







本文主要收集及分类一些比较重要的论文。
蒸馏
参考文档:https://editor.csdn.net/md/?articleId=121592263#_66
《Distilling the Knowledge in a Neural Network》 2015-Hinton
最原始的蒸馏论文。
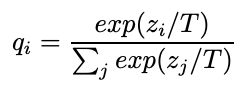
一文搞懂知识蒸馏
《Deep mutual learning》 2017
此方法不再是学生网络学习教师网络,本篇论文打破这种预先定义好的“强弱关系”,提出了一种深度相互学习策略,即一组学生网络在整个训练过程中相互学习。
《Improved Knowledge Distillation via Teacher Assistant》 2019
在较大的teacher和很小的student之间加入容量介于二者之间的Teacher Assistant,teacher先蒸馏TA,TA再蒸馏student。
《FitNets:Hints for thin deep nets》 2015
本篇论文侧重feature蒸馏。为什么要蒸馏feature呢?logits相当于“答案”,feature相当于“思路”。student学习“思路”比学习“答案”容易。FitNets简单来说就是剖开teacher和student的某一层,而让二者这一层的输出间的mse最小。所有之前的工作都是专注于压缩teacher网络到更浅更宽的网络,没有充分利用深度。论文通过利用深度解决网络压缩的问题,提出新方法训练thin and deep网络FitNets。注意:由于这一层feature map的shape不一定一样,student在蒸馏过程中这一层后会接一个wr来调整,蒸馏结束拆掉这一层。
多目标
参考:https://editor.csdn.net/md/?articleId=121170315
mmoe
ESMM
ple
AITM:Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
注意力机制
《Attention is all you need》 谷歌2017
Attention是为了进一步区分特征的不同重要性,为其赋予不同的注意力权值强调不同特征的重要性。
《Transformer》 Google 2017(MHA)
MHA+残差网络+Norm
Transformer 的内部,在本质上是一个 Encoder-Decoder 的结构,即 编码器-解码器。
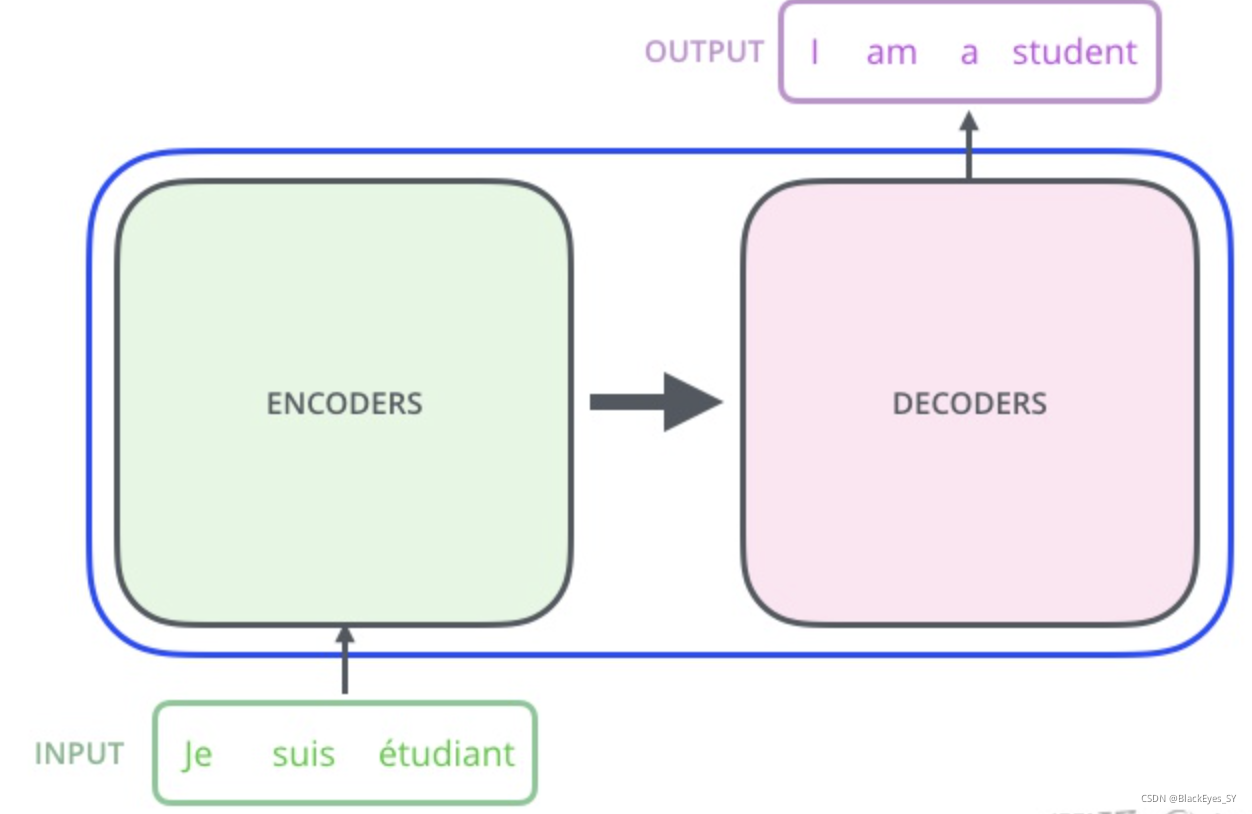
Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
https://chowdera.com/2021/02/20210202073723694h.html
loss
《Asymmetric Loss For Multi-Label Classification》 2020 Alibaba 达摩院
1、一种非对称损失,它在正负样本上有不同的操作。主要针对正负样本不平衡,对loss的影响应该不同。
2、提出硬阈值,硬阈值对正负样本极度不平衡的时候有效。硬阈值从梯度的角度去分析,能够摒弃掉label标错的负样本。
focal loss --困难样本
equal loss --long tail
《Deep Ordinal Regression Network for Monocular Depth Estimation》 --2018 提高auc
特征交互
DCN --2017斯坦福大学&谷歌
Wide&Deep模型的进化,Deep&Cross模型,简称DCN。利用Cross网络代替原来的Wide部分。
PNN 2016 上交
