







线程优先级
我们知道Windows最强大的地方在于它让我们在使用操作系统时变得更加简单,因为它有一个个的窗口,并且窗口与窗口之间能够交互(每个窗口的资源都是分配到各自对应的线程里面),正是由于多线程的存在,才支持了Windows的多界面功能,才让Windows变得强大。
我们之前在说旋转锁的时候就提到过线程的优先级,并且还说过旋转锁会导致饥饿线程的出现,但是这个饥饿线程只会出现在单核CPU的进程中。因为当一个单核CPU下运行的进程,这个进程又有两个优先级较高的线程形成了旋转锁,此时优先级较低的线程将永远也不会得到执行,就出现了我们所说的饥饿线程,需要注意的是我们的这些假设都是建立在单核CPU的基础上的,当多核CPU出现的时候,这些情况就会变得截然不同了。
Windows优先级的概念
Windows的每一个可调度的线程分配了一个优先级(0~31),当系统准备去执行一个线程时,会首先看优先级为31的线程,并且以循环的方式进行调度。只要有优先级为31的线程,操作系统将永远不会调用30以下的线程,这样看起来好像优先级较低的线程永远得不到被执行的机会,其实系统中大部分的线程都是处于不可调度状态的。比如,当调用了GetMessage函数后,就会导致线程休眠,从而变成不可调度状态。
需要注意的是:
优先级较高的线程总是会去抢占抢占优先级较低线程的时间片,无论优先级较低的线程是否在执行属于自己的时间片,当较高优先级的线程已经准备好可以运行的时候,它会直接打断优先级较低的线程的执行顺序,并将CPU时间片分配给优先级较高的线程。
优先级为0的线程
操作系统中有一个优先级为0的线程,为页面清零线程(Zero Page Thread),它负责在系统空闲时清理所有闲置的内存,将所有的闲置内存进行清零操作。这个线程在操作系统里面有且只有一个(我们自己的线程不可能设置到0优先级),并且它是随着操作系统的启动而启动。这样优先级的线程会给我们在进行程序设计时的一个启发,那就是在进程空闲时做一些清理工作,比如文件读写等!
进程优先级
因为系统设计的需要,Windows需要不停地切换进程,或者选择某一进程进行运行,所以Windows也对进程进行了优先级的设置。它有如下几个级别:
1. real-time实时;
2. high立即;
3. above normal较高;
4. normal高;
5. below normal较低;
6. idle低。
(其实进程的优先级是非常的不好理解,因为进程是不存在的,进程中有线程的存在才是进程!)
需要注意的是,我们永远不要将我们自己的进程优先级设置为实时优先级,因为进程被设置为实时优先级的时候,这个进程已经拥有了最高的打断权限,你的进程有可能会打断操作系统的某些任务,当打断这些任务的时候,Windows所架构的这些不可调度的状况就会被我们的进程打乱,此时的操作系统就会变得非常的卡顿,所有的资源都被我们的进程所占用,我们进程中但凡有一点写的不好,就能导致整个Windows操作系统变得特别慢。所以我们一定不能给我们的进程设计为实时优先级。但是high优先级也不能设置,我们自己的进程优先级最多设置为above normal的优先级即可!!!资源管理器默认打开的进程是normal优先级,还有当设置进程的优先级为实时优先级的时候需要管理员的权限。
不应该有任何的进程运行在实时优先级上,因为实时优先级可能会影响到操作系统的任务,可能会导致磁盘、键盘、网络通信等的使用。
进程的优先级,也会影响进程中的线程优先级的使用。
| 线程优先级 | real-time | high | above normal | normal | below normal | idle |
|---|---|---|---|---|---|---|
| time-critical | 31 | 15 | 15 | 15 | 15 | 15 |
| highest | 26 | 15 | 12 | 10 | 8 | 6 |
| above normal | 25 | 14 | 11 | 9 | 7 | 5 |
| normal | 24 | 13 | 10 | 8 | 6 | 4 |
| below normal | 23 | 12 | 9 | 7 | 5 | 3 |
| lowest | 22 | 11 | 8 | 6 | 4 | 2 |
| idle | 16 | 1 | 1 | 1 | 1 | 1 |
表中显示的数值都是我们能够对我们自己的进程进行设置的优先级,而其它的0、17、18、19、20、21、27、28、29、30共10个优先级是我们不能够设置的,它们是留给操作系统来使用的。
0优先级为系统保留页面清零线程,而其它优先级留给内核;
默认启动的进程为normal优先级;
Windows资源管理器的进程优先级为high,是为了实时关闭进程;
CreateProcess函数可以设置进程的优先级,其实它是通过:
SetPriorityClass来改变自己的优先级、
GetPriorityClass来获取当前进程的优先级,
SetThreadPriority可以改变线程优先级、
