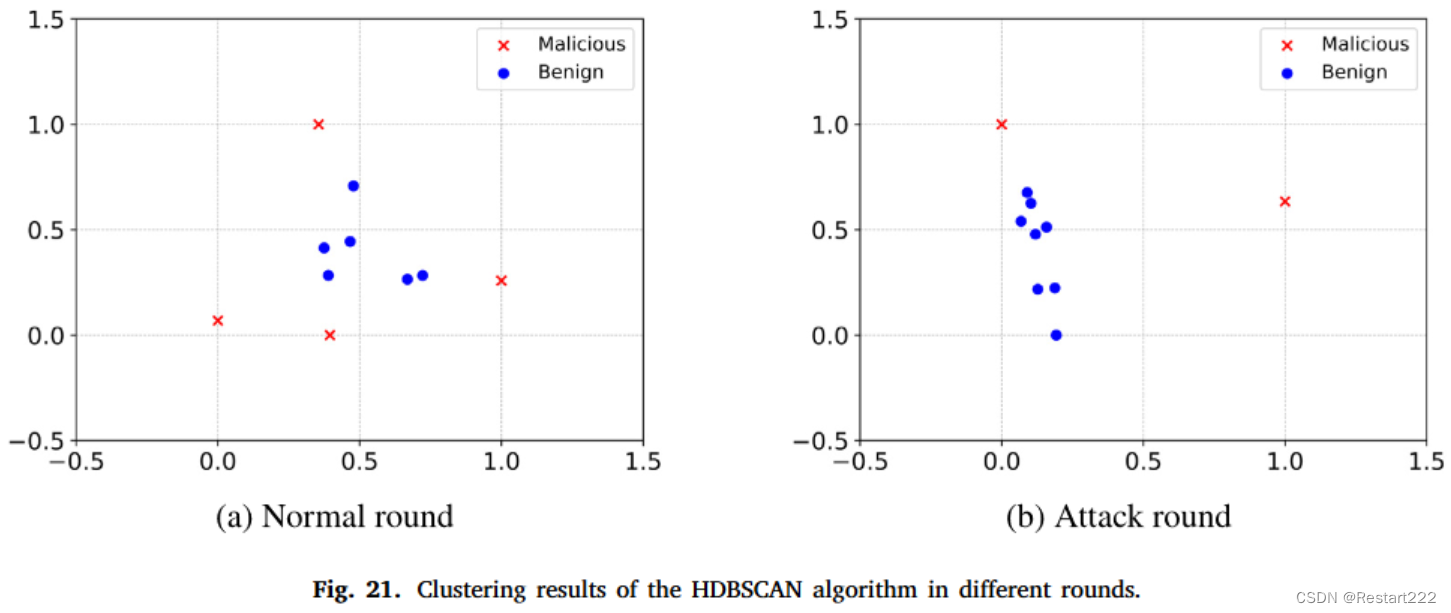
三种聚类算法中,只有DBSCAN的结果与实际情况相符。虽然K-means和HDBSCAN在检测攻击回合中的恶意客户端方面有一定效果,但它们也容易将良性客户端错误地分类为恶意客户端。相比之下,DBSCAN 在保持聚类结果与实际情况的一致性方面表现更好。
非攻击场景下的性能
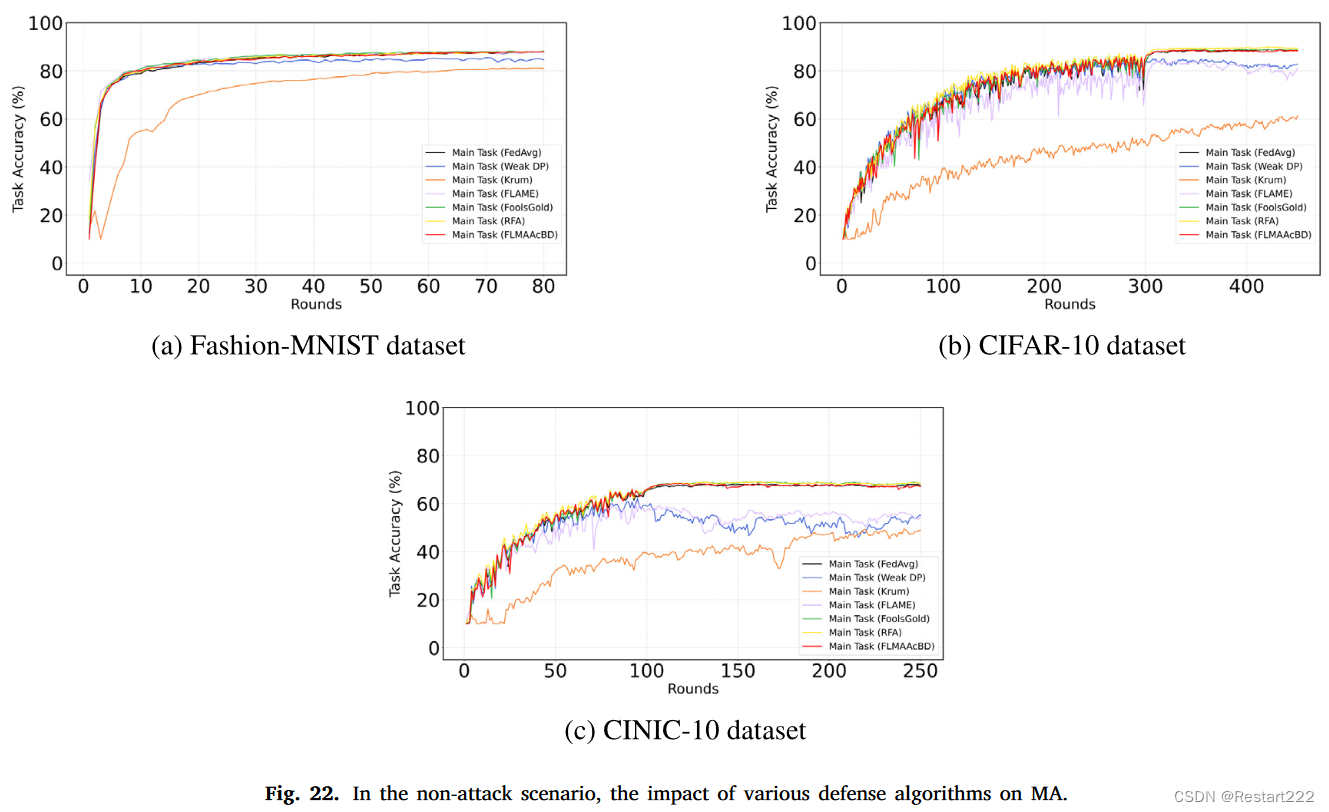
FLMAAcBD对模型的MA几乎没有影响,与FedAvg有类似的训练效果。虽然在某些回合中性能略低于FedAvg(主要是由于FLMAAcBD对正常回合的误判,导致模型参数中注入少量噪声,暂时影响MA),但这种偏差会逐渐恢复正常后续训练中的水平。
运行时开销
计算了服务器端前 10 轮训练的平均运行时间成本。考虑到实际中客户端是并行运行的,将每轮处理时间最长的客户端作为该轮的客户端运行时间。实验主要是为了比较不同算法在客户端(如果适用)和服务器上的总运行时间开销,所以这些实验没有考虑传输成本。

FLMAAcBD的异常检测过程是在客户端和服务器之间串行执行的,这不可避免地增加了额外的运行时开销。然而,与其他防御方法相比,FLMAAcBD有效地减轻了各种场景下的后门攻击,同时保持了全局模型的高水平良性性能。因此,在实际应用中,可以考虑在运行时开销和算法鲁棒性之间取得平衡。
优点
- 利用自适应模型更新裁剪和噪声注入来达到防御目的,解决了过度噪声注入对模型可用性产生负面影响的问题
- 可以在不区分样本类别的情况下识别恶意客户端的异常神经元激活行为
- 不需要对数据分布进行某些假设



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