使用乘积层Product Layer,不同特征的Embedding不再是简单的concat,而是用Product操作进行两两交互,更有针对性的获取特征之间的交叉信息。
FM
用户兴趣建模
《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》 MIND 2019 Tmall
《SIM》
Embedding
《Discriminative deep random walk for network classification》2016
《YouTube-Deep Neural Networks for YouTube Recommendations》2016
《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》2018 阿里
嵌入的方法主要来源于DeepWalk。
推荐面临三大技术挑战:
•可扩展性:尽管许多现有的推荐方法在小规模数据集(即数百万用户和项目)上运行良好,但在更大规模的数据集(即10亿用户和20亿项目)上失败。
•稀疏性:由于用户往往只与少量项目交互,因此很难训练出准确的推荐模型,尤其是对于交互次数很少的用户或项目。它通常被称为“稀疏性”问题。
•冷启动:每小时有数百万个新项目被连续上传。这些项目没有用户行为。处理这些项目或预测用户对这些项目的偏好是很困难的,这就是所谓的“冷启动”问题。
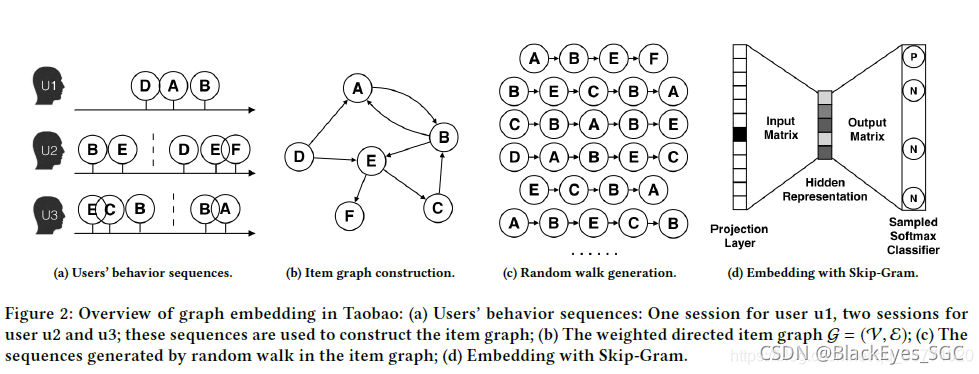
(b)边是购买/浏览/加购顺序,边上的权重是频次。
消除噪声:
1、如果单击后的停留时间少于一秒钟,则单击可能是无意的,需要删除。
2、有些“过度活跃(羊毛党)”的用户实际上是垃圾邮件用户。根据长期观察,如果一个用户在不到三个月的时间内购买了1000件商品或者他/她的点击总数超过3500次,那么这个用户很可能是一个垃圾邮件用户。我们需要过滤掉这些用户的行为。
3、零售商不断更新商品的细节。在极端情况下,一个商品在经过长时间的更新后,可能会成为同一个标识符的完全不同的商品。因此,我们删除与标识符相关的项。
与DeepWalk相比的特色:为了解决冷启动问题,使用冷启动项目附带的Side Information来增强BGE。在电子商务的RS场景中,边信息是指一个商品的类别、商店、价格等,在排名阶段被广泛用作关键特征,但在匹配阶段很少被应用。在图形嵌入中加入侧信息可以缓解冷启动问题。例如,优衣库(同一家店)的两个连帽衫(同一类别)可能看起来很相似,喜欢尼康镜头的人也可能对佳能相机(类似类别和类似品牌)感兴趣。这意味着具有相似边信息的项应该更靠近嵌入空间。
label smooth
分类模型
Deep Residual Learning for Image Recognition何凯明
ltv
《Learning Reliable User Representations from Volatile and Sparse Data to Accurately Predict Customer Lifetime Value》
ltv的挑战:用户的消费行为数据不稳定、噪声、数据稀疏。
为了解决这些问题,本文提出,利用用户收入时间序列、用户属性去学习temporal and structural user representations。temporal representation通过小波变化去学习,structural rep- resentation通过Graph Attention Network (GAT)来学习。
传统的ltv分两类:基于概率的生成方法和基于机器学习的方法。前者主要是预测复购和用户流失,但这种方法依赖先验分布。还有一种角度是把ltv看作一种特殊的时间序列预测任务。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