GetThreadPriority可以获取当前线程优先级;
特别值得注意的是,CreateThread无法设置线程优先级,线程默认是以normal优先级运行的,操作系统会根据系统需要动态的提升一些线程的优先级,默认每次会给优先级提升两级,在操作完一个时间片后递减1,直至恢复原来的优先级!!!
- IO操作时
- 饥饿线程
动态调整的线程要求优先级在1-15的范围内,并且每次调整的最大值不会超过15
通过SetProcessPriorityBoost和SetThreadPriorityBoost函数可以设置是否允许系统对进程和线程提升优先级。
我们来看一个优先级的例子:
#include <tchar.h>
#include <process.h>
#include <cstdio>
const int THREADCOUNT = 3;
int g_iNo1 = 0, g_iNo2 = 0, g_iNo3 = 0;
unsigned int __stdcall ThreadFunc1(void *lParam)
{
while (true)
{
++g_iNo1;
}
return 0;
}
unsigned int __stdcall ThreadFunc2(void *lParam)
{
while (true)
{
++g_iNo2;
}
return 0;
}
unsigned int __stdcall ThreadFunc3(void *lParam)
{
while (true)
{
++g_iNo3;
}
return 0;
}
int main()
{
HANDLE hThreads[THREADCOUNT] = { INVALID_HANDLE_VALUE };
hThreads[0] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc1, (void *)1, CREATE_SUSPENDED, nullptr);
SetThreadPriority(hThreads[0], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[0]);
hThreads[1] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc2, (void *)2, CREATE_SUSPENDED, nullptr);
SetThreadPriority(hThreads[1], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[1]);
hThreads[2] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc3, (void *)3, CREATE_SUSPENDED, nullptr);
SetThreadPriority(hThreads[2], THREAD_PRIORITY_IDLE);
ResumeThread(hThreads[2]);
while (true)
{
Sleep(1000);
printf("g_iNo1:%d\r\ng_iNo2:%d\r\ng_iNo3:%d\r\n", g_iNo1, g_iNo2, g_iNo3);
}
WaitForMultipleObjects(THREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < THREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
return 0;
}我们创建了三个线程,其中前两个线程的优先级最高,后一个线程的优先级最低,我们让这三个线程都运行1000毫秒,然后看这三个全局变量输出的值是多少,假如我们考虑饥饿线程的话,那么第三个线程是永远也得不到运行的,但是结果会让我们大吃一惊。
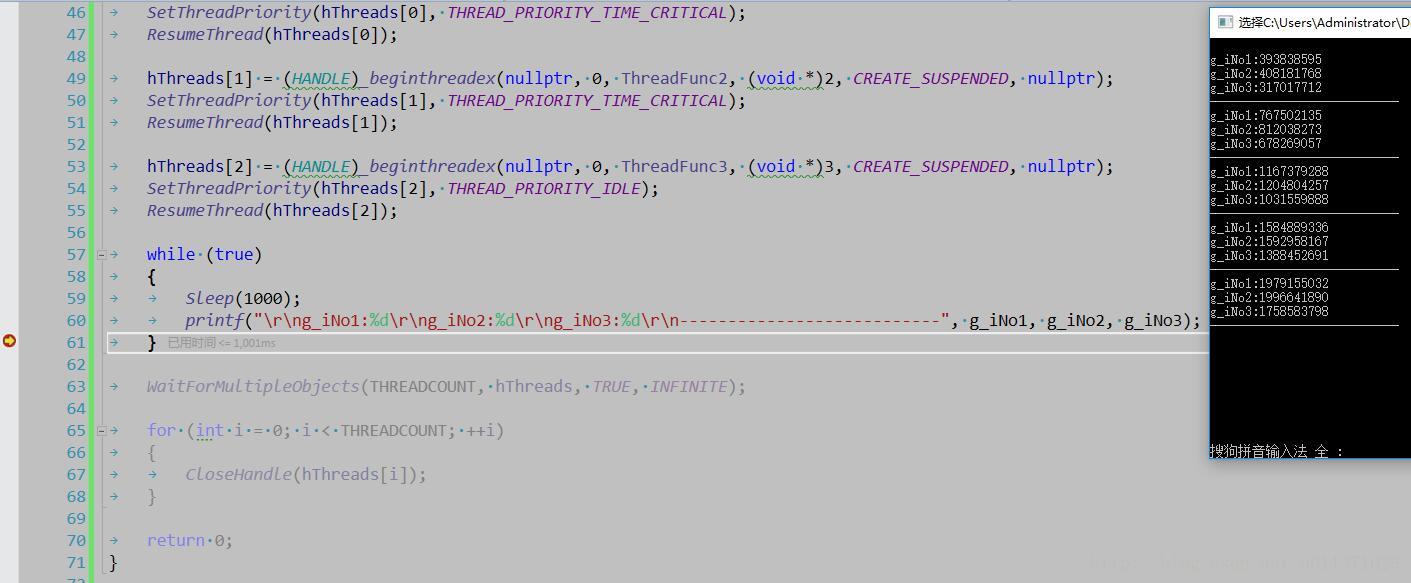
从结果上来看,这三个线程都能够得到执行,并且执行的时间片基本上也相同,这个结果好像不是我们想象中的啊!!!这是为什么呢?这是因为CPU在进行调度的时候,特别是在多核系统下面,我们进程中的优先级比较低的线程,会被调度给其它CPU来执行。
当系统自作聪明的给我们提升线程的优先级的时候,它就会我们自己的调度,我们可以通过SetProcessPriorityBoost和SetThreadPriorityBoost函数来设置是否允许系统对进程和线程提升优先级。
下面的例子是SetThreadPriorityBoost函数通过把CPU自动提升线程优先级给关了,看看结果如何。
#include <tchar.h>
#include <process.h>
#include <cstdio>
const int THREADCOUNT = 3;
int g_iNo1 = 0, g_iNo2 = 0, g_iNo3 = 0;
unsigned int __stdcall ThreadFunc1(void *lParam)
