










伴随着计算机、互联网等技术的发展,用户对系统低延时的要求越来越高,媒体直播、证券报价、社交类软件、当前作为技术热点的大数据处理,各行各类的应用都需要不断优化其低延时架构。低延时系统架构优化经久不衰,其目的是提高用户体验,吸引客户,并最终直接或者间接的创造价值。
一、低延时架构的核心思想及解决的问题
低延时系统架构不断优化和发展,并呈现螺旋式上升的状态,其核心思想主要有三个:
1、 尽可能减少网络中转环节,提高网络速度。减少跳点;增加带宽,使用千兆、万兆网卡,甚至InfiniBand。
2、 尽可能的提高数据处理速度,提高处理器速度,使用内存计算技术,使用并行计算等高性能处理技术。
3、 尽可能的减少磁盘IO操作、同步操作等,以降低接口延迟。
在架构不断优化的过程中,需要不断解决的问题包括:
1、 数据可靠性。在尽量减少数据落地(不一定没有)的情况下,保证数据不丢失。采用异步写磁盘、HA等技术保证数据可靠性。
2、 吞吐量。对大规模的数据应能保证数据处理速度,分布式计算的协调和架构。
3、 高可用、容错等。
三低延时架构演化概述
低延时架构的演化是伴随着计算机软硬件行业的发展,各行各业的需求发展起来的,我们以证券行业中的行情报价为例,管中窥豹,来看一下低延时机构的演化历史
1、 早期架构模型
在最初的硬件资源匮乏的年代,数据的接入处理发布都部署在一起,减少各种IO操作,充分利用有限的资源,保证系统的运行。如图1所示:
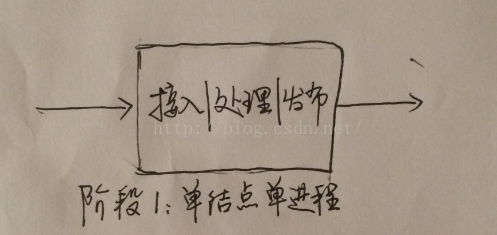
图1最简单模型
早期架构的演化中,更为成型的一个系统架构模型如图2所示,系统内各进程之间IPC进程通信如共享内存技术等进行数据的交互,数据的接入部分引入缓冲队列模型,以避免网络拥堵或丢包,同时具备缓冲功能,提高系统的吞吐压力。比如流媒体模型中通过时间戳序列号等标识配合数据重传等保证数据的可靠。
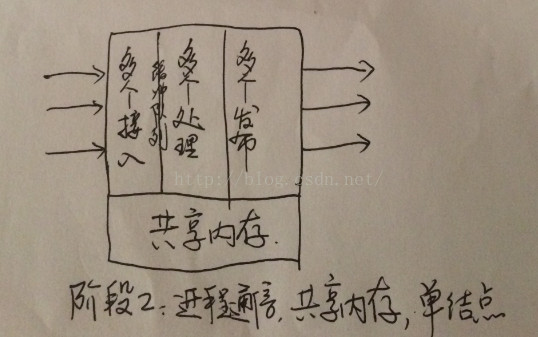
图2早期通用的成熟架构
关于这一部分,笔者曾有幸拜读过国内最早一代证券行情报价系统的部分核心代码,并曾与早在90年代便从事该行业的第一代程序员共事。在感叹这位前辈职业精神的同时,更是感叹这部分系统架构的魅力。所谓没有最好的架构,只有最合适的架构,限于当时各种环境和资源,架构师要充分考虑系统的可用性和成本,对一点一滴细节的把握已经到了极致。主要体现在以下几点:
第一个是基于内存文件的数据计算和管理。通过哈希链表的方式自组织内存数据,实现增删改查等操作,同时通过内存文件和磁盘文件的映射机制,实现内存数据的持久化备份,并解决读写锁机制等核心问题,这些实际都是内存数据库的一种简单实现,像FastDB等。极大提高数据计算和共享的速度。
第二个是高并发异步服务框架。基于C、C++语言的异步Socket完成,实现稳定可靠的高并发的服务要求。在行业发展的过程中,出现的其他高性能网络框架如ACE、Libev等一直是数据类、游戏类服务使用的基础框架。使用C\S架构,并通过数据推送技术尽快的将有效数据发送到客户端。所有实时数据都是采用流的方式进行处理和发送,这也是早期流式计算的雏形。即使在B\S大行其道的很长时间内,这种架构仍然是对低延时需求最合理的解决方案。在HTML5中出现的WebSocket技术,实际上是完善BS架构在实时数据方面表现的不足。
第三个是消息对列缓冲技术。当然只是用来做缓冲,不像今天的消息中间件具有那么多的强大功能。通过基本的数组或链表等结构,实现数据缓冲,提高系统的吞吐能力。值得一提的是对于有些采用非可靠传输协议(UDP、RDP等)的系统,通过时间戳或序列号等方式,实现数据重传机制,保证数据的完整性,如一些视频直播系统或流媒体系统。
第四个是文件系统。以低成本来完成数据的存储和组织,并实现检索和装载等。和上述所有环节一起,不使用数据库或第三方的软件产品,第一是降低成本,第二便是部署运维简单。当然,前提是系统具有强大的稳定性。
