







简介: 如何查看spark与hadoop、kafka、Scala、flume、hive等兼容版本【适用于任何版本】
方法
当我们安装spark的时候,很多时候都会遇到这个问题,如何找到对应spark的各个组件的版本,找到比较标准的版本兼容信息。答案在spark源码中的pom文件。首先我们从官网下载源码。进入官网
http://spark.apache.org
选择download,然后我们看到下面内容
# Master development branch git clone git://github.com/apache/spark.git # Maintenance branch with stability fixes on top of Spark 2.2.0 git clone git://github.com/apache/spark.git -b branch-2.2

我们看到上面需要使用git下载。
如果你是window,那么可以装一个Linux虚拟机,或则直接在window上安装。window安装遇到的问题可参考
win7安装 git软件下载以及遇到的问题解决解决方法
http://www.aboutyun.com/forum.php?mod=viewthread&tid=8521
这里使用Linux安装,更加方便。执行下面命令
sudo yum install perl openssh git -y
上面安装完毕,下载源码
git clone git://github.com/apache/spark.git
当然如果你不想这么麻烦,只想查看pom.xml文件,也可以直接访问
github.com/apache/spark.git
然后打开pom.xml即可
https://github.com/apache/spark/blob/master/pom.xml
这时候我们可以查看里面的兼容信息spark的版本为2.3.0-SNAPSHOT
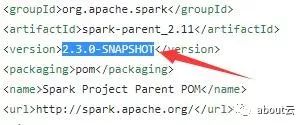
接着我们找到里面有各种所需软件的信息,比如
jdk1.8,hadoop位2.6.5,2.7.1,2.7.3。
flume版本为flume1.6.0,
zookeeper版本为3.4.6
hive为:1.2.1
scala为:2.11.8
这样我们在安装的时候就找到它们版本兼容的依据。
当然官网提供一种编译的版本,剩下的需要我们自己编译。下一篇我们讲该如何编译我们想要的版本。
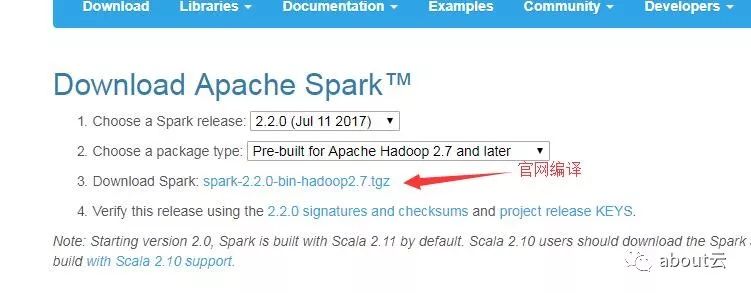
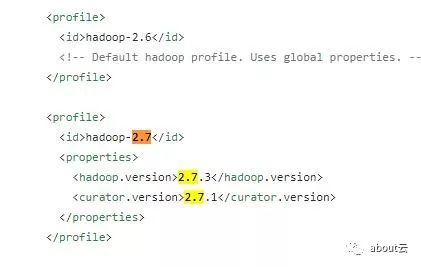
这里需要说明的一个地方即maven的profile,是为了适应不同的版本。我们在编译的时候,可以通过-P指定版本















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









