







1. 并行度理解
Spark作业中,各个stage的task的数量,代表Spark作业在各个阶段stage的并行度。 分为资源并行度(物理并行度)和数据并行度(逻辑并行度)
在Spark Application运行时,并行度可以从两个方面理解:
1、资源的并行度:由节点数(executor)和CPU数(core)决定
2、数据的并行度:task数量和partition大小
task又分为map时的task和reduce(shuffle)时的task;
task的数目和很多因素有关系,比如:资源的总core数、spark.default.parallelism参数、spark.sql.shuffle.partitions参数、读取数据源的类型、shuffle方法的第二个参数、repartition的数目等等。
如果Task的数量越多,能用的资源也多,那并行度自然就好。如果Task的数据少,资源很多,有一定的浪费,但是也还好。如果Task数目很多,但是资源少,那么会执行完一批,再执行下一批,自然会慢一些。所以官方给出的建议是,这个Task数目是core总数的2~3倍为最佳(最大压榨CPU处理能量)。如果core有多少Task就有多少,那么有些比较快的task执行完了,一些资源就会处于等待的状态。
如何设置task数量:
将task数量设置成与Application总CPU core数量相同(理想情况下,150个core分配150个task),官方推荐设置成Application总CPU 从热数量的2~3倍(150个CPU core,设置300~500个task);
与理想情况不同的是:有些task会运行的快一些,比如50秒就完了,也有些task可能会慢一点,要几分钟才能完成,所以如果你的task数量,刚好设置跟CPU core数量相同,也可能会导致资源的一定浪费,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个core会处于等待状态。
2. 设置Application并行度
参数spark.default.parallelism默认是没有值的,如果设置了值,是在shuffle的过程才会起作用
new SparkConf().set("spark.default.parallelism","10")
// rdd2的分区数就是10,rdd1的分区数不受这个参数的影响
val rdd2 = rdd1.reduceByKey(_+_)
如何根据数据量(task数目)配置资源
当提交一个Spark Application时,设置资源信息如下,基本已经达到了集群或者yarn队列的资源上限:
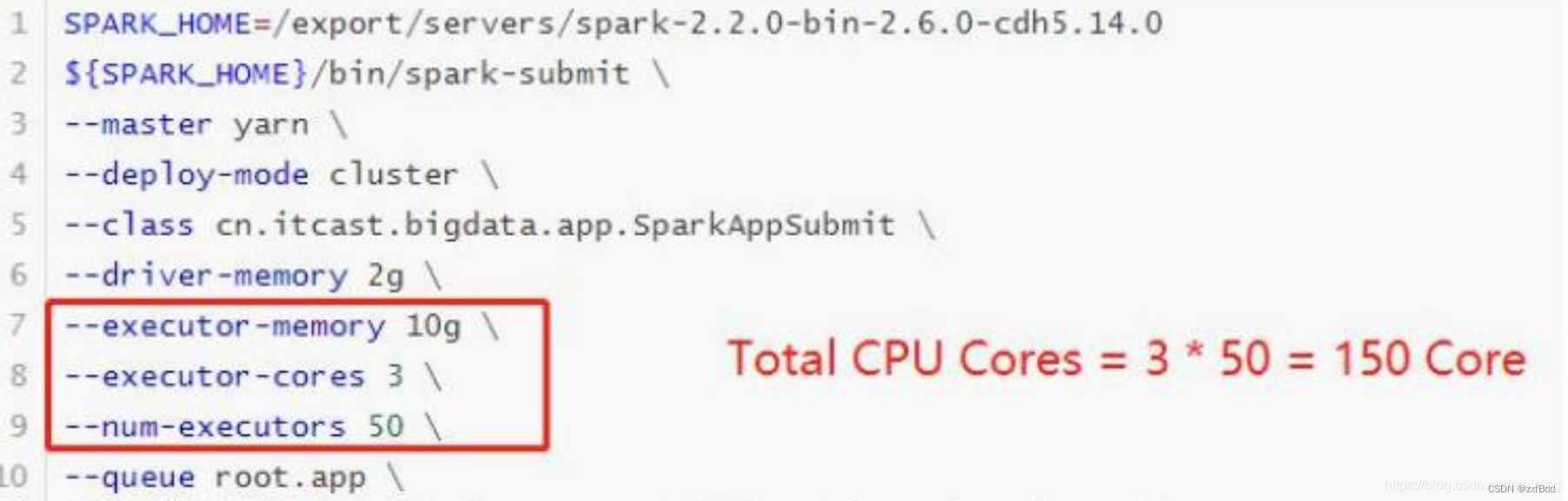
task没有设置或者设置的很少,比如为100个task,平均分配一下,每个executor分配到2个task,每个executor剩下的一个CPU core就浪费掉了!
虽然分配充足了,但是问题是:并行度没有与资源相匹配,导致分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源。可以调整task数目,按照原则:Task数量,设置成Application总CPU core数量的2~3倍

实际项目中,往往依据数据数量(task数目)配置资源















 6314
6314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