{
while (true)
{
++g_iNo1;
}
return 0;
}
unsigned int __stdcall ThreadFunc2(void *lParam)
{
while (true)
{
++g_iNo2;
}
return 0;
}
unsigned int __stdcall ThreadFunc3(void *lParam)
{
while (true)
{
++g_iNo3;
}
return 0;
}
int main()
{
HANDLE hThreads[THREADCOUNT] = { INVALID_HANDLE_VALUE };
hThreads[0] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc1, (void *)1, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[0], TRUE);
SetThreadPriority(hThreads[0], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[0]);
hThreads[1] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc2, (void *)2, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[1], TRUE);
SetThreadPriority(hThreads[1], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[1]);
hThreads[2] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc3, (void *)3, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[2], TRUE);
SetThreadPriority(hThreads[2], THREAD_PRIORITY_IDLE);
ResumeThread(hThreads[2]);
while (true)
{
Sleep(100);
printf("\r\ng_iNo1:%d\r\ng_iNo2:%d\r\ng_iNo3:%d\r\n---------------------------", g_iNo1, g_iNo2, g_iNo3);
}
WaitForMultipleObjects(THREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < THREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
return 0;
}结果如下:
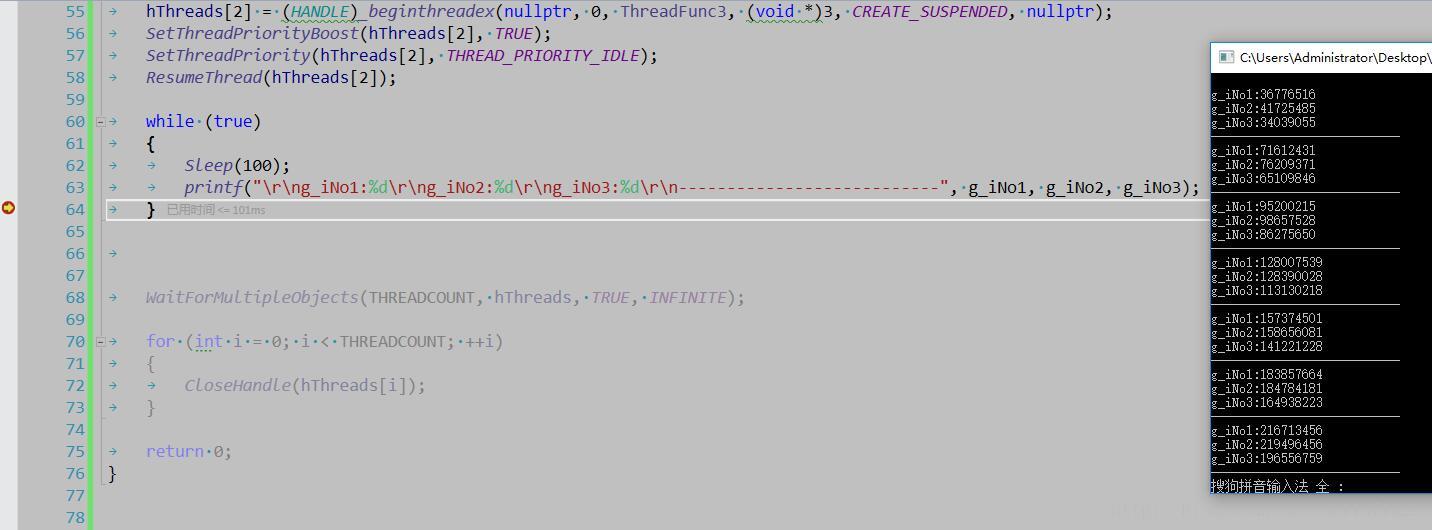
这个结果看上去跟我们没有关闭线程优先级自动提升的时候差不多,几乎没什么影响,这是为什么呢?很简单,这是因为我们运行在多核CPU操作系统上的。
我们大家是不是都觉得多核CPU会对我们的多线程应用程序有很大的好处,我一开始也是这么以为的,但是事实上并不是这样,确切的说,应该不是对于所有的多线程应用程序的运行效率有所提高,对于某些多线程应用程序反而可能会导致执行效率还会下降!!!这是为什么呢?举个稍微简单点儿的例子,就像我们使用多线程一样,如果我们的线程使用了太多的同步,那么执行效率还不如单线程的高,那么对于CPU也是一样的!!!我们都知道,CPU会去我们的内存中去读取数据,CPU为了提高运行效率,专门增加了一个高速缓存区(维基百科),当CPU读取内存中的某一块数据的时候,它会将与这一块数据相关联的其它数据放在高速缓存区里面,这样CPU去高速缓存区里面读数据和去寄存器里面读数据的速度是一样的(因为去内存中读取的速度相对于去寄存器中读取数据的速度还是比较慢的),但是这块宝贵的高速缓存区在多核CPU中不是由某个核心独占的,而是由多个核心共同使用的,如果我们这几个核心读取的数据不在CPU的高速缓存区里面,那么这样的读取速度就会变得很慢,从而也 影响了CPU的执行效率。所以Windows为我们提供了一系列函数来让我们设置我们的进程在,某一个CPU上运行、线程在某一个CPU上运行,甚至还可以设置在某一组CPU上面运行。请看下面的例子:
#include <Windows.h>
#include <tchar.h>
#include <process.h>
#include <cstdio>
const int THREADCOUNT = 3;
int g_iNo1 = 0, g_iNo2 = 0, g_iNo3 = 0;
unsigned int __stdcall ThreadFunc1(void *lParam)
{
while (true)
{
++g_iNo1;
}
return 0;
}
