







【基础算法】(02) 十二种排序算法(第二篇)
Auther: Thomas Shen
E-mail: Thomas.shen3904@qq.com
Date: 2017/10/20
All Copyrights reserved !
1. 篇述:
本系列总结了常用的十二种排序算法,每个算法都包括算法原理, 代码实现, 面试例题 三部分。
其中本文是排序算法系列的第二篇,介绍了:
- 5. 选择排序—简单选择排序(Simple Selection Sort),
- 6. 选择排序—堆排序(Heap Sort),
- 7. 交换排序—冒泡排序(Bubble Sort) ,
- 8. 鸡尾酒排序/双向冒泡排序
2. 直接插入排序 (Straight Insertion Sort):
3. 二分插入排序 (Binary insert sort):
4. 希尔排序 (Shell’s Sort):
参见第一篇;
5. 选择排序—简单选择排序(Simple Selection Sort):
5.1 原理简介:
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
- 第一趟,从n 个记录中找出关键码最小的记录与第一个记录交换;
- 第二趟,从第二个记录开始的n-1 个记录中再选出关键码最小的记录与第二个记录交换;
- 第i 趟,则从第i 个记录开始的n-i+1 个记录中选出关键码最小的记录与第i 个记录交换;
直到整个序列按关键码有序。

最差时间复杂度:О(n²)
最优时间复杂度:О(n²)
平均时间复杂度:О(n²)
最差空间复杂度:О(n) total, O(1)
5.2 代码实现:
void selection_sort(int *a, int len)
{
register int i, j, min, t;
for(i = 0; i < len - 1; i ++)
{
min = i;
//查找最小值
for(j = i + 1; j < len; j ++)
if(a[min] > a[j])
min = j;
//交换
if(min != i)
{
t = a[min];
a[min] = a[i];
a[i] = t;
}
}
} 5.3 面试例题:
例题1:
在插入和选择排序中,若初始数据基本正序,则选用 插入排序(到尾部);
若初始数据基本反序,则选用 选择排序。
例题2:
下述几种排序方法中,平均查找长度(ASL)最小的是 ( B )
A. 插入排序 B.快速排序 C. 归并排序 D. 选择排序
6. 选择排序—堆排序(Heap Sort):
6.1 原理简介:
堆排序(Heap sort)堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆排序利用堆数据结构。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
6.1.1 什么是堆?
我们这里提到的堆一般都指的是二叉堆,它满足二个特性:
- 父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值;
- 每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
如下为一个最小堆(父结点的键值总是小于任何一个子节点的键值):

初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n 个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n 个元素中次小(或次大)的元素。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。称这个过程为堆排序。
因此,实现堆排序需解决两个问题:
- 如何将n 个待排序的数建成堆;
- 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆。
6.1.2 首先讨论第二个问题:
输出堆顶元素后,对剩余n-1元素重新建成堆的调整过程。
调整小顶堆的方法:
- 设有m 个元素的堆,输出堆顶元素后,剩下m-1 个元素。将堆底元素送入堆顶((最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
- 将根结点与左、右子树中较小元素的进行交换。
- 若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法(2).
- 若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复方法 (2).
- 继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
称这个自根结点到叶子结点的调整过程为筛选。如图:

6.1.3 再讨论对n 个元素初始建堆的过程:
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
- n 个结点的完全二叉树,则最后一个结点是第[ n/2 ]个结点的子树。
- 筛选从第[ n/2 ]个结点为根的子树开始,该子树成为堆。
- 之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
如图建堆初始过程:无序序列:(49,38,65,97,76,13,27,49)