第五个必须要提强大的编程语言,C\C++。用最靠近系统底层、最高效的语言,完美实现上述四点。提供高性能和计算效率,提供低存储结构。在这些系统的代码中,处处可见存储计算的优化,掩码、位运算、二进制传输、浮点型与长整形转换,甚至部分核心模块采用汇编语言。
2、 较为成熟的架构体系
早期的架构体现了其技术特点,也存在一些问题:系统的扩展性、开放性、数据的再利用,这些与过去兴起的SOA观念看起来格格不入。随着消息中间件、内存数据库、分布式计算等更多商业化产品或者更多互联网技术的飞速发展,低延时系统主要呈现如下样貌:
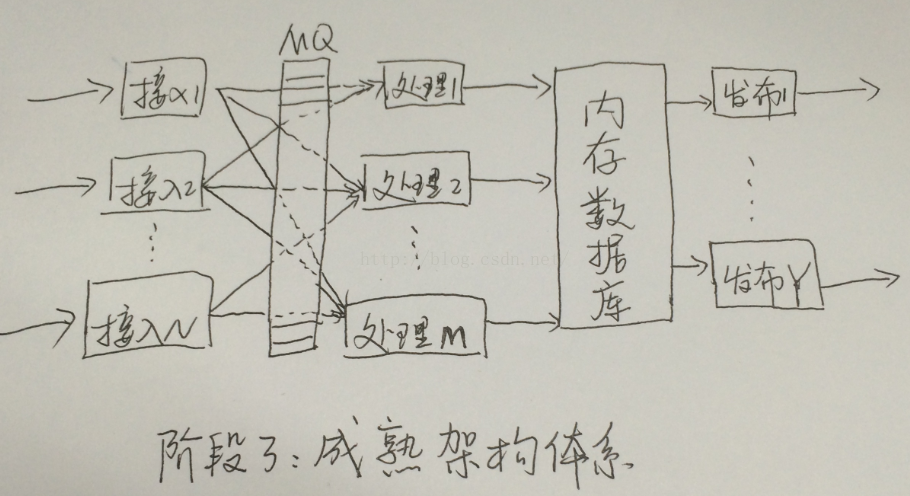
图3成熟机构体系
消息队列中间件MQ技术主要用于解决缓冲、解耦、数据可靠性、一致性等问题,并可通过发布订阅等机制完成系统的分布式扩展和数据的分布式处理,可以提供峰值处理能力。消息队列产品众多,商业化产品有IBM MQ、Tibco等,开源产品则层出不穷,各有优势,如ActiveMQ、RabbitMQ、ZeroMQ,以及大数据处理中使用的Kafka、RocketMQ等技术。举例来讲,对数据可靠性要求不高,保证最快速度获得最新数据的情形,Tibco的RV产品无人能出其右,其组播机制能快速实现数据的分享,同时通过硬件产品、基于内存的消息交换技术、InfiniBand技术等,始终走在低延时技术的前沿。而对数据可靠性等有一定要求的情形,IBM WMQ、RabbitMQ等具有较高的效率。关于消息中间件技术的相关比较和分析,我们将在《低延时系统架构(二)消息队列技术分析》中进行探讨。
内存数据库技术主要用于解决数据缓存、组织与管理、提高查询和访问效率等。像关系型的包括Oracle TimesTen,Altibase、SAP Hana、IBM SolidDB、开源的FastDB等。像非关系型基于KV的缓存产品有Redis、MongoDB等。另外,分布式缓存产品如GemFire等也逐渐开拓新的领域。内存数据库比较的主要参数包括,数据量、数据读写速度、接口形式、数据持久化方式、与传统数据库的数据同步接口等。这部分工作我们将在后续进行探讨。
消息队列技术和内存数据库技术的发展为低延时系统架构提供了技术基础,极大的提升了系统的可扩展性、稳定性、可靠性。在成熟的架构体系中,MQ分布于各个环节之间,形成流式分布的形式,各节点即是消费者同时又是生产者,最终将结果数据等写入内存数据库。或直接通过实时的方式发布出去。
3 流式实时分布式计算架构体系
在后摩尔定律时代,伴随数据吞吐量的增多、大数据处理的需求,分布式流式计算框架逐渐兴起。大数据计算主要有批量计算和流式计算两种形态,如何构建低延迟、高吞吐且持续可靠运行的大数据流式计算系统是当前亟待解决的问题,流式大数据所呈现出的实时性、易失性、突发性、无序性、无限性等特征,在系统结构、数据传输、应用接口、高可用技术、可伸缩性、系统容错、状态一致性、负载均衡、数据吞吐量等方面提出了技术挑战。
在第2节的架构体系之上,进一步考虑系统的吞吐,将分布式消息队列技术、分布式内存数据库技术、分布式计算协调调度等技术进行综合应用,便形成了流式计算的架构体系,在这个过程中出现了分布式消息队列如Kafka技术、分布式协调框架如ZooKeeper等技术。其中值得一提的是zeromq,虽然它不是传统意义的消息队列,但是为数据分发订阅,流式处理等提供了很多可以扩展的模型,包括PUSH|PULL、PUB|SUB、Forward、Route等。通过IPC或者网络分发机制,实现了线程、进程、主机之间的弹性伸缩。
实时流式计算框架的代表主要有Spark和Storm。以Storm为例,说明其流式特点,
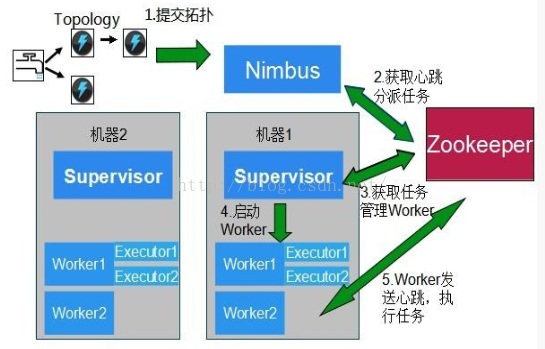
限于篇幅,我们将于后续章节对流式计算技术进行详细比较和分析。















 2826
2826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