unsigned int __stdcall ThreadFunc2(void *lParam)
{
while (true)
{
++g_iNo2;
}
return 0;
}
unsigned int __stdcall ThreadFunc3(void *lParam)
{
while (true)
{
++g_iNo3;
}
return 0;
}
int main()
{
// 00000001 1号CPU
// 00000010 2号CPU
// 00000100 3号CPU
// 00000011 1号和2号CPU
SYSTEM_INFO system_info = { 0 };
GetSystemInfo(&system_info);
system_info.dwActiveProcessorMask; // 假如有8个CPU,那么这个值就是0xFF
system_info.dwNumberOfProcessors; // 假如有8个CPU,那么这个值就是8
SetProcessAffinityMask(GetCurrentProcess(), 0x1); // 设置我们的程序在一个CPU上面运行
HANDLE hThreads[THREADCOUNT] = { INVALID_HANDLE_VALUE };
hThreads[0] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc1, (void *)1, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[0], TRUE);
SetThreadPriority(hThreads[0], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[0]);
hThreads[1] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc2, (void *)2, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[1], TRUE);
SetThreadPriority(hThreads[1], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[1]);
hThreads[2] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc3, (void *)3, CREATE_SUSPENDED, nullptr);
SetThreadPriorityBoost(hThreads[2], TRUE);
SetThreadPriority(hThreads[2], THREAD_PRIORITY_IDLE);
ResumeThread(hThreads[2]);
while (true)
{
Sleep(100);
printf("\r\ng_iNo1:%d\r\ng_iNo2:%d\r\ng_iNo3:%d\r\n---------------------------", g_iNo1, g_iNo2, g_iNo3);
}
WaitForMultipleObjects(THREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < THREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
return 0;
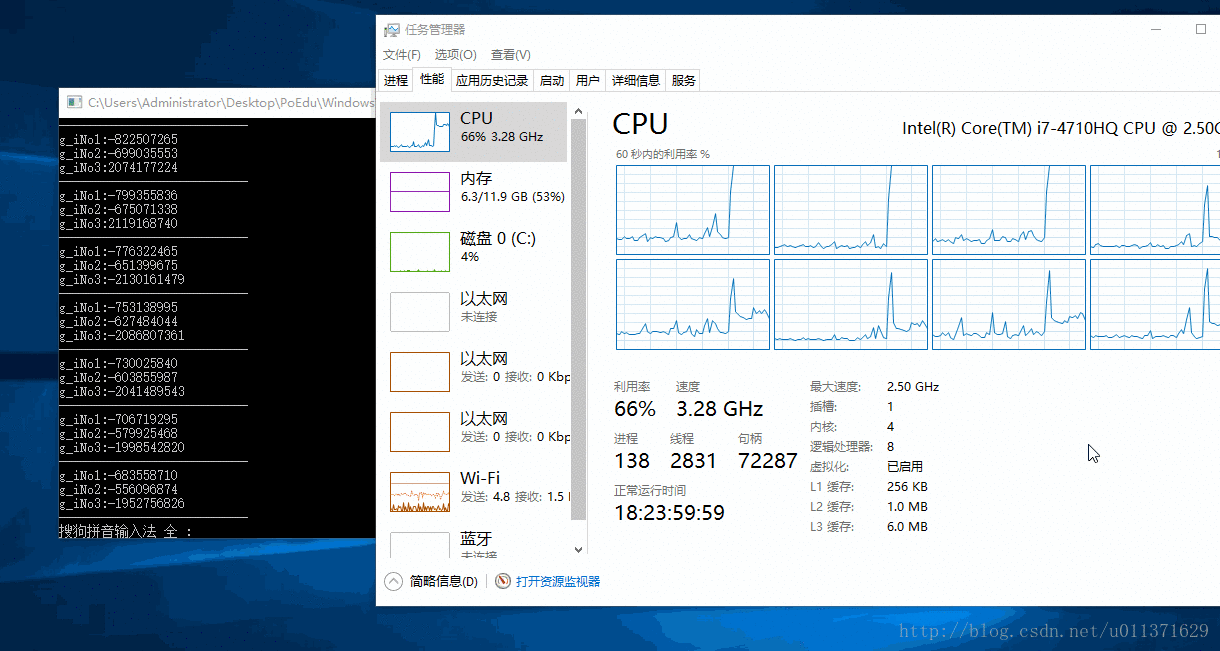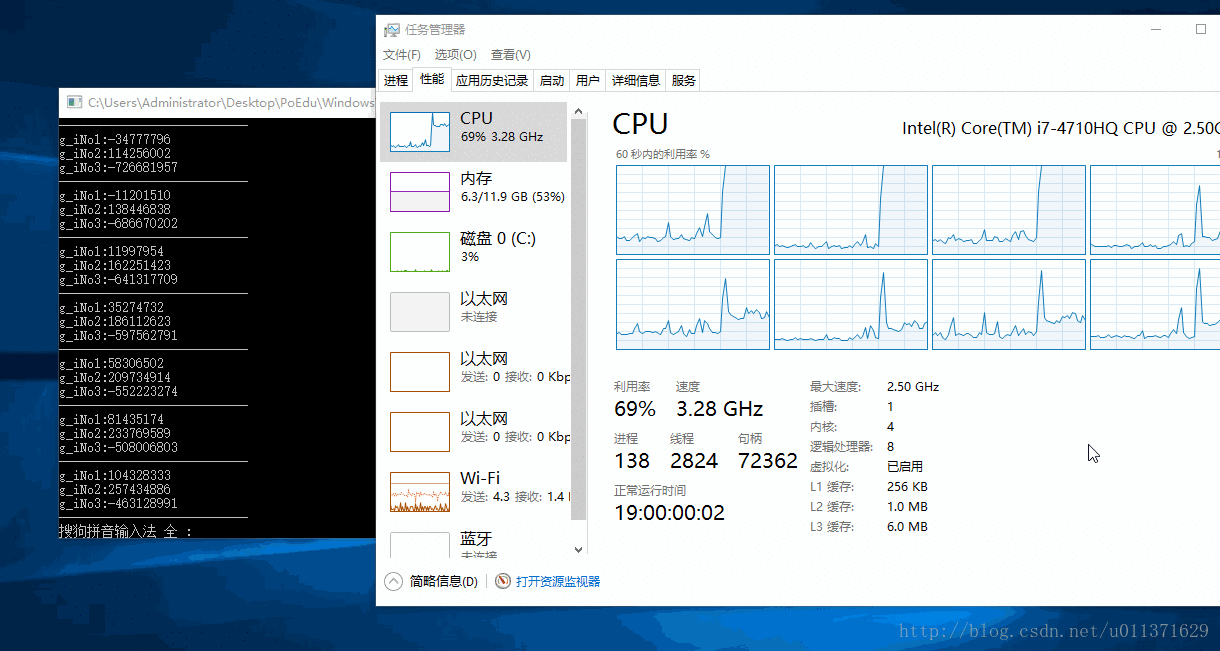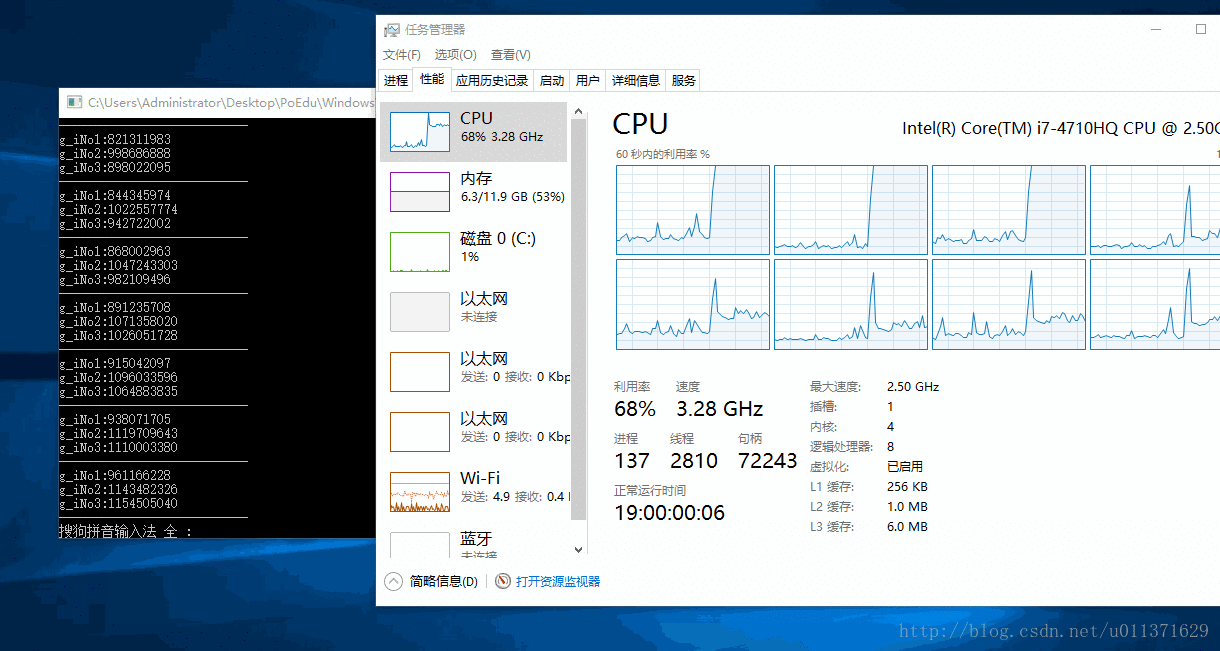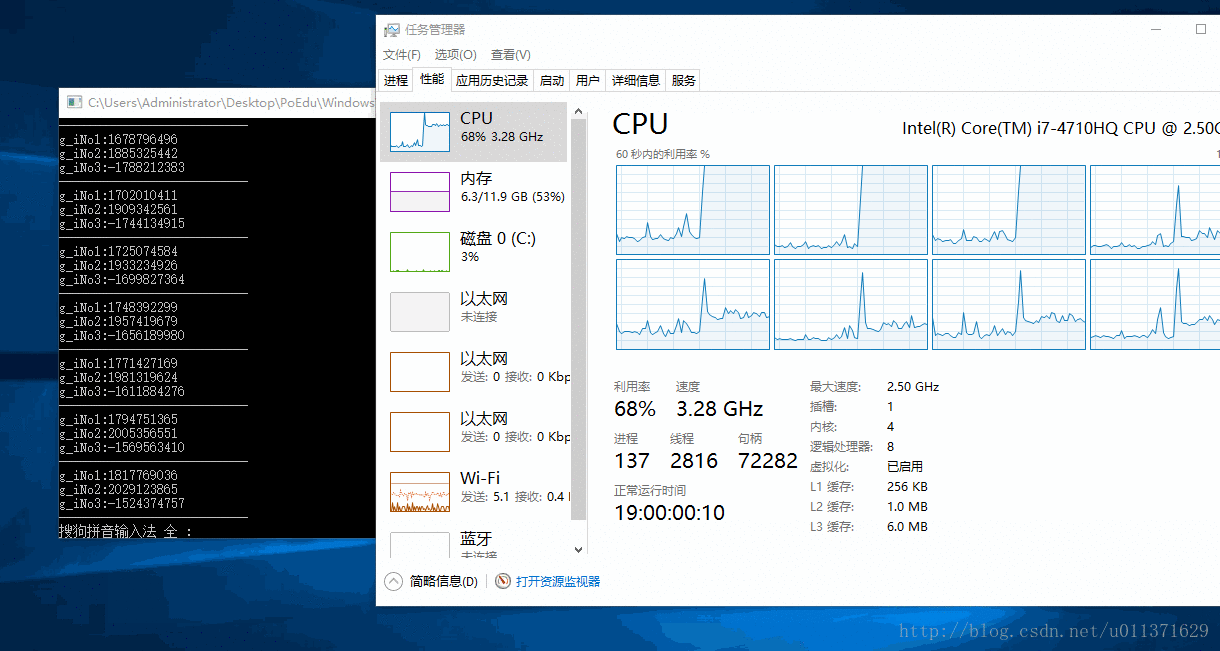
}上面的代码是让我们的程序只在第一个CPU上面运行,我们为了更好的观察运行效果,我们借助于Windows自带的任务管理器。结果请看下面的动态图
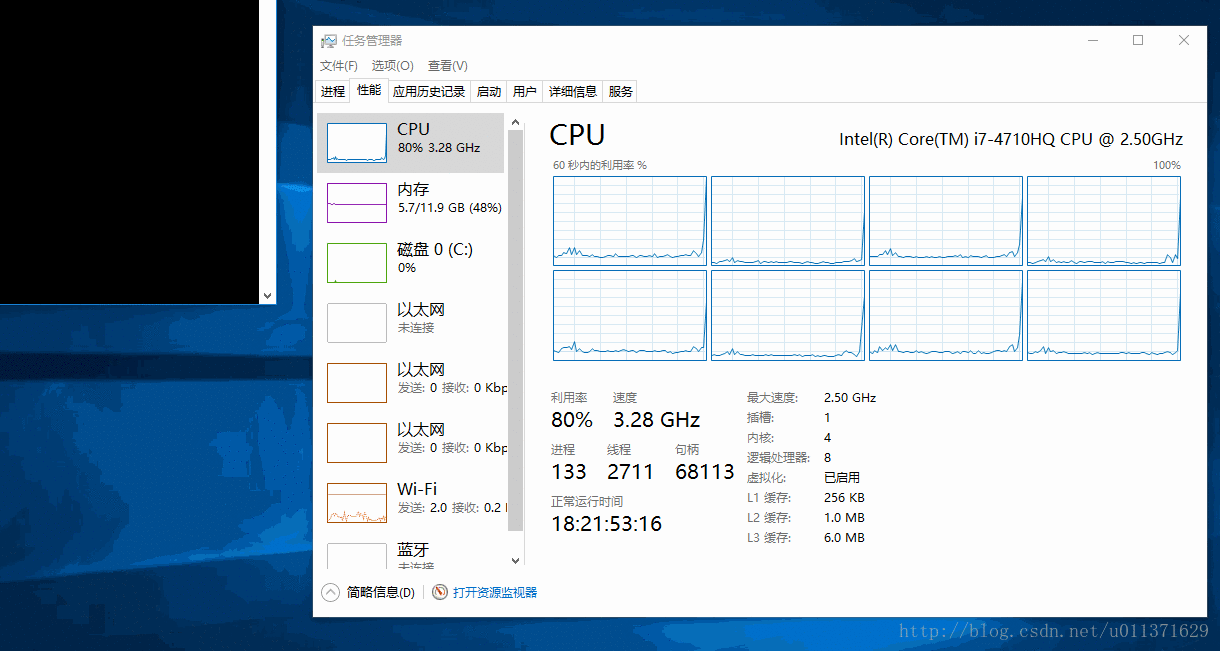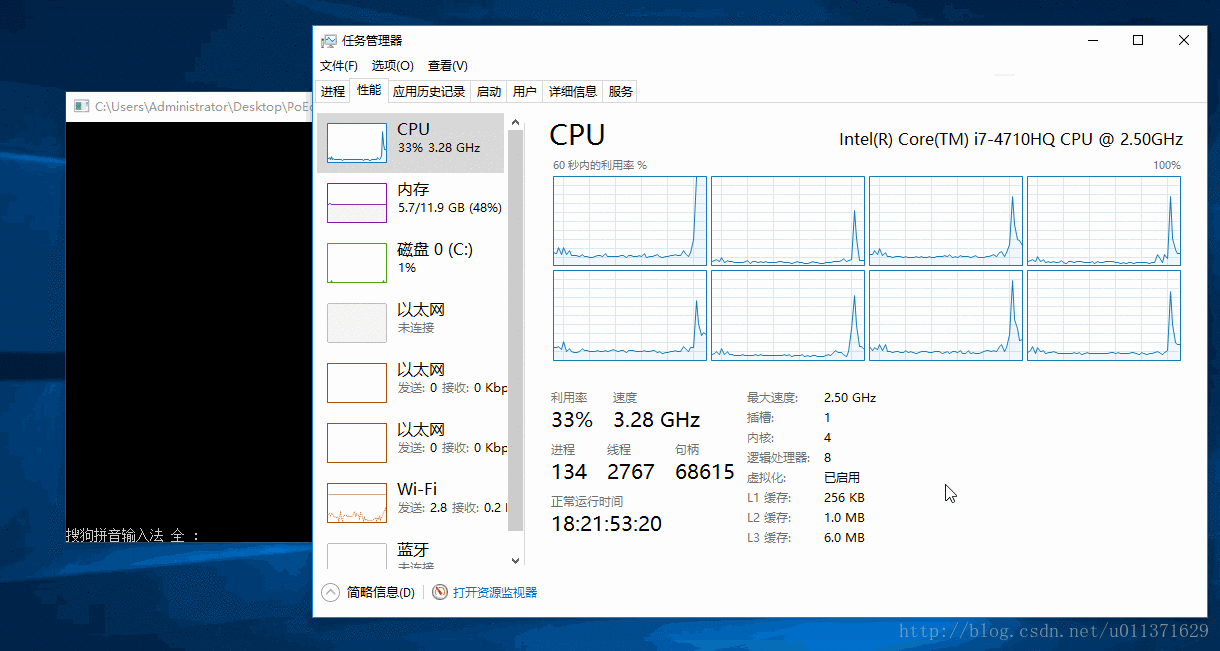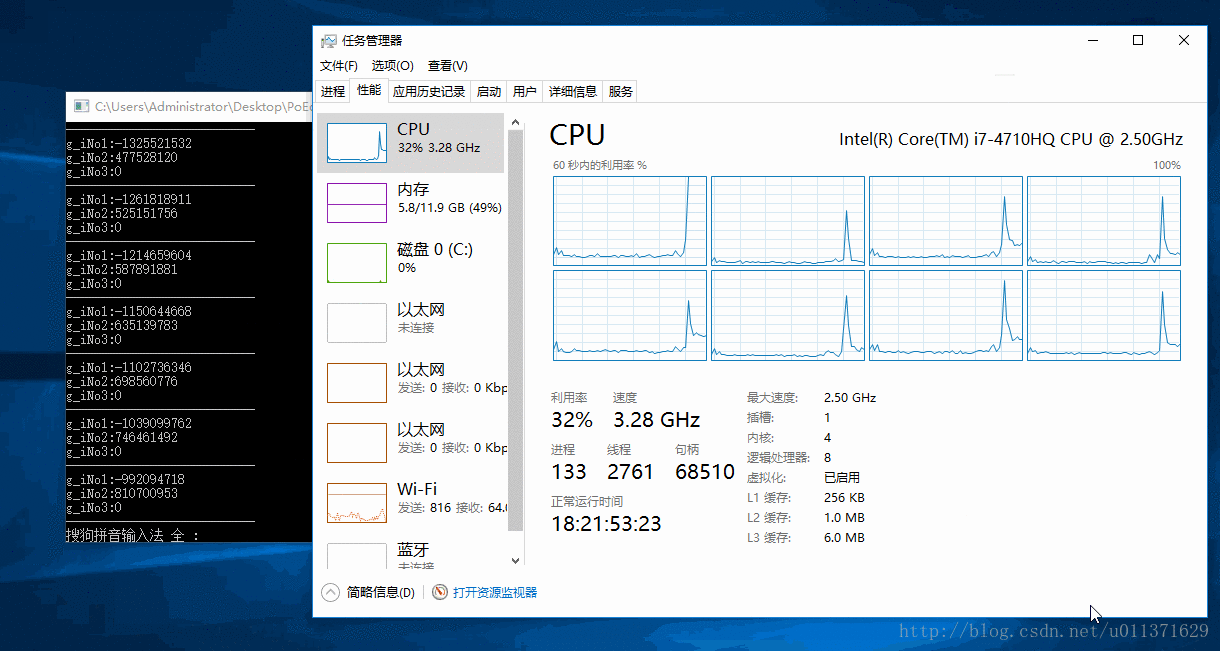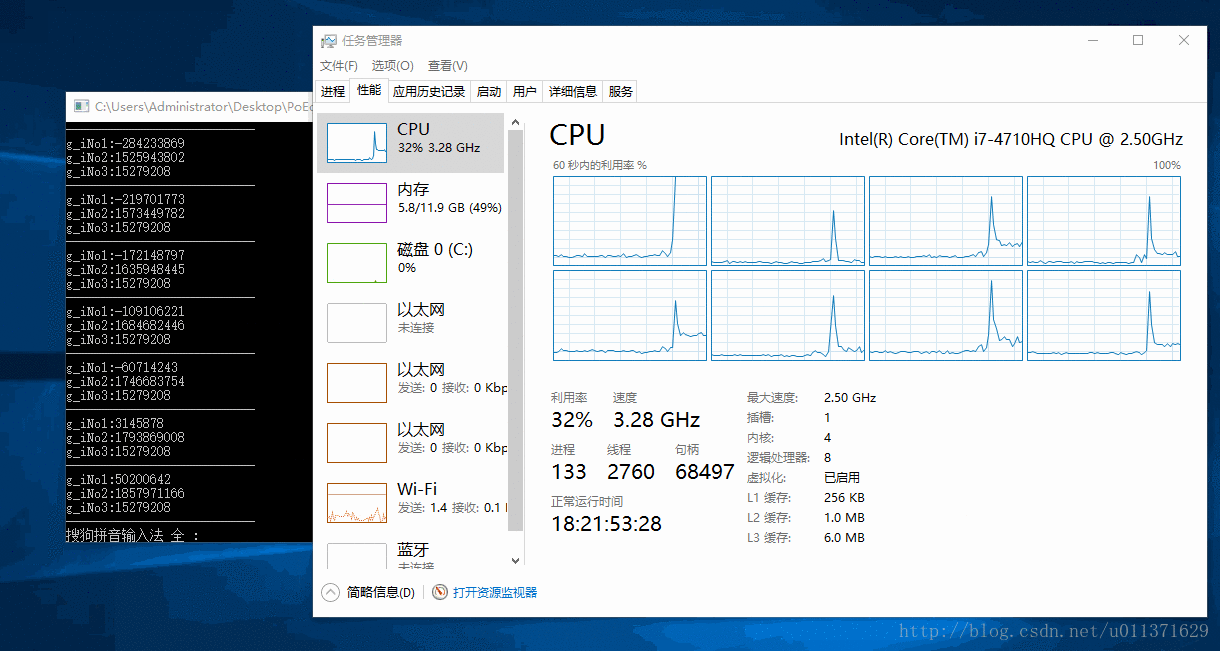
从上面的结果可以直接的看出,0号CPU的使用率突然变成了100%,这是因为我们设置的就是第一个CPU来执行我们的程序。我们还可以看出,程序已经运行了好几秒钟,才看到有数字输出,这是因为我们的主线程main函数也被饥饿了好几秒钟,才得到CPU的调度,而我们设置的优先级最低的三号线程被饥饿的时间更长,因为连续打印出了好多个0,说明没有被执行。我们看到的一号线程的数是负数,这并不是错误数值,而是已经溢出了。
下面我们再设置两个CPU来运行我们的程序,看情况会有什么变化!!!
