







基于用户评分和用户属性的协同过滤混合推荐算法实现
一、基于用户评分的协同过滤推荐算法
实现步骤:
1、构建用户-电影评分矩阵(movielens数据集),如下图:

2、计算目标用户与其他用户的相似度,如下图:

3、获取KNN个最近邻,如下图:
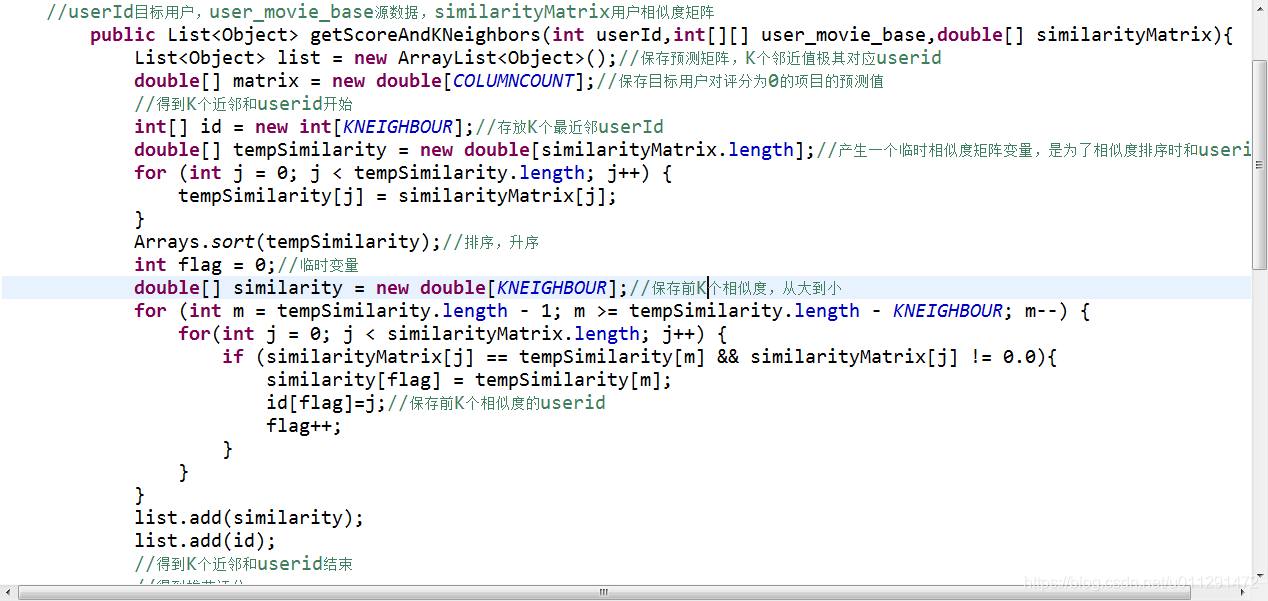
4、计算推荐结果,如下图:
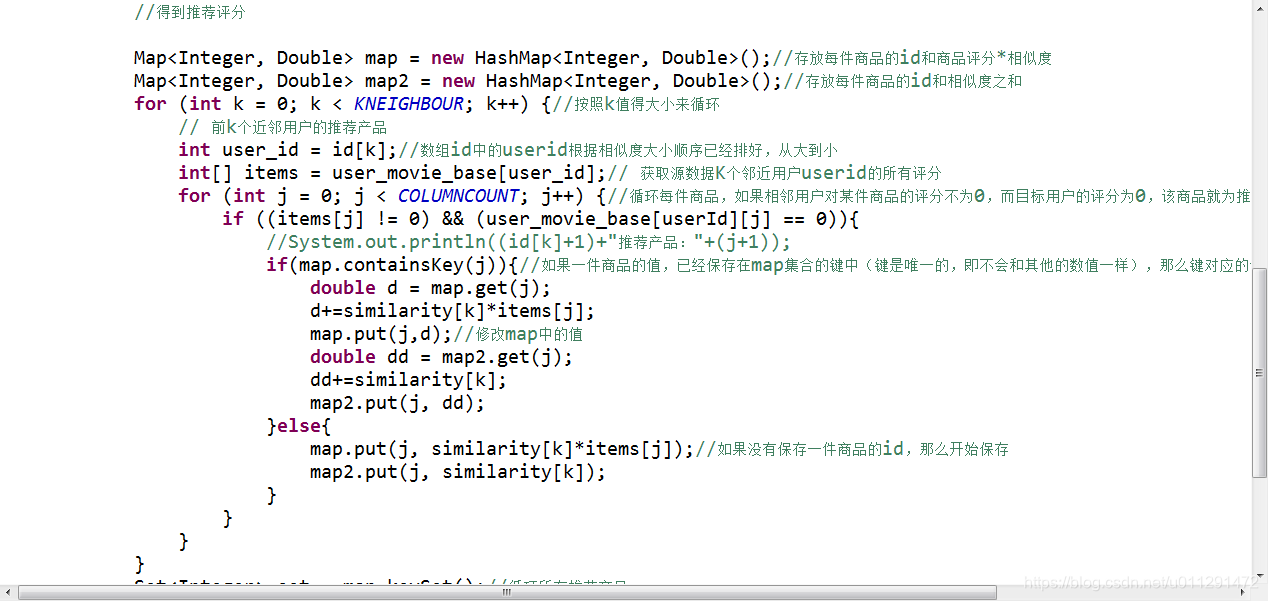
二、基于用户评分的协同过滤推荐算法
实现步骤:
1、构建用户-性别矩阵(movielens数据集),用户属性可以是多个,如下图:
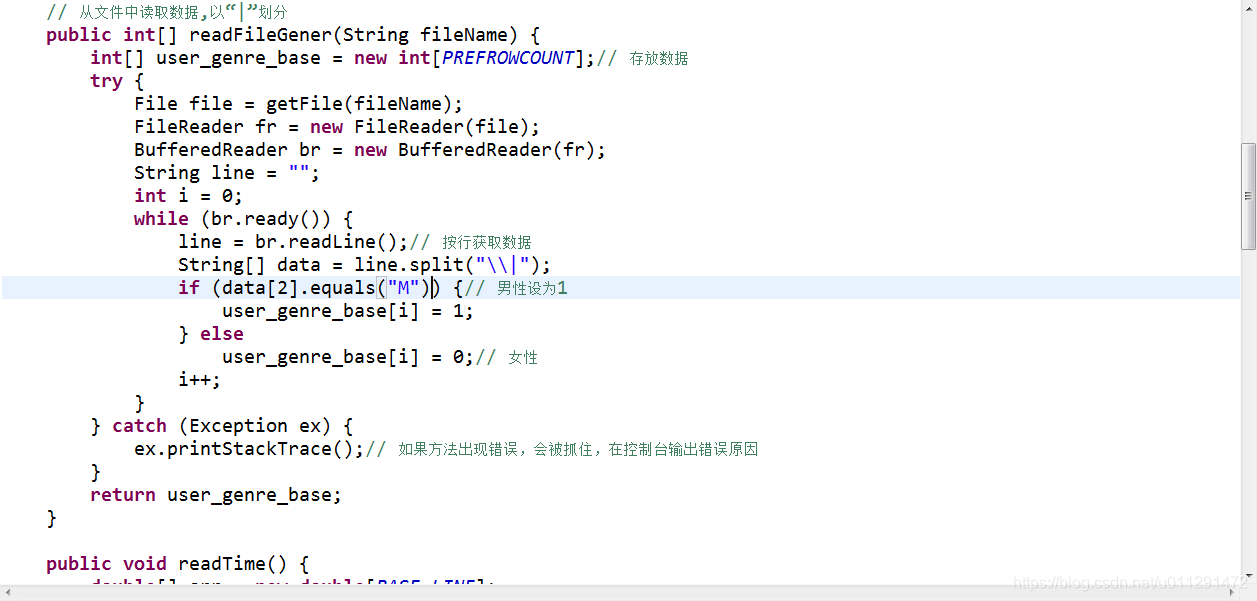
2、计算目标用户与其他用户的相似度,如下图:

