







本周学习的内容便是大名鼎鼎的SVM。虽然视频不多,但是涉及到的知识点却是比以前多了不少。之前通过其他视频或者资料已经学过了,但是一直还是有一种雾里看花的感觉。这次通过这个视频,给了我另外一个看SVM的方向,让我对SVM的理解又加深了一层吧。这篇博文呢通过这两个方向同时分析,这样子感觉更能够get到SVM的精髓。话不多说切入正题。
SVM的基本思想,是得到一个large margin classifier,即得到一个分界面,使得训练集中的任意一个样本能够在尽可能地正确分类的情况下,距离这个分界能够尽可能的大,换言之,即是令最小的几何间隔(geometric margin)
r=min(|θTx+b|||w||)
能够尽可能地大,其中
θ
是函数的参数,
x
是样本的特征向量,
s.t.
∑mi=1αiyi=0
αi≥0;i=1,2,3,...m
其中
αi
是拉格朗日乘子,若第i个样本为支持向量的话,那
αi≠0
。那么最后得到的平面为
f(x)=wTx+b=∑mi=1αiyixTix+b
而求解
α
的方法,比较常见的是SMO算法,这里也不展开讲了。
以上为常见的对SVM的推导方法,而coursera上的分析思路与这种方法不太相同。
在之前的课程中,我们知道了logistics regression的代价函数为
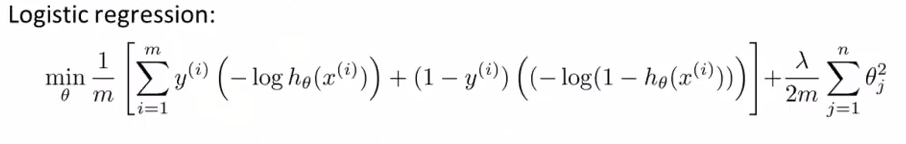
可以知道,其中的
−log(hθ(x(i)))
为当label为1时的损失函数,与之相对
−log(1−hθ(x(i)))
为当label为0时的损失函数。我们考虑将其替换为SVM特有的损失函数:

那这个cost函数是什么意思呢?其中斜率并不是重点,只需要关注当y=1,时,若
θTx+b≥1
则没有惩罚,换句话说,即是我们希望所有正样本到直线的函数间隔(function margin)大于等于1。y=0时同理。
去掉一些不重要的常数后,得到如下图所示的惩罚函数
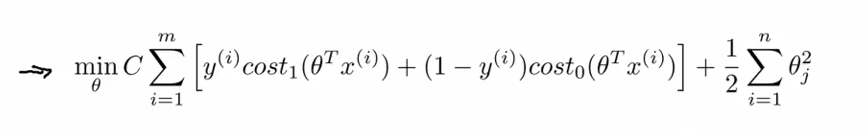
其中C代表我们对样本分类正确与否的重视程度,与logistics regression的
λ
是一个道理,若我们将C的值取为一个较大的数值,那么会使得模型更加趋近于去迎合模型,那么有一个错误的分类点对其影响就会很大(类似于overfitting)。
而现在重要的是,需要知道的是为什么在这个损失函数下,可以得到使得margin取最大的分类器。
对于运算
θTx
来说,这个运算其实是等价于
p(i)||θ||
,其中这里
p(i)
是
x(i)
在特征向量
θ
上的投影长度(因为向量^T*向量的本质就是内积)。
在假设样本可以被完全正确分类的情况下,那么损失函数就只剩下了
∑mi=1θi2
(因为cost function的前半段为
C∗0=0
),并且若本完全正确分类,则需满足如下条件
(θTx+b)y(i)≥1;i=1,2,3,...m
⇒
p(i)||θ||≥1;i=1,2,3,...m
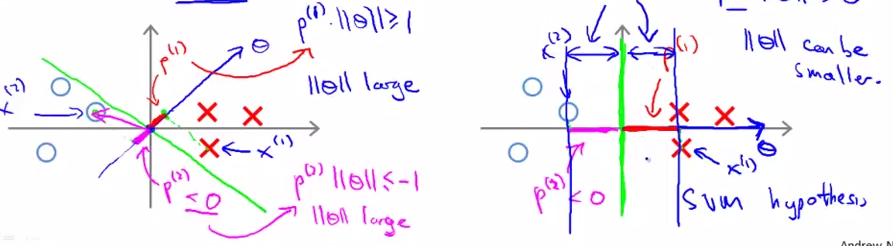
那么可以得到,若我们要最小化
∑mi=1θi2
,那么该模型必然要向
p(i)
取得较大值的方向进行优化,因此就会得到margin较大的模型,达到了取到large margin classifier的目的。
关于SVM的基本推导大概就是这样,至于关于kernel的东西下次再补充好了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