代码就不用上了吧?就改变一个数值即可,如下所示:
SetProcessAffinityMask(GetCurrentProcess(), 0x3); // 设置我们的程序在第一和第二个CPU上面运行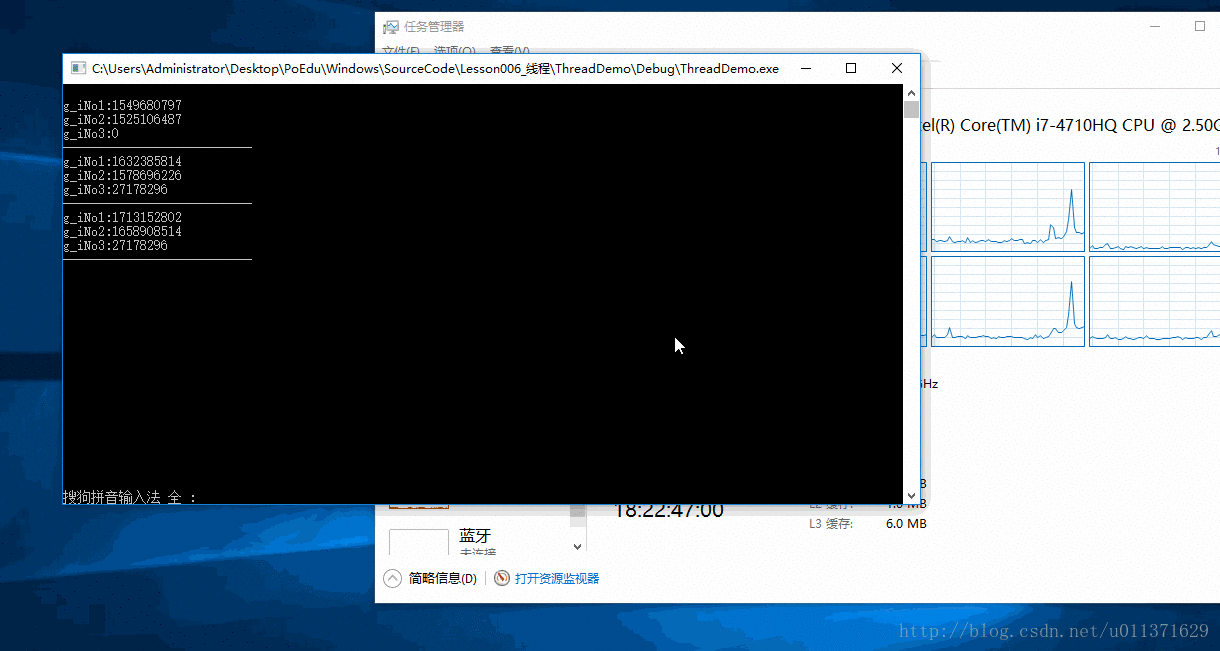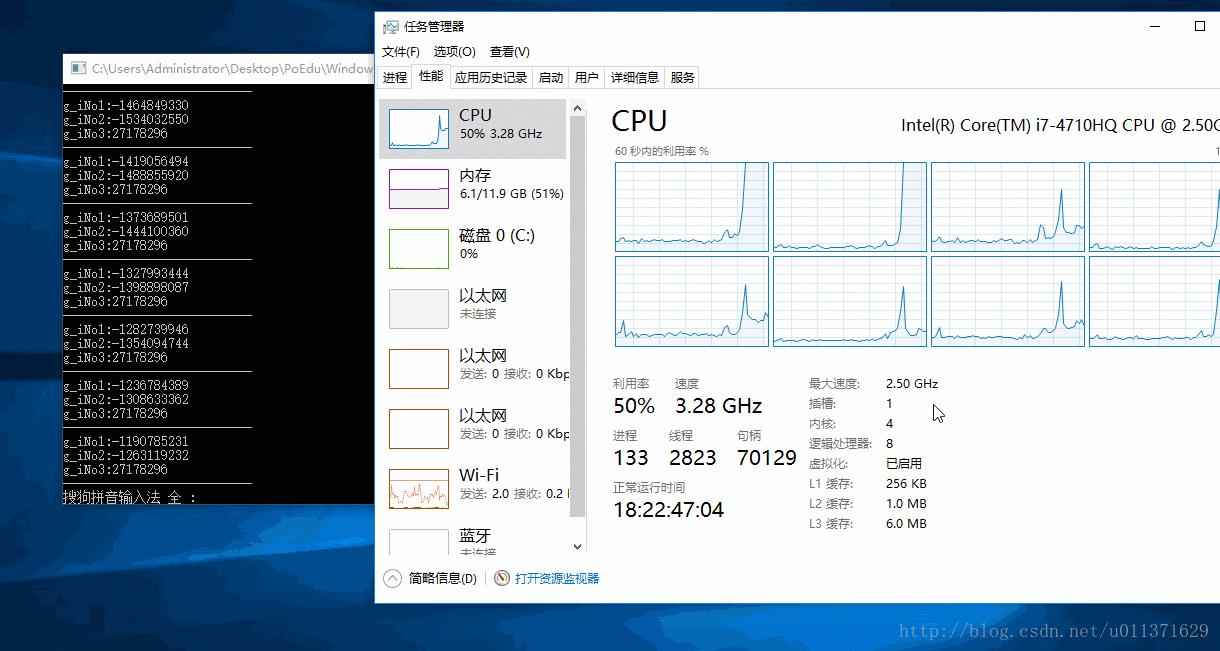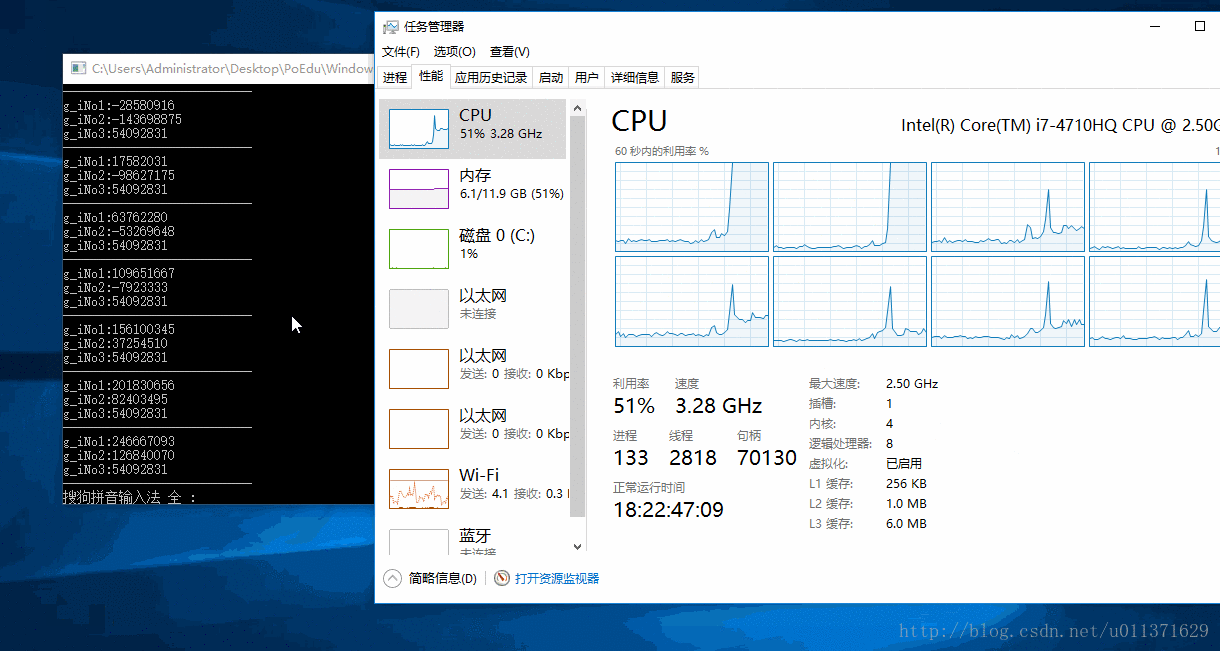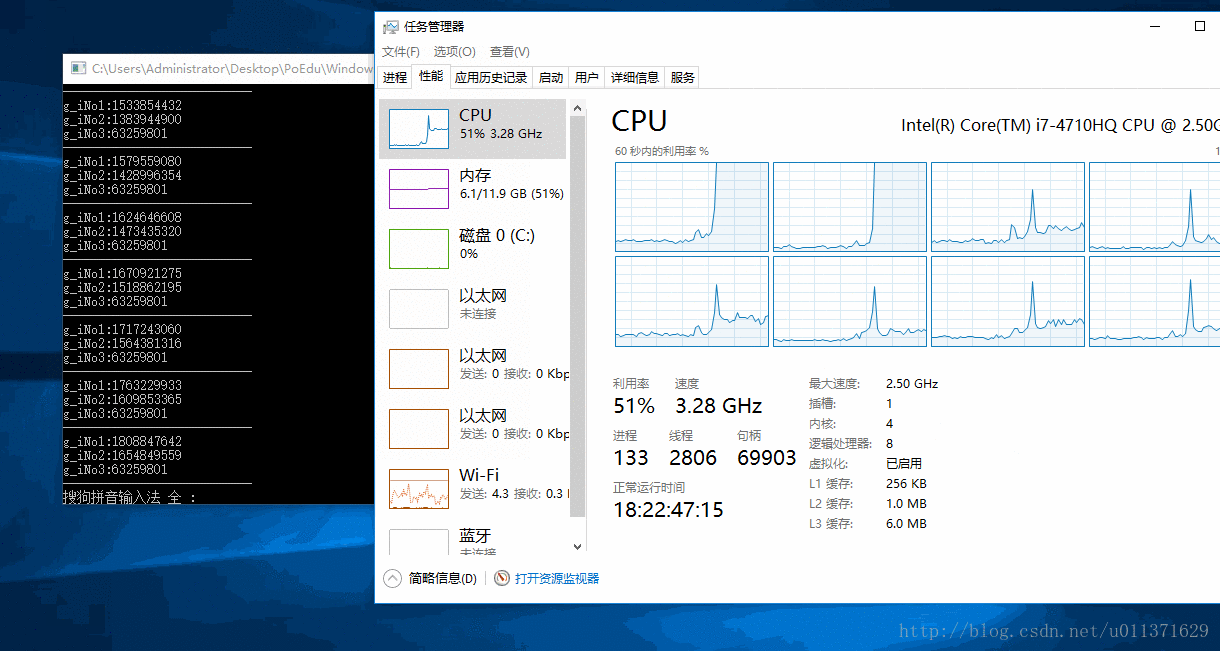
从结果上可以看出,第一个和第二个CPU的使用率达到了100%,我们还可以看到,三号线程对应的数字有连续好几次没有改变,这也说明第三个线程还是会被饥饿的。
我们再来看使用三个CPU的时候会出现什么情况:
SetProcessAffinityMask(GetCurrentProcess(), 0x7); // 设置我们的程序在第一、第二和第三个CPU上面运行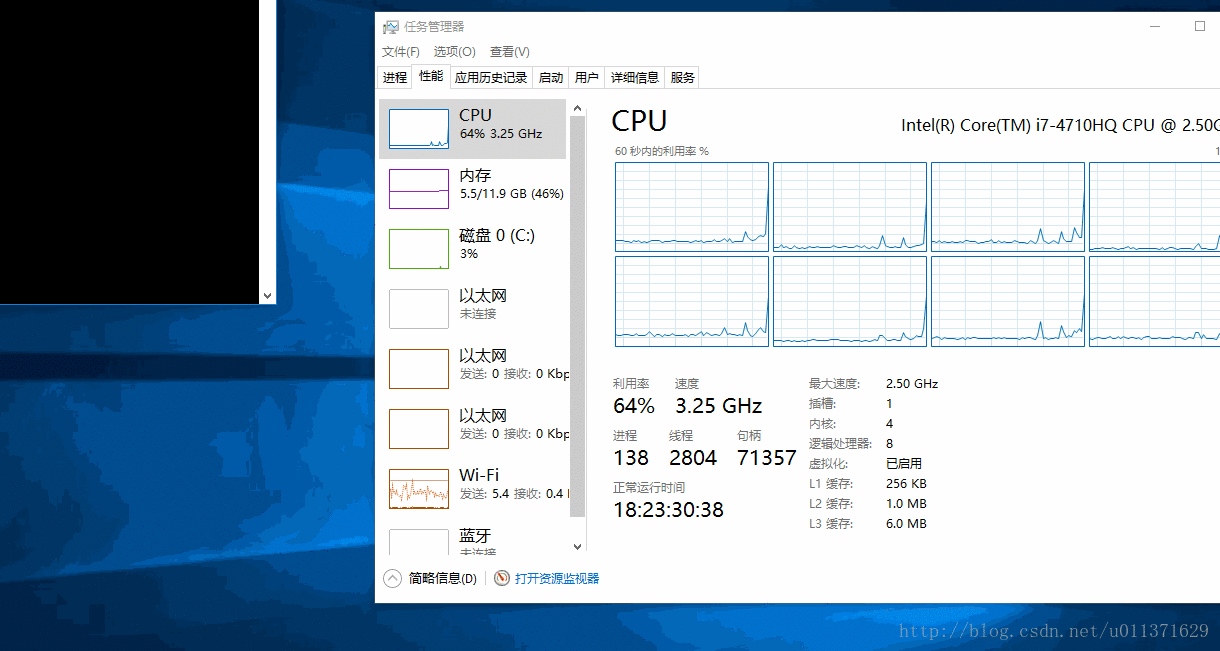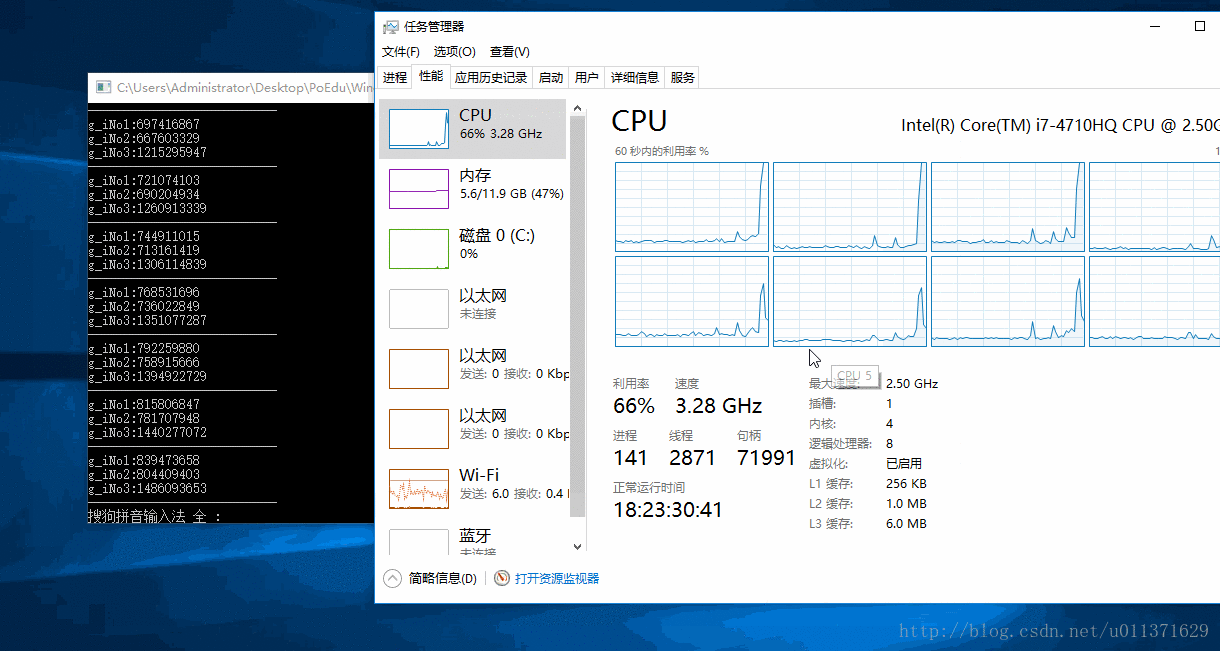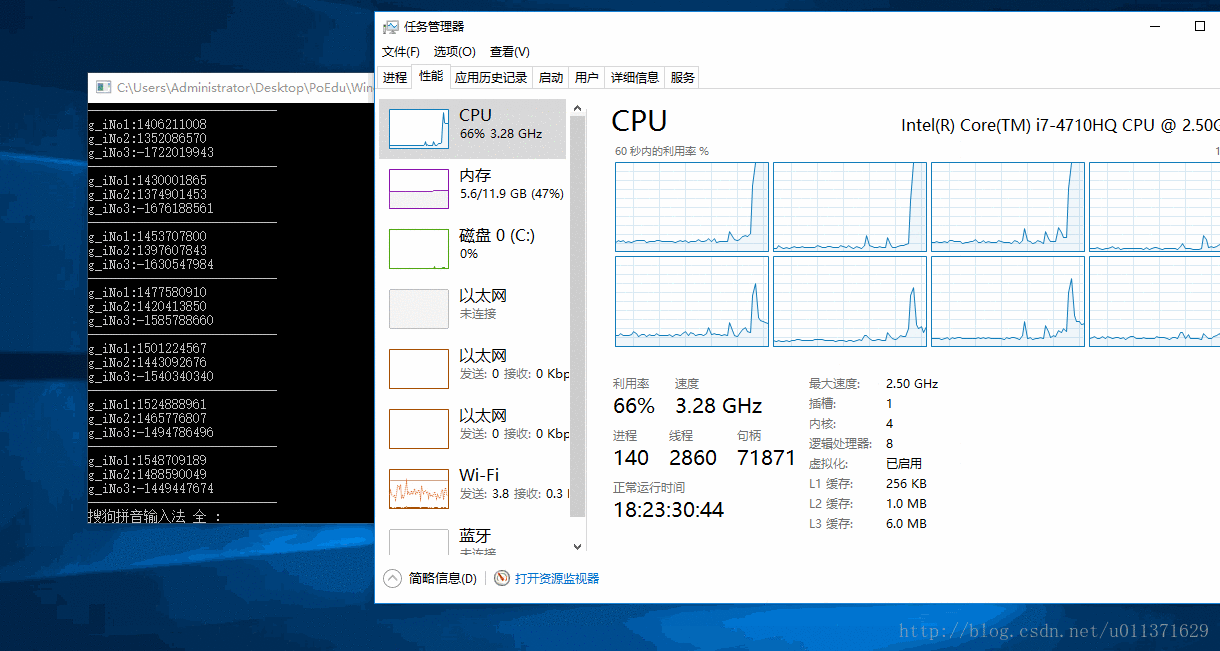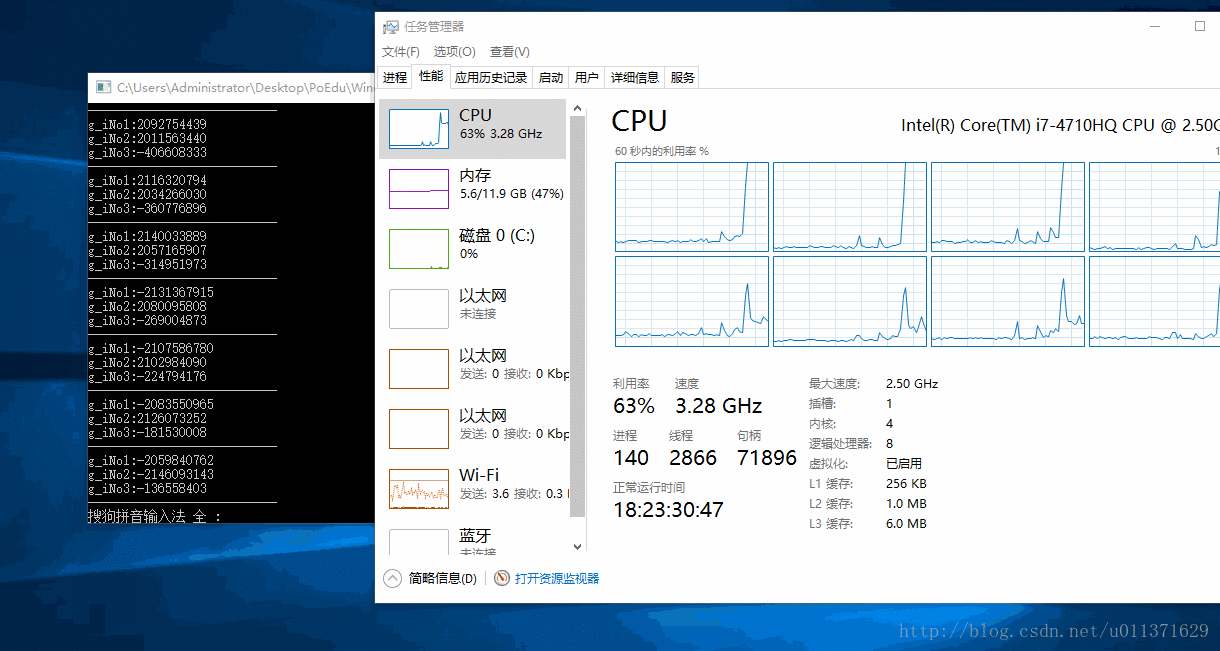
从结果上可以看出,这三个线程执行的速度基本上是一样的。因为这三个线程基本上各自独占一个CPU来运行。
其实以上设置进程在哪个CPU上面运行色情况很少,我们一般是设置哪些线程在哪个CPU上面运行。特别是当我们有一些共享内存的时候,更需要将这些线程设置到同一个CPU组里面执行。
下面我们设置三个线程分别在第一、第二和第三个CPU上面运行,主线程在其他的CPU上面运行,我们来看一下结果。
#include <Windows.h>
#include <tchar.h>
#include <process.h>
#include <cstdio>
const int THREADCOUNT = 3;
int g_iNo1 = 0, g_iNo2 = 0, g_iNo3 = 0;
unsigned int __stdcall ThreadFunc1(void *lParam)
{
while (true)
{
++g_iNo1;
}
return 0;
}
unsigned int __stdcall ThreadFunc2(void *lParam)
{
while (true)
{
++g_iNo2;
}
return 0;
}
unsigned int __stdcall ThreadFunc3(void *lParam)
{
while (true)
{
++g_iNo3;
}
return 0;
}
int main()
{
// 00000001 1号CPU
// 00000010 2号CPU
// 00000100 3号CPU
// 00000011 1号和2号CPU
SYSTEM_INFO system_info = { 0 };
GetSystemInfo(&system_info);
system_info.dwActiveProcessorMask; // 假如有8个CPU,那么这个值就是0xFF
system_info.dwNumberOfProcessors; // 假如有8个CPU,那么这个值就是8
SetProcessAffinityMask(GetCurrentProcess(), 0xFF); // 设置我们的程序8个CPU上面运行
HANDLE hThreads[THREADCOUNT] = { INVALID_HANDLE_VALUE };
hThreads[0] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc1, (void *)1, CREATE_SUSPENDED, nullptr);
SetThreadAffinityMask(hThreads[0], 0x1);
SetThreadPriorityBoost(hThreads[0], TRUE);
SetThreadPriority(hThreads[0], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[0]);
hThreads[1] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc2, (void *)2, CREATE_SUSPENDED, nullptr);
SetThreadAffinityMask(hThreads[1], 0x2);
SetThreadPriorityBoost(hThreads[1], TRUE);
SetThreadPriority(hThreads[1], THREAD_PRIORITY_TIME_CRITICAL);
ResumeThread(hThreads[1]);
hThreads[2] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc3, (void *)3, CREATE_SUSPENDED, nullptr);
SetThreadAffinityMask(hThreads[2], 0x4);
SetThreadPriorityBoost(hThreads[2], TRUE);
SetThreadPriority(hThreads[2], THREAD_PRIORITY_IDLE);
ResumeThread(hThreads[2]);
while (true)
{
Sleep(100);
printf("\r\ng_iNo1:%d\r\ng_iNo2:%d\r\ng_iNo3:%d\r\n---------------------------", g_iNo1, g_iNo2, g_iNo3);
}
WaitForMultipleObjects(THREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < THREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
return 0;
}
