






1 前言
2012年我在北京组织过8期machine learning读书会,那时“机器学习”非常火,很多人都对其抱有巨大的热情。当我2013年再次来到北京时,有一个词似乎比“机器学习”更火,那就是“深度学习”。
本博客内写过一些机器学习相关的文章,但上一篇技术文章“LDA主题模型”还是写于2014年11月份,毕竟自2015年开始创业做在线教育后,太多的杂事、琐碎事,让我一直想再写点技术性文章但每每恨时间抽不开。然由于公司在不断开机器学习、深度学习等相关的在线课程,耳濡目染中,总会顺带学习学习。
我虽不参与讲任何课程(我所在公司“七月在线”的所有在线课程都是由目前讲师团队的17位讲师讲),但依然可以用最最小白的方式 把一些初看复杂的东西抽丝剥茧的通俗写出来。这算重写技术博客的价值所在。
在dl中,有一个很重要的概念,就是卷积神经网络CNN,基本是入门dl必须搞懂的东西。本文基本根据斯坦福的机器学习公开课、cs231n、与七月在线寒老师讲的5月dl班第4次课CNN与常用框架视频所写,是一篇课程笔记。一开始本只是想重点讲下CNN中的卷积操作具体是怎么计算怎么操作的,但后面不断补充,故写成了关于卷积神经网络的通俗导论性的文章。
有何问题,欢迎不吝指正。
2 人工神经网络
2.1 神经元
神经网络由大量的神经元相互连接而成。每个神经元接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,从而进行非线性变换后输出。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。
举个手写识别的例子,给定一个未知数字,让神经网络识别是什么数字。此时的神经网络的输入由一组被输入图像的像素所激活的输入神经元所定义。在通过非线性激活函数进行非线性变换后,神经元被激活然后被传递到其他神经元。重复这一过程,直到最后一个输出神经元被激活。从而识别当前数字是什么字。
神经网络的每个神经元如下
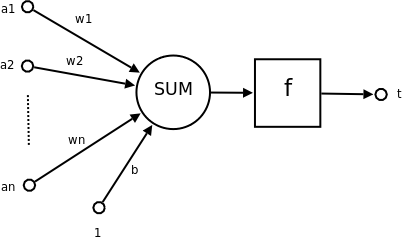
类似wx + b的形式,其中
- a1~an为输入向量,当然,也常用x1~xn表示输入
- w1~wn为权重
- b为偏置bias
- f 为激活函数
- t 为输出
如果只是上面这样一说,估计以前没接触过的十有八九又必定迷糊了。事实上,上述简单模型可以追溯到20世纪50/60年代的感知器,可以把感知器理解为一个根据不同因素、以及各个因素的重要性程度而做决策的模型。
举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有3个因素,这三个因素可以对应三个输入,分别用x1、x2、x3表示。此外,这三个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2、w3表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便天气不好、没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示:
- x1:是否有喜欢的演唱嘉宾。x1 = 1 你喜欢这些嘉宾,x1 = 0 你不喜欢这些嘉宾。嘉宾因素的权重w1 = 5
- x2:天气好坏。x2 = 1 天气好,x2 = 0 天气不好。天气权重w2 = 2。
- x3:是否有人陪你同去。x3 = 1 有人陪你同去,x2 = 0 没人陪你同去。是否有陪同的权重w3 = 3。
2.2 激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全链接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下
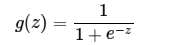
其中z是一个线性组合,比如z可以等于:w0 + w1*x1 + w2*x2。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。
因此,sigmoid函数的图形表示如下:
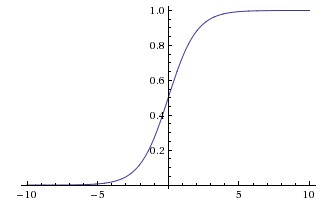
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。输入非常大的正数时,输出结果会接近1,而输入非常大的负数时,则会得到接近0的结果。
压缩至0到1有何用处呢?用处是这样一来变可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
2.3 神经网络
将下图的这种单个神经元
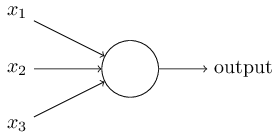
组织在一起,便形成了神经网络。下图便是一个三层神经网络结构
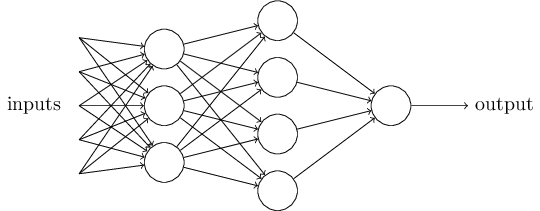
上图中最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。
啥叫输入层、输出层、隐藏层呢?
