







很多普通玩家对工程线的定义还停留在早期短接红绿端的操作认知上。例如这个

常规制作工程线
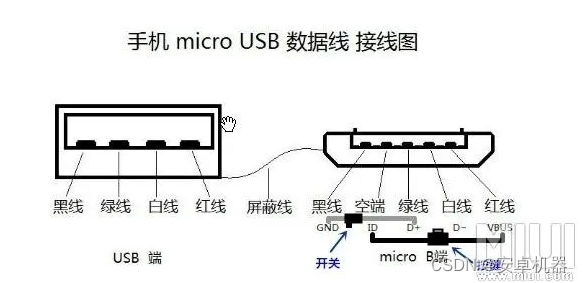

或者短接主板触点方式

今天给大家描述的是更高级改良型的工程线。因为前期的这种工程线对于米6或者其他同时期机型已经不起任何作用。后期机型进入高通edl模式就需要拆机手动短接主板触点来进入。或者有权限的操作来进入edl模式。对于新手来说还是有一定的困难。目前很多维修加密狗或者某宝等有这种工程线出售,那么久其原理也很简单,但需要一定的手工操作。
早期的工程线定义与Testpoint模式。但已在 2021 年 8 月/9 月更新到最新的安全补丁级别的安卓10或后续的更高的版本不在单独的Testpoint上验证。而是引入了一种特殊的方法来检测手机软件和安全区域。这个就是旧版工程线无法起作用的原因之一
EDL模式也被称为手机的紧急模式。从技术上讲,所有小米 Redmi 设备或者任何高通芯片的机型上都带有 EDL 模式选项。如果你想安装 救砖或者更新你自己的 高通手机,那么你有很多选择可以使用.恢复模式或使用快速启动模式在设备上刷新新的库存 ROM。这两种方法都有一些限制,比如Recovery ROM只能用于更新高版本,不能降级小米版本。

操作所需要的工具和配件
数据线
电阻器 10k 和 56K 欧姆
焊接材料(焊枪、焊锡、焊膏等)
黄色线表示 CC 引脚,红色线表示 VBUS
CC2 引脚和 VBUS 之间的 56K 电阻
CC1 引脚和 VBUS 之间的 10K 电阻
目前这种改良型工程线测试通过
测试了一些机型:
小米9 小米
小米9 Pro 5G
小米10
小米10 S
小米11 Pro
小米11 Ultra
小米12 小米
小米MIX4
小米米 CC9 Pro
红米K20
红米K20 Pro
红米K30 4G
红米K30 5G
红米K30 Pro
红米K40
红米Note 9 Pro
红米Note 9
华为荣耀Magic3
华为荣耀Magic3 Pro
华为P50
华为P50 Pro
华为P50 Pocket
华为NOVA 9华为
NOVA 9 Pro
华为Hi NOVA 9
华为Hi NOVA 9 Pro
等等一些机型
最后提示。对于新手来说。有一定的风险性。新手还是建议买成品。这种操作还是对有手动经验强和有一定的硬件知识的朋友操作。
如果对于你有帮助,可以伸出你那可爱的双手点个赞赞吗。关注我 了解搞机玩机一些经验和解决方法.


















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