上面的几个例子说明了线程的优先级以及CPU亲和度的一些设置方法,这些方法对于我们以后的特殊编程有一定的作用,但是在真正写程序的时候,只需要了解一下有这些方法就可以了。我们应该经常去使用_beginthreadex函数。
临界区及线程函数中使用静态变量
临界区对象结构体
typedef struct _RTL_CRITICAL_SECTION {
PRTL_CRITICAL_SECTION_DEBUG DebugInfo;
//
// The following three fields control entering and exiting the critical
// section for the resource
//
LONG LockCount;
LONG RecursionCount;
HANDLE OwningThread; // from the thread's ClientId->UniqueThread
HANDLE LockSemaphore;
ULONG_PTR SpinCount; // force size on 64-bit systems when packed
} RTL_CRITICAL_SECTION, *PRTL_CRITICAL_SECTION;其中,LockCount是被锁定的次数。
InitializeCriticalSection函数来初始化临界区,这个函数不仅仅是初始化 g_cs 这个结构体,它还分配了一些内存,这些内存并不是临界区的内存,确切的说,应该是和临界区内存信息相关的内存,分配完这块内存之后,在和临界区的内存进行绑定但是 InitializeCriticalSection 函数的返回值为void,当这个函数出现错误是,我们是无法知道它的返回值的,也就是不知道错在哪儿啦!并且这个函数已经被其它很多地方使用,所以微软也没有其它的办法来对这个函数进行调整,所以微软在server 2003和Windows XP中,InitializeCriticalSection函数在发生错误的时候会抛出一个异常。这样貌似解决了一些问题,但是没有从根本上解决,它只能在c++中使用,在c语言中就无法使用了。
此时微软又出来了另一个函数,InitializeCriticalSectionAndSpinCount,它会返回一个BOOL值,来告诉我们函数调用是否成功。它是以旋转锁的方式使用临界区,它其实是为了解决EnterCriticalSection进入临界区函数的问题,这个函数和死循环有些类似,它最主要的目的是挡住其它线程,不让其它线程进入正在使用的区域,来保证当前的代码在运行的时候只有一个线程来返回。这个函数被调用的时候,会产生两种效果:一种效果是被获准访问(就是没有其它线程在访问的时候,通过临界区结构体对象来得到获准,并更新临界区结构体对象的值),另一种效果是使得无法访问这一段代码空间的线程进入等待的状态(从调度池进入到不可调度状态),而且等待状态是有周期的,假如有多个线程来访问该临界区的代码,在多核CPU下,很有可能导致某些线程会一直处于等待状态。所以为了解决这样的事情,才设计了InitializeCriticalSectionAndSpinCount函数,这个函数的第二个参数是一个尝试进入临界区的次数,当发现临界区被占用时,它不会马上进入临界区,而是尝试进入临界区指定次数后才真正进入临界区进行等待,这样在一定程度上解决了线程一直等待临界区的资源。
TryEnterCriticalSection函数会返回一个值,告诉我们是否可以进入临界区,这样就可以根据返回值做一些逻辑处理。
下面是一个关于临界区访问的最简单的例子
#include <Windows.h>
#include <tchar.h>
#include <process.h>
#include <cstdio>
volatile int g_iNum = 0;
volatile int g_iLoopCount = 100;
CRITICAL_SECTION g_cs; // 临界区 或者 关键段
unsigned int __stdcall ThreadFunc(void *lParam)
{
static int iThreadIndex = 0;
EnterCriticalSection(&g_cs);
iThreadIndex++;
g_iNum = 0;
for (int i = 0; i < g_iLoopCount; ++i)
{
g_iNum += i;
}
_tprintf(TEXT("Thread %d:%d\r\n"), iThreadIndex, g_iNum);
LeaveCriticalSection(&g_cs);
return 0;
}
int main()
{
const int MAXTHREADCOUNT = 10;
HANDLE hThreads[MAXTHREADCOUNT] = { INVALID_HANDLE_VALUE };
InitializeCriticalSection(&g_cs);
for (int i = 0; i < MAXTHREADCOUNT; ++i)
{
hThreads[i] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc, nullptr, 0, nullptr);
}
WaitForMultipleObjects(MAXTHREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < MAXTHREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
DeleteCriticalSection(&g_cs); // 在删除临界区的时候,不仅仅将 g_cs 这个结构体的
// 数据进行清理,而且还会将它所分配的内存进行清理
system("pause");
return 0;
}结果如下所示:

结果和我们预期的完全一致,如果我们稍作一些修改,那么结果,又会怎样呢?将线程函数中的代码修改如下:
unsigned int __stdcall ThreadFunc(void *lParam)
{
static int iThreadIndex = 0;
iThreadIndex++;