- 输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
- 输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
- 隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。比如下图中间隐藏层来说,隐藏层的3个神经元a1、a2、a3皆各自接受来自多个不同权重的输入,接着,a1、a2、a3又在自身各自不同权重的影响下 成为的输出层的输入,最终由输出层输出最终结果。
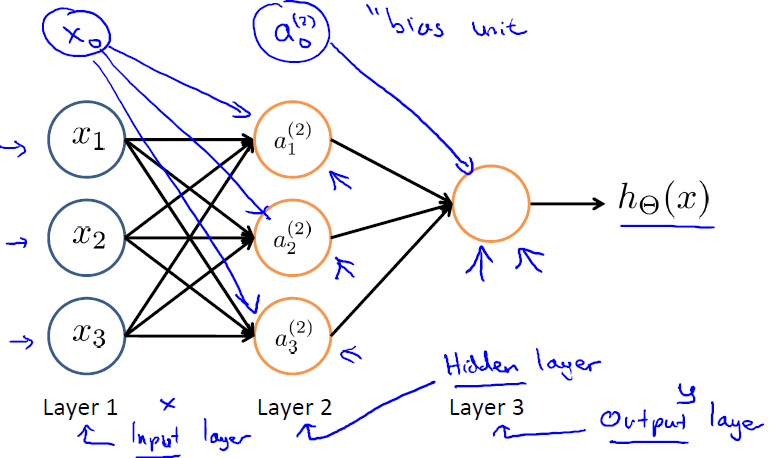
上图(注:图引自斯坦福机器学习公开课)中
表示第j层第i个单元的激活函数
表示从第j层映射到第j+1层的控制函数的权重矩阵
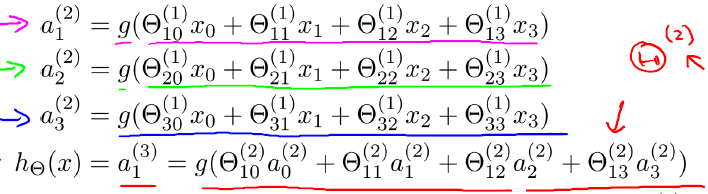
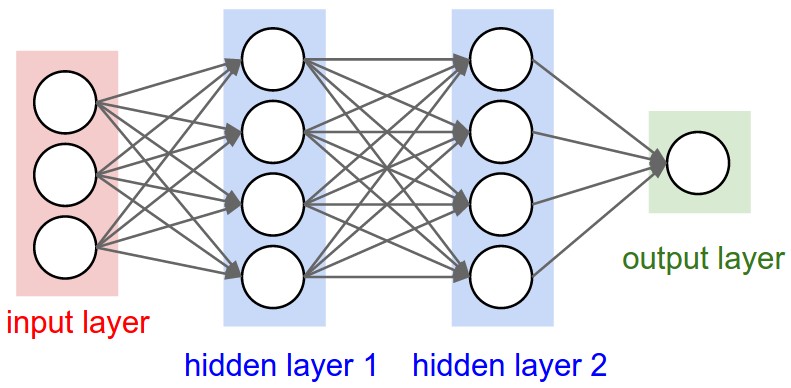
此外,上文中讲的都是一层隐藏层,但实际中也有多层隐藏层的,即输入层和输出层中间夹着数层隐藏层,层和层之间是全连接的结构,同一层的神经元之间没有连接。















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