最差时间复杂度O(n log n)
最优时间复杂度O(n log n)
平均时间复杂度O(n log n)
最差空间复杂度 O(n)
6.2 代码实现:
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* 已知H[s…m]除了H[s] 外均满足堆的定义
* 调整H[s],使其成为大顶堆.即将对第s个结点为根的子树筛选,
* @param H是待调整的堆数组
* @param s是待调整的数组元素的位置
* @param length是数组的长度
*/
void HeapAdjust(int H[],int s, int length)
{
int tmp = H[s];
int child = 2*s+1; //左孩子结点的位置。(i+1 为当前调整结点的右孩子结点的位置)
while (child < length) {
if(child+1 <length && H[child]<H[child+1]) { // 如果右孩子大于左孩子(找到比当前待调整结点大的孩子结点)
++child ;
}
if(H[s]<H[child]) { // 如果较大的子结点大于父结点
H[s] = H[child]; // 那么把较大的子结点往上移动,替换它的父结点
s = child; // 重新设置s ,即待调整的下一个结点的位置
child = 2*s+1;
} else { // 如果当前待调整结点大于它的左右孩子,则不需要调整,直接退出
break;
}
H[s] = tmp; // 当前待调整的结点放到比其大的孩子结点位置上
}
print(H,length);
}
/**
* 初始堆进行调整
* 将H[0..length-1]建成堆
* 调整完之后第一个元素是序列的最小的元素
*/
void BuildingHeap(int H[], int length)
{
//最后一个有孩子的节点的位置 i= (length -1) / 2
for (int i = (length -1) / 2 ; i >= 0; --i)
HeapAdjust(H,i,length);
}
/**
* 堆排序算法
*/
void HeapSort(int H[],int length)
{
//初始堆
BuildingHeap(H, length);
//从最后一个元素开始对序列进行调整
for (int i = length - 1; i > 0; --i)
{
//交换堆顶元素H[0]和堆中最后一个元素
int temp = H[i]; H[i] = H[0]; H[0] = temp;
//每次交换堆顶元素和堆中最后一个元素之后,都要对堆进行调整
HeapAdjust(H,0,i);
}
}
int main(){
int H[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"初始值:";
print(H,10);
HeapSort(H,10);
//selectSort(a, 8);
cout<<"结果:";
print(H,10);
} 6.3 面试例题:
例题1:
编写算法,从10亿个浮点数当中,选出其中最大的10000个。
典型的Top K问题,用堆是最典型的思路。建10000个数的小顶堆,然后将10亿个数依次读取,大于堆顶,则替换堆顶,做一次堆调整。结束之后,小顶堆中存放的数即为所求。代码如下(为了方便,这里直接使用了STL容器):
#include "stdafx.h"
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional> // for greater<>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
vector<float> bigs(10000,0);
vector<float>::iterator it;
// Init vector data
for (it = bigs.begin(); it != bigs.end(); it++)
{
*it = (float)rand()/7; // random values;
}
cout << bigs.size() << endl;
make_heap(bigs.begin(),bigs.end(), greater<float>()); // The first one is the smallest one!
float ff;
for (int i = 0; i < 1000000000; i++)
{
ff = (float) rand() / 7;
if (ff > bigs.front()) // replace the first one ?
{
// set the smallest one to the end!
pop_heap(bigs.begin(), bigs.end(), greater<float>());
// remove the last/smallest one
bigs.pop_back();
// add to the last one
bigs.push_back(ff);
// mask heap again, the first one is still the smallest one
push_heap(bigs.begin(),bigs.end(),greater<float>());
}
}
// sort by ascent
sort_heap(bigs.begin(), bigs.end(), greater<float>());
return 0;
} 7. 交换排序—冒泡排序(Bubble Sort):
7.1 原理简介:
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
算法描述:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