EnterCriticalSection(&g_cs);
g_iNum = 0;
for (int i = 0; i < g_iLoopCount; ++i)
{
g_iNum += i;
}
_tprintf(TEXT("Thread %d:%d\r\n"), iThreadIndex, g_iNum);
LeaveCriticalSection(&g_cs);
return 0;
}结果如下所示:
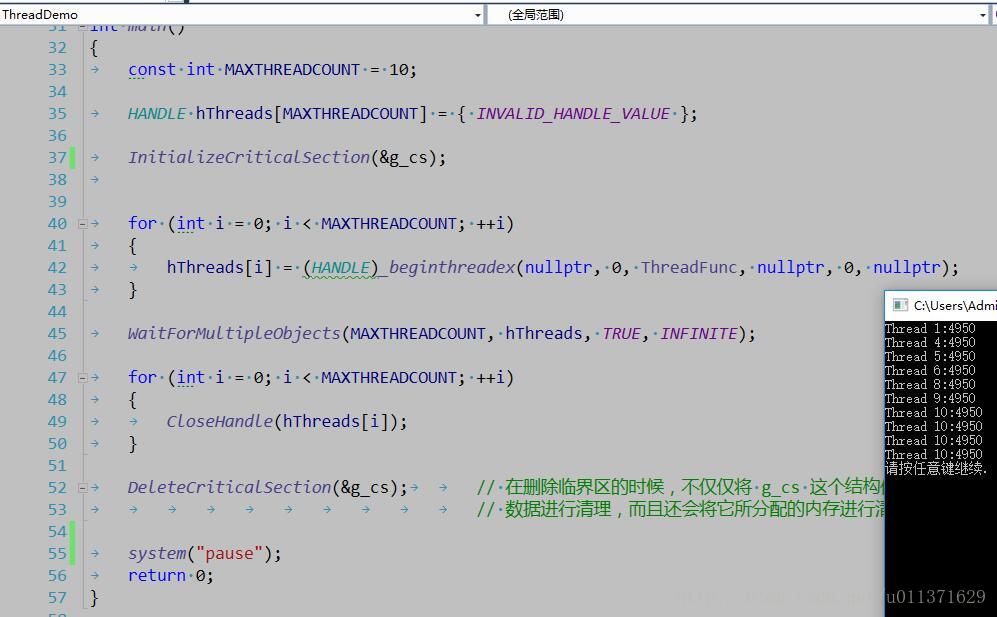
毫无疑问,这个结果不是我们想要的,这是怎么回事呢?因为静态变量iThreadIndex只会被初始化一次,而多个线程在进入线程函数后,都会马上去执行iThreadIndex++的操作,这样就会导致,不管这个线程函数执行了临界区的代码段没有,它都会毫不犹豫的先将iThreadIndex增加1,所以就会出现上面的错误结果。
在函数中使用静态变量,有的时候会更好,因为它的作用域只是属于这个函数的。
Slim锁及线程休眠及等待及挂起及阻塞
我们对数据之间的同步有了一定的了解,事实上,数据同步就是为了避免在访问同一资源的时候,获取到的值是错误的,但是在什么情况下才会发生错误呢?我们来简单的总结一下:
我们对数据的操作一般也只有读和写两种情况,这两种操作再加上多线程,就会得到很多种组合。
1. 多个线程只去读同一块数据,毫无疑问,这样是不会出现线程安全问题的;
2. 多个线程读,一个线程在写,此时就会出现线程安全问题;
3. 多个线程写,毫无疑问,肯定也会出现线程安全问题的。
所以,只要是涉及到多线程写操作,那么就会出现线程安全年问题。
有的时候,我们会有这样一种逻辑,那就是一个线程在写,多个线程在读,考虑到线程安全的问题,我们也需要使用数据同步,如果使用我们前面所了解的比如旋转锁、临界区等数据同步方法,那么就会导致我们程序的执行效率变得非常非常的低。其实导致线程不安全的只有写操作,而写操作只有一个线程,读操作有多个线程,如果所有的线程都加上数据同步,毫无疑问,这样的程序执行效率还没有一个线程的执行效率高。那么有没有一种机制能够保证我们在写的时候是线程安全的,这样的程序执行效率会很大程度的提高。
// 需要注意的是:
1.无论是独占的方式还是共享的方打开的线程,会使得线程阻塞(变得不可调度),这是这个函数的劣势;
2.使用AcquireSRWLockExclusive或者AcquireSRWLockShared是不能递归的调用,这是这个函数的应用场景。
我们经常会接触到这些名词,分别是:休眠、挂起、阻塞、等待,其实这些名词导致的结果是让线程变得不可调度(释放CPU),当阻塞、挂起、休眠、等待等完成时,线程就变得又可以调度了。
对于挂起,是一个人为的操作,而休眠、阻塞、等待是操作系统的一个行为。
#include <Windows.h>
#include <tchar.h>
#include <process.h>
#include <cstdio>
volatile int g_iNum = 0;
volatile int g_iLoopCount = 100;
SRWLOCK g_srwlock; // 小锁,在使用的时候,和临界区差不多,但是也有一些区别,在于只需要初始化,而不需要delete
unsigned int __stdcall ThreadFunc(void *lParam)
{
static int iThreadIndex = 0;
AcquireSRWLockExclusive(&g_srwlock); // 独占方式进入某一个锁,它和临界区加的锁是一模一样的,它可以保证操作的原子性,
// 但是需要ReleaseSRWLockExclusive(&g_srwlock);来释放资源
iThreadIndex++;
g_iNum = 0;
for (int i = 0; i < g_iLoopCount; ++i)
{
g_iNum += i;
}
_tprintf(TEXT("Thread %d:%d\r\n"), iThreadIndex, g_iNum);
ReleaseSRWLockExclusive(&g_srwlock);
//AcquireSRWLockShared(&g_srwlock); // 共享方式进入某一个锁
//iThreadIndex++;
//g_iNum = 0;
//for (int i = 0; i < g_iLoopCount; ++i)
//{
// g_iNum += i;
//}
//_tprintf(TEXT("Thread %d:%d\r\n"), iThreadIndex, g_iNum);
//ReleaseSRWLockShared(&g_srwlock);
return 0;
}
int main()
{
const int MAXTHREADCOUNT = 10;
HANDLE hThreads[MAXTHREADCOUNT] = { INVALID_HANDLE_VALUE };
InitializeSRWLock(&g_srwlock);
for (int i = 0; i < MAXTHREADCOUNT; ++i)
{
hThreads[i] = (HANDLE)_beginthreadex(nullptr, 0, ThreadFunc, nullptr, 0, nullptr);
}
WaitForMultipleObjects(MAXTHREADCOUNT, hThreads, TRUE, INFINITE);
for (int i = 0; i < MAXTHREADCOUNT; ++i)
{
CloseHandle(hThreads[i]);
}
system("pause");
return 0;
}用户态同步方式总结
用户态下的同步方式,它是Windows给我们提供的一些API,也就是我们可以在R3层直接调用的函数。当然了。既然有用户态的同步方式,那么就也有内核态下的同步方式,也就是使用内核对象进行同步。但是使用内核对象,它的作用不只是在同步上面,内核对象是可以跨进程存在的,有的时候,我们会利用内核对象进行两个进程之间的同步。如如果我们在同一个进程下的同步,最好还是使用用户态下的同步方式,因为效率的问题!!!下面是用户态下的同步方式的效率比较,相信大家看了这个结果之后,会对大家合理选择同步方式有不小的帮助!
