




 本文介绍了如何通过配置二级缓存来提升Hibernate应用的性能,并详细解释了缓存配置及使用方法,包括实体类缓存、集合缓存和查询缓存等。
本文介绍了如何通过配置二级缓存来提升Hibernate应用的性能,并详细解释了缓存配置及使用方法,包括实体类缓存、集合缓存和查询缓存等。
二级缓存为了提高数据的效率,但是频繁修改的数据建议不要使用二级缓存,在不适用缓存提供商的情况下使用缓存:
首先session中有一级缓存,在两个session访问数据的时候需要查询两次数据库,这样并不会提高效率,所以需要给hibernate配置二级缓存提高效率
配置项:
<property name="hibernate.cache.provider_class">
org.hibernate.cache.HashtableCacheProvider
</property>
<!-- 需要缓存的实体类的全限定名 -->
<mapping resource=.../>
<class-cache usage="read-write" class="com.heying.query.Department"/>测试:
@Test
public void testGet()throws Exception{
Session session = sessionFactory.openSession();
Transaction tx1 = session.beginTransaction();
Department employee = (Department) session.get(Department.class, 1);
System.out.println(employee.getName());
tx1.commit();
session.close();
Session session2 = sessionFactory.openSession();
Transaction tx2 = session2.beginTransaction();
Department employee2 = (Department) session2.get(Department.class, 1);
System.out.println(employee2.getName());
tx2.commit();
session2.close();
}使用两个事务模拟两次访问,先测试没有使用二级缓存时候:
一次事务执行一次查询语句,可以看到两次查询:

使用耳机缓存后:
第一次访问直接访二级缓存,发现没有找到,就会从数据库中查找,然后把对象放入到二级缓存中,在第二次访问来时,就会直接在二级缓存中找到这个对象,不需要查找数据库。
值得注意的是配置文件中属性的先后顺序,class-cache在mapping之后

如果在实体类里面有一个集合,需要使用到集合缓存,这个集合对应的实体也需要打开缓存
<class-cache usage="read-write" class="com.heying.query.Department"/>
<class-cache usage="read-write" class="com.heying.query.Employee"/>
<collection-cache usage="read-write" collection="com.heying.query.Department.employees"/>使用HQL查询二级缓存:需要开启查询缓存,按照查询条件缓存
执行了update语句后会让二级缓存对应的数据自动失效,第二次使用数据会重新获取(更新时间戳缓存)
<property name="hibernate.cache.use_query_cache">true</property>使用厂商推荐的缓存:
EHCache,OSCache,SwarmCache,Jobss Cache等
EhCache:可作为进程范围的缓存,存放数据的物理介质可以是内存或硬盘,对Hibernate的查询缓存提供了支持。
OSCache:可作为进程范围的缓存,存放数据的物理介质可以是内存或硬盘,提供了丰富的缓存数据过期策略,对Hibernate的查询缓存提供了支持。
SwarmCache:可作为群集范围内的缓存,但不支持Hibernate的查询缓存。
JBossCache:可作为群集范围内的缓存,支持事务型并发访问策略,对Hibernate的查询缓存提供了支持。
介绍EhCache:
使用EhCache缓存必须添加几个jar包:
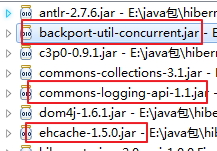
然后就能和之前的一样,也可以配置ehcache.xml,模版在文档中
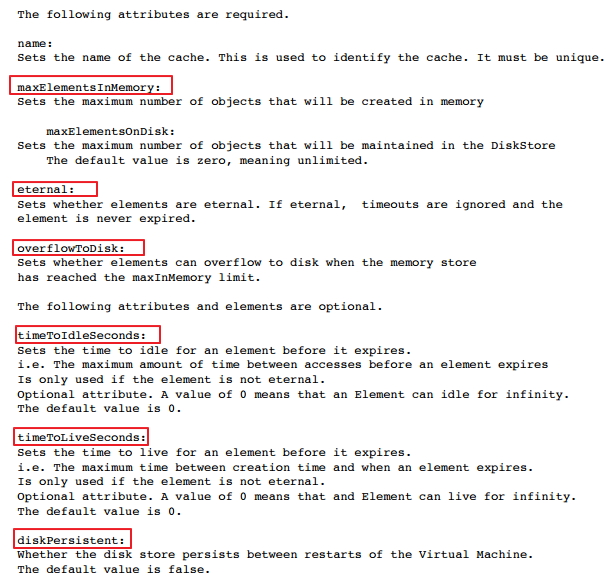
基本配置项参考:
<?xml version="1.0"?>
<ehcache>
<!-- 超过后写入硬盘位置 -->
<diskStore path="c:/cache/"/>
<!--
maxElementsInMemory 最大元素个数
eternal 对象是否永远不变,一般为false
timeToIdleSeconds 缓存创建以后,最后一次访问缓存的日期至失效之时的时间间隔
timeToLiveSeconds 缓存自创建日期起至失效时的间隔时间
overflowToDisk 超出了是否写入硬盘
-->
<defaultCache
maxElementsInMemory="1000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
</ehcache>其他的可以参考官方文档类似

















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









