







hadoop,spark,kafka交流群:224209501
标签(空格分隔): hadoop
1,根据集群配置合理规划hadoop集群组件
本节主要讲述:如何依据集群机器配置(内存、硬盘、CPU核)合理规划Hadoop服务组件部署的几点(表格规划、形象生动)
主机内存是8G,硬盘720G,cpu4核。为了提高运行效率,会将datanode和nodemanager在同一台机器上。
具体配置如下:
| 配置名 | hadoop.host | hadoop1.host | hadoop2.host |
|---|---|---|---|
| cpu | 1 | 1 | 1 |
| 内存 | 2G | 1.5G | 1.5G |
| 硬盘 | 20G | 20G | 20G |
| hdfs | namenode datanode | datanode | secondarynamenode datanode |
| yarn | nodemanager | nodemanager resourcemanager | nodemanager |
| MR | historyserver |
2,为集群部署搭建集群主机环境
本节主要内容如下:对克隆虚拟机进行修改网卡名称和配置IP地址与主机名,配置集群中三台机器的IP地址和主机名称的映射。
集群部署是需要多台主机,这里选择使用三台虚拟机完成部署任务。克隆晚虚拟机之后,在打开的虚拟机中通过 ifcongig 查看网络设置,发现只有 eth1 的网络设置,没有 eth0 的网络设置,并且
eth1 的网络信息,与/etc/sysconfig/network-script/ifcfg-eth0 中的设置不同。
解决办法是执行命令
sudo vi /etc/udev/rules.d/70-persistent-net.rules然后执行如下操作:
- 注释掉或删除包含 eth0 的行
- 把包含“eth1”行的“eth1”修改成“eth0”,完成后如下图:
- 拷贝这里的原eth1的物理地址。
- 执行命令sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0
将三中复制的物理地址粘贴到如下图处:
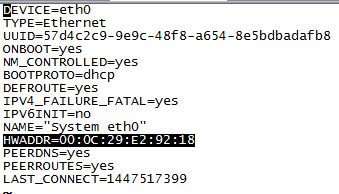
修改主机名及IP地址,并完成映射:
- 执行 sudo vi /etc/sysconfig/network
- 将主机名修改为:hadoop1.host;hadoop2.host
- 将两台克隆机的IP地址分别修改为:192.168.154.129和192.168.154.130
- 执行 ‘sudo vi /etc/hosts’命令完成IP地址映射。
注:这个主机名与IP地址映射要在主机,三台虚拟机中都配置。
3,部署集群
本节主要讲:以【Hadoop 2.x伪分布式部署】为模板,理解各个服务组件部署节点的配置,配置部署安装集群。
- 首先在三台主机上执行
sudo mkdir /opt/app和sudo chmod 777 /opt/app - 然后执行
tar -zxvf /opt/softwares/hadoop-2.5.0.tar.gz /opt/app/ - 然后打开nodepad++,连接上主机hadoop2.host对hadoop的xml文件进行配置。
具体如下:
(1) 首先在hadoop-env.sh,yarn-env
.hs,mapred-env.sh添加java命令的路径:
/opt/modules/jdk1.7.0_67
(2) 修改core-site.xml文件内容如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.host:8020</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>(3) 修改hdfs-site.xml,文件将namenode和secondarynamenode分别部署在hadoop.host和hadoop2.host上,具体内容如下:
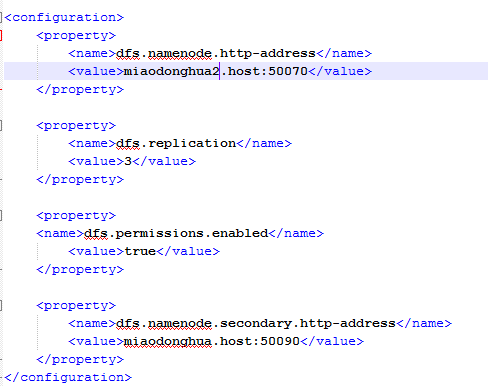
(4) 修改yarn-site.xml文件将resourcemanager部署在hadoop1.host上,具体修改内容如下:
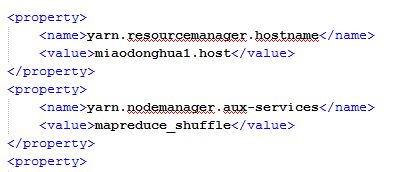
(5) 修改mapred-site.xml文件将jobhistory服务部署在hadoop1.host上,具体内容修改如下:
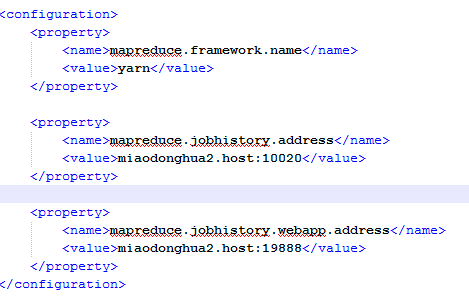
(5) 修改slaves文件,将nodemanager和datanode分别部署在三台主机上,修改内容如下:

(6) 执行命令下面命令将配置好的hadoop文件分别传递到另外两台主机上去:
scp -r hadoop-2.5.0/ hadoop@hadoop1.host:/opt/app/
scp -r hadoop-2.5.0/ hadoop@hadoop2.host:/opt/app/4,测试集群
本节主要讲述:启动HDFS、YARN以后,对集群进行基本测试,如上传文件,运行WordCount程序等。
4.1 启动集群
- 启动HDFS。首先在主机hadoop.host中执行:
sbin/hadoop-daemon.sh start namenode。然后分别在三台虚拟机中执行sbin/hadoop-daemon.sh start datanode。 - 启动YARN。在主机hadoop1.host执行
sbin/yarn-daemon.sh start resourcemanager。分别在三台主机中执行sbin/yarn-daemon.sh start nodemanager。 - 启动historyserver。在主机miaodongua2.host执行:
sbin/mr-jobhistory-daemon.sh start historyserver
上述指令执行完成后分别再三台主机控制台中输入jps命令,查看服务是否启动成功。出现如下内容证明成功。

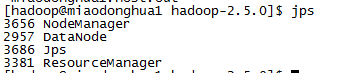
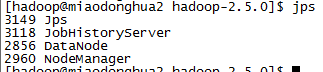
4.2 测试集群
- 创建目录。
bin/hdfs dfs -mkdir -p mapreduce/wordcount/input- 上传/opt/datas目录下的文件wc.input和wc1.input。
bin/hdfs dfs -put /opt/datas/wc.input mapreduce/wordcount/input
bin/hdfs dfs -put /opt/datas/wc1.input mapreduce/wordcount/input以上两个步骤操作成功后,会在生成目录mapreduce/wordcount/input,而且目录下回多出两文件:
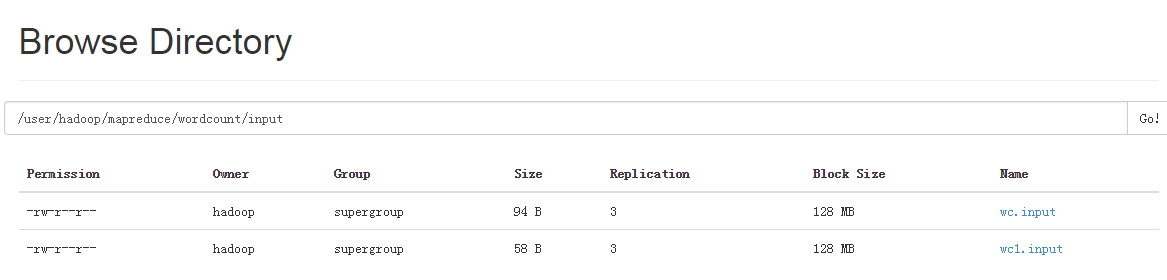
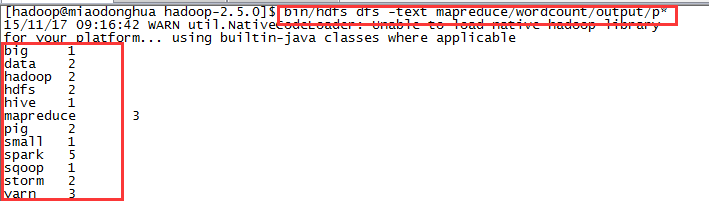
运行wordcount程序。
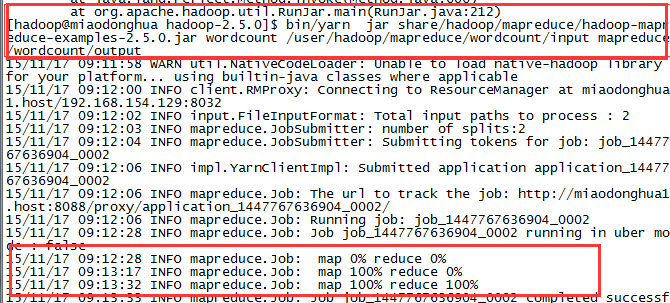
查看生成结果。














 4266
4266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