3、获取KNN个最近邻,如下图:
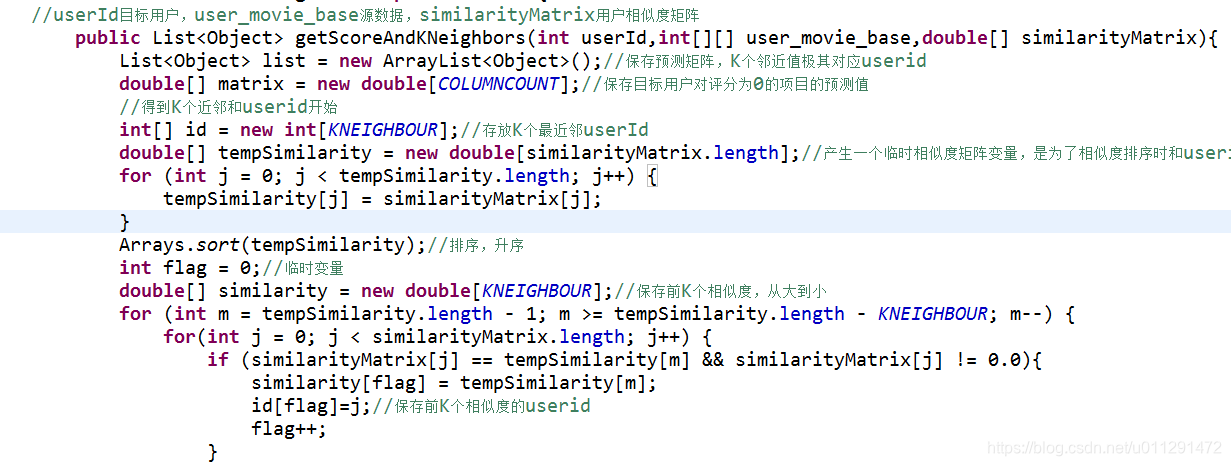
4、获取推荐结果。查询目标用户中没有评分的,同时最近邻中有评分的电影,并付默认值。
三、加权混合推荐
首先将两种算法的预测值*加权并相加,然后将加权后的预测值进行冒泡排序,最后根据预测值大小得到前N个推荐电影。
项目源代码:https://download.csdn.net/download/u011291472/11967745
















 4858
4858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