最差时间复杂度: O(n^2)
最优时间复杂度: O(n)
平均时间复杂度: O(n^2)
最差空间复杂度: 总共O(n),需要辅助空间O(1)
冒泡排序是与插入排序拥有相等的执行时间,但是两种法在需要的交换次数却很大地不同。在最坏的情况,冒泡排序需要O(n^2)次交换,而插入排序只要最多O(n)交换。冒泡排序的实现(类似下面)通常会对已经排序好的数列拙劣地执行(O(n^2)),而插入排序在这个例子只需要O(n)个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。
冒泡排序如果能在内部循环第一次执行时,使用一个旗标来表示有无需要交换的可能,也有可能把最好的复杂度降低到O(n)。在这个情况,在已经排序好的数列就无交换的需要。若在每次走访数列时,把走访顺序和比较大小反过来,也可以稍微地改进效率。有时候称为往返排序,因为算法会从数列的一端到另一端之间穿梭往返。
7.2 代码实现:
#include <stdio.h>
void bubbleSort(int arr[], int count)
{
int i = count, j;
int temp;
while(i > 0)
{
for(j = 0; j < i - 1; j++)
{
if(arr[j] > arr[j + 1])
{ temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
i--;
}
}
int main()
{
//测试数据
int arr[] = {5, 4, 1, 3, 6};
//冒泡排序
bubbleSort(arr, 5);
//打印排序结果
int i;
for(i = 0; i < 5; i++)
printf("%4d", arr[i]);
} 7.3 面试例题:
把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,不能申请额外的空间。
事实上,这道题放到冒泡排序这里不知道是不是特别合适,只是有一种解法是类似冒泡的思想,如下解法一
解法一:
每次遇到大写字母就往后冒,最后结果即为所求:
#include <stdio.h>
#include <string.h>
//题目以及要求:把一个字符串的大写字母放到字符串的后面,
//各个字符的相对位置不变,不能申请额外的空间。
//判断是不是大写字母
int isUpperAlpha(char c){
if(c >= 'A' && c <= 'Z'){
return 1;
}
return 0;
}
//交换两个字母
void swap(char *a, char *b){
char temp = *a;
*a = *b;
*b = temp;
}
char * mySort(char *arr, int len){
if(arr == NULL || len <= 0){
return NULL;
}
int i = 0, j = 0, k = 0;
for(i = 0; i < len; i++){
for(j = len - 1 - i; j >= 0; j--){
if(isUpperAlpha(arr[j])){
for(k = j; k < len - i - 1; k++){
swap(&arr[k], &arr[k + 1]);
}
break;
}
//遍历完了字符数组,但是没发现大写字母,所以没必要再遍历下去
if(j == 0 && !isUpperAlpha(arr[j])){
//结束;
return arr;
}
}
}
//over:
return arr;
}
int main(){
char arr[] = "aaaaaaaaaaaaaaaaaaaaaaaAbcAdeBbDc";
printf("%s\n", mySort(arr, strlen(arr)));
return 0;
} 解法二:
步骤如下
- 两个指针p1和p2,从后往前扫描;
- p1遇到一个小写字母时停下, p2遇到大写字母时停下,两者所指向的char交换;
- p1, p2同时往前一格。
代码如下:
#include <stdio.h>
#include <string.h>
//判断是不是大写字母
int isUpperAlpha(char c){
if(c >= 'A' && c <= 'Z'){
return 1;
}
return 0;
}
//交换两个字母
void swap(char *a, char *b){
char temp = *a;
*a = *b;
*b = temp;
}
char * Reorder(char *arr, int len){
if(arr == NULL || len <= 0){
return NULL;
}
int *p1 = arr;
int *p2 = arr;
While(p1<arr+len && p2<arr+len){
While( isUpperAlpha(*p1) ){
P1++;
}
While( !isUpperAlpha(*p2) ){
P2++;
}
swap(p1, p2);
}
//结束
return arr;
}
int main(){
char arr[] = "aaaaaaaaaaaaaaaaaaaaaaaAbcAdeBbDc";
printf("%s\n", Reorder(arr, strlen(arr)));
return 0;
} 7.4 冒泡排序算法的改进:
对冒泡排序常见的改进方法是加入一标志性变量exchange,用于标志某一趟排序过程中是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。本文再提供以下两种改进算法:
- 设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
void Bubble_1 ( int r[], int n) {
int i= n -1; //初始时,最后位置保持不变
while ( i> 0) {
int pos= 0; //每趟开始时,无记录交换
for (int j= 0; j< i; j++)
if (r[j]> r[j+1]) {
pos= j; //记录交换的位置
int tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
i= pos; //为下一趟排序作准备
}
} - 第二种优化算法参见 [ 8. 鸡尾酒排序/双向冒泡排序 ]。
8. 鸡尾酒排序/双向冒泡排序:
8.1 原理简介:
鸡尾酒排序等于是冒泡排序的轻微变形。不同的地方在于从低到高然后从高到低,而冒泡排序则仅从低到高去比较序列里的每个元素。他可以得到比冒泡排序稍微好一点的效能,原因是冒泡排序只从一个方向进行比对(由低到高),每次循环只移动一个项目。
算法描述和分析:
- 依次比较相邻的两个数,将小数放在前面,大数放在后面;
- 第一趟可得到:将最大数放到最后一位。
- 第二趟可得到:将第二大的数放到倒数第二位。
- 如此下去,重复以上过程,直至最终完成排序。

鸡尾酒排序最糟或是平均所花费的次数都是O(n^2),但如果序列在一开始已经大部分排序过的话,会接近O(n)。
最差时间复杂度 O(n^2)
最优时间复杂度 O(n)
平均时间复杂度 O(n^2)
8.2 代码实现:
void CocktailSort(int *a,int nsize)
{
int tail=nsize-1;
for (int i=0;i<tail;)
{
for (int j=tail;j>i;--j) //第一轮,先将最小的数据排到前面
{
if (a[j]<a[j-1])
{
int temp=a[j];
a[j]=a[j-1];
a[j-1]=temp;
}
}
++i; //原来i处数据已排好序,加1
for (j=i;j<tail;++j) //第二轮,将最大的数据排到后面
{
if (a[j]>a[j+1])
{
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
tail--; //原tail处数据也已排好序,将其减1
}
} 9. 交换排序—快速排序(Quick Sort):
10. 归并排序(Merge Sort):
11. 桶排序 (Bucket sort):
12. 计数排序 (Counting sort):
13. 基数排序 (Radix Sort):
参见第三、四篇;
14. 总结:
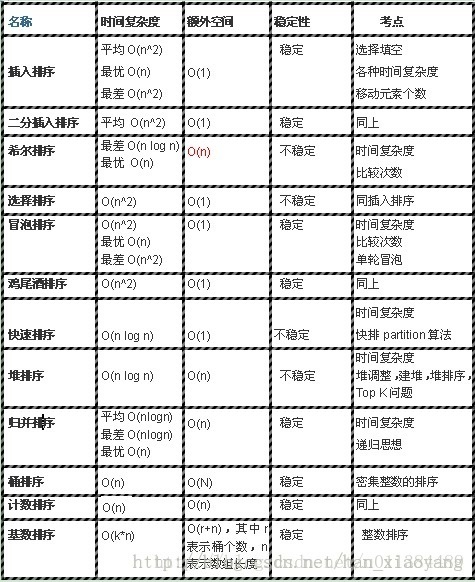
References. :
- [ 1 ]. Coursera | Java程序设计 | PKU
- [ 2 ]. 转载自:八大排序算法
- [ 3 ]. 转载自:12种排序算法详解
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