#include <Windows.h>
#include <tchar.h>
#include <process.h>
#include <cstdio>
const int g_loopCount = 1000000;
typedef void(__stdcall *THREADFUNC)();
unsigned int __stdcall ThreadRunFunc(void *lParam)
{
THREADFUNC op = (THREADFUNC)lParam;
for (int i = 0; i < g_loopCount; ++i)
{
// 同步方式读取或者写入数据
op();
}
return 0;
}
VOID CompareStart(TCHAR *pText, unsigned int uiThreadCount, THREADFUNC pFunc)
{
HANDLE *pThreads = new HANDLE[uiThreadCount];
SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_HIGHEST);
for (unsigned int i = 0; i < uiThreadCount; ++i)
{
pThreads[i] = (HANDLE)_beginthreadex(nullptr, 0, ThreadRunFunc, pFunc, 0, nullptr);
}
SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_NORMAL);
LARGE_INTEGER frequency, performencyCountBegin, performencyCountEnd;
QueryPerformanceFrequency(&frequency); // 获取CPU频率
QueryPerformanceCounter(&performencyCountBegin);
WaitForMultipleObjects(uiThreadCount, pThreads, TRUE, INFINITE);
QueryPerformanceCounter(&performencyCountEnd);
LONGLONG llTime = (performencyCountEnd.QuadPart - performencyCountBegin.QuadPart) * 1000 / frequency.QuadPart; // 单位是毫秒
_tprintf(TEXT("Test Name:%s Times:%d ThreadCount:%d\r\n"), pText, (int)llTime, uiThreadCount);
for (unsigned int i = 0; i < uiThreadCount; ++i)
{
CloseHandle(pThreads[i]);
}
delete pThreads;
}
volatile int g_iValue = 0;
// 直接读
void __stdcall DirectRead()
{
int value = g_iValue;
}
// 直接写
void __stdcall DirectWrite()
{
g_iValue = 0;
}
// 原子操作写
void __stdcall InterLockWrite()
{
InterlockedExchangeAdd((long *)&g_iValue, 1);
}
BOOL g_bUsing = FALSE;
// 旋转锁读
void __stdcall SpinLockRead()
{
while (InterlockedExchange((long *)&g_bUsing, TRUE) == FALSE)
{
Sleep(0);
}
int value = g_iValue;
InterlockedExchange((long *)&g_iValue, FALSE);
}
// 旋转锁写
void __stdcall SpinLockWrite()
{
while (InterlockedExchange((long *)&g_bUsing, TRUE) == FALSE)
{
Sleep(0);
}
g_iValue = 0;
InterlockedExchange((long *)&g_iValue, FALSE);
}
CRITICAL_SECTION g_cs;
// 临界区读
void __stdcall CritcalSectionRead()
{
EnterCriticalSection(&g_cs);
int value = g_iValue;
LeaveCriticalSection(&g_cs);
}
// 临界区写
void __stdcall CritcalSectionWrite()
{
EnterCriticalSection(&g_cs);
g_iValue = 0;
LeaveCriticalSection(&g_cs);
}
SRWLOCK g_srwlock;
// 小锁读
void __stdcall SRWLockRead()
{
AcquireSRWLockShared(&g_srwlock);
int value = g_iValue;
ReleaseSRWLockShared(&g_srwlock);
}
// 小锁写
void __stdcall SRWLockWrite()
{
AcquireSRWLockExclusive(&g_srwlock);
g_iValue = 0;
ReleaseSRWLockExclusive(&g_srwlock);
}
int main()
{
for (int i = 1; i <= 16; ++i)
{
CompareStart(TEXT("Direct Read"), i, DirectRead);
CompareStart(TEXT("Direct Write"), i, DirectWrite);
CompareStart(TEXT("Inter Lock Write"), i, InterLockWrite);
CompareStart(TEXT("Spin Lock Read"), i, SpinLockRead);
CompareStart(TEXT("Spin Lock Write"), i, SpinLockWrite);
InitializeCriticalSection(&g_cs);
CompareStart(TEXT("Critical Section Read"), i, CritcalSectionRead);
CompareStart(TEXT("Critical Section Write"), i, CritcalSectionWrite);
DeleteCriticalSection(&g_cs);
InitializeSRWLock(&g_srwlock);
CompareStart(TEXT("SRW Lock Read"), i, SRWLockRead);
CompareStart(TEXT("SRW Lock Write"), i, SRWLockWrite);
_tprintf(TEXT("-------------------------------------------------------\r\n"));
}
system("pause");
return 0;
}结果如下:
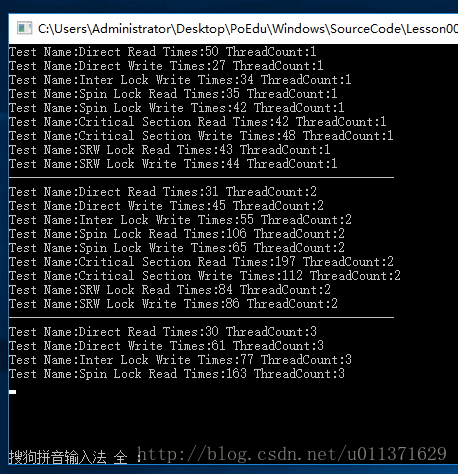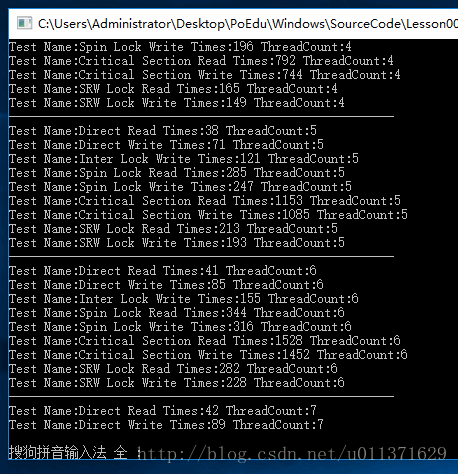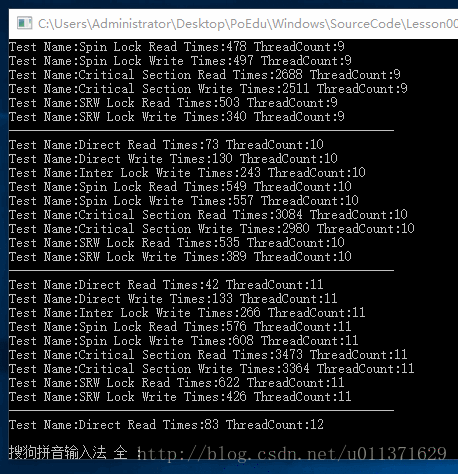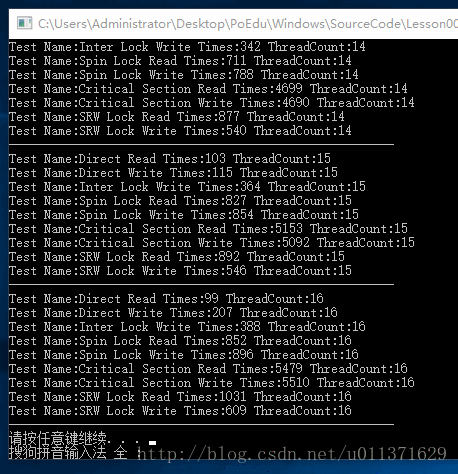
如果看的结果不太清楚,您也可以在您的机器上运行一下这个代码。















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









