







终于想开始爬自己想爬的网站了。于是就试着爬P站试试手。
我爬的图的目标网址是:http://www.pixiv.net/search.php?word=%E5%9B%9B%E6%9C%88%E3%81%AF%E5%90%9B%E3%81%AE%E5%98%98,目标是将每一页的图片都爬下来。
一开始以为不用登陆,就直接去爬图片了。
后来发现是需要登录的,但是不会只好去学模拟登陆。
这里是登陆网站https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index的headers,

然后还要去获取我们登陆时候需要的data。点住上面的presevelog,找到登陆的网址,点开查看Form Data就可以知道我们post的时候的data需要什么了。这里可以看到有个postkey,多试几次可以发现这个是变化的,即我们要去捕获它,而不能直接输入。

于是退回到登陆界面,F12查看源码,发现有一个postkey,那么我们就可以写一个东西去捕获它,然后把它放到我们post的data里面。

这里给出登陆界面需要的代码:

愉快地解决完登陆问题之后,就可以开始爬图片啦。
进入target_url:上面的目标网址。
点击目标的位置

点开ul这个标签,发现图片全部都是在<li class="image-item">这里面的,因为我们要爬大一点的图(爬个小图有什么用啊!),所以还要进入一层第一个链接的网址去获取大图,我们可以发现我们只要在main_url((http://www.pixiv.net)),再加上第一个href,就可以跑到图片所在的网址了,于是我们先跳转到图片网址看看怎么提取图片。

发现图片就躺在这里了,而且连标题都有,直接方便了我们存图的名字了。于是我们就可以直接去提取图片了。
注意我们在请求获取图片的时候要加一个referer,否则会403的。referer的找法就和上面一样。
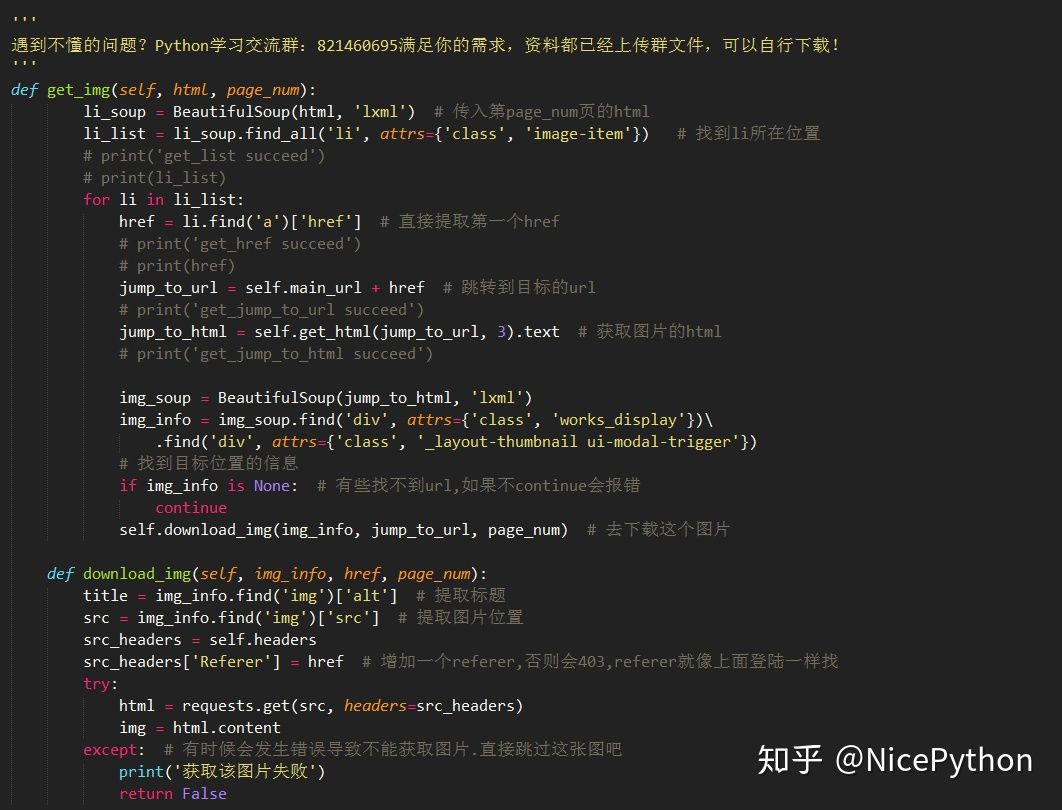
接下来轮到下载图片了。这个之前还不怎么会,临时学了一下。
首先是创建文件夹,我这里是每一页就开一个文件夹。


这样我们的大体工作就做完了。剩下的是写一个work函数让它开始跑。

启动!
大概跑了10页之后,会弹出一大堆信息什么requests不行怎么的。问了下别人应该是被反爬了。
于是去搜了一下资料,http://cuiqingcai.com/3256.html,照着他那样写了使用代理的东西。(基本所有东西都在这学的)。
于是第一个小爬虫就好了。不过代理的东西还没怎么懂,到时候看看,50页爬了两个多钟。
对了。可能网站的源代码会有改动的。因为我吃完饭后用吃饭前的代码继续工作的时候出错了,然后要仔细观察重新干。
















 4717
4717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









