







一 、你在开发Flink任务时,有没有遇到过背压问题,你是如何排查的?
1. 背压产生的原因
背压常常出现在大促或者一些热门活动等场景中, 在上面这类场景中, 短时间内流量陡增导致数据的堆积,系统整体的吞吐量无法提升。
2. 监控背压方法
可以通过 Flink Web UI 发现背压问题。
Flink 的 TaskManager 会每隔 50 ms 触发一次反压状态监测,共监测 100 次,并将计算结果反馈给 JobManager,最后由 JobManager 进行计算反压的比例,然后进行展示。
这个比例的计算逻辑如下:

3. 反压问题的定位与处理
Flink出现背压一般可以从下面三个方面进行问题定位
a. 数据倾斜
可以在 Flink 的后台管理页面看到每个 Task 处理数据的大小。当出现数据倾斜时,可以从页面上明显的看到一个或者多个节点处理的数据量远大于其他节点。这种情况一般是在使用KeyBy等分组聚合算子时,没有考虑到可能出现的热点Key。这种情况需要用户对导致倾斜的热点Key做预处理。
b. 垃圾回收机制(GC)
不合理的设置 TaskManager 的垃圾回收参数会导致严重的 GC 问题,可以通过 -XX:+PrintGCDetails 指令查看 GC 的日志。
c. 代码本身
用户因为未深入了解算子的实现机制而错误地使用了 Flink 算子,导致性能问题。我们可以通过查看运行机器节点的 CPU 和内存情况定位问题
二、一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
结论:一个 Flink 任务可以同时有事件时间窗口,又有处理时间窗口。
那么有些小伙伴们问了,为什么我们常见的 Flink 任务要么设置为事件时间语义,要么设置为处理时间语义?
确实,在生产环境中,我们的 Flink 任务一般不会同时拥有两种时间语义的窗口。
那么怎么解释开头所说的结论呢?
这里从两个角度进行说明:
1.⭐ 我们其实没有必要把一个 Flink 任务和某种特定的时间语义进行绑定。对于事件时间窗口来说,我们只要给它 watermark,能让 watermark 一直往前推进,让事件时间窗口能够持续触发计算就行。对于处理时间来说更简单,只要窗口算子按照本地时间按照固定的时间间隔进行触发就行。无论哪种时间窗口,主要满足时间窗口的触发条件就行。
2.⭐ Flink 的实现上来说也是支持的。Flink 是使用一个叫做 TimerService 的组件来管理 timer 的,我们可以同时注册事件时间和处理时间的 timer,Flink 会自行判断 timer 是否满足触发条件,如果是,则回调窗口处理函数进行计算。需求:数据源:用户心跳日志(uid,time,type)。计算分 Android,iOS 的 DAU,最晚一分钟输出一次当日零点累计到当前的结果。
3.⭐ 实现方式 1:cumulate 窗口

-
优点:如果是曲线图的需求,可以完美回溯曲线图。
-
缺点:大窗口之间如果有数据乱序,有丢数风险;并且由于是 watermark 推动产出,所以数据产出会有延迟。
1.⭐ 实现方式 2:Deduplicate

-
优点:计算快。
-
缺点:任务发生 failover,曲线图不能很好回溯。没法支持 cube 计算。
1.⭐ 实现方式 3:group agg
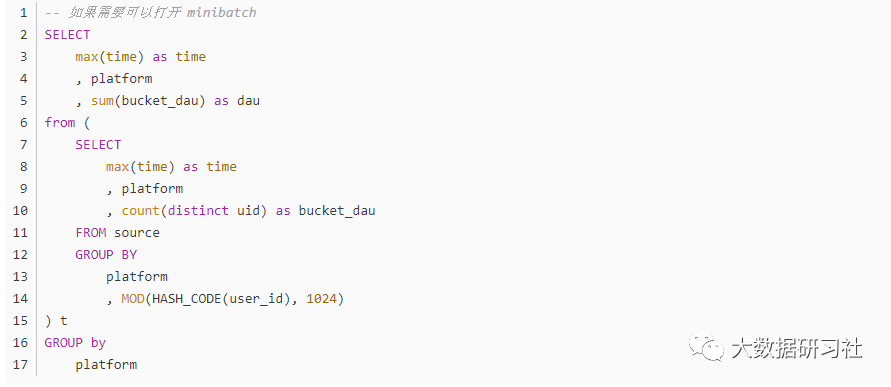
-
优点:计算快,支持 cube 计算。
-
缺点:任务发生 failover,曲线图不能很好回溯。
三、Flink是如何支持批流一体的?
Flink 通过一个底层引擎同时支持流处理和批处理。
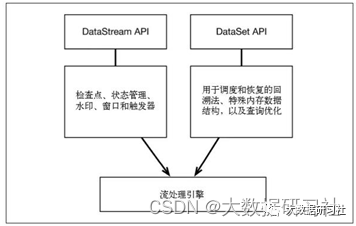
在流处理引擎之上,Flink 有以下机制:
1.检查点机制和状态机制:用于实现容错、有状态的处理;
2.水印机制:用于实现事件时钟;
3.窗口和触发器:用于限制计算范围,并定义呈现结果的时间。
在同一个流处理引擎之上,Flink 还存在另一套机制,用于实现高效的批处理。
1.用于调度和恢复的回溯法:由 Microsoft Dryad 引入,现在几乎用于所有批处理器;
2.用于散列和排序的特殊内存数据结构:可以在需要时,将一部分数据从内存溢出到硬盘上;
3.优化器:尽可能地缩短生成结果的时间。
四、Flink任务延迟高,想解决这个问题,你会如何入手?
在Flink的后台任务管理中,我们可以看到Flink的哪个算子和task出现了反压。最主要的手段是资源调优和算子调优。
资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。
作业参数调优包括:并行度的设置,State的设置,checkpoint的设置。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









