







LongAdder是jdk8新增的用于并发环境的计数器,目的是为了在高并发情况下,代替AtomicLong/AtomicInt,成为一个用于高并发情况下的高效的通用计数器。
高并发下计数,一般最先想到的应该是AtomicLong/AtomicInt,AtmoicXXX使用硬件级别的指令 CAS 来更新计数器的值,这样可以避免加锁,机器直接支持的指令,效率也很高。但是AtomicXXX中的 CAS 操作在出现线程竞争时,失败的线程会白白地循环一次,在并发很大的情况下,因为每次CAS都只有一个线程能成功,竞争失败的线程会非常多。失败次数越多,循环次数就越多,很多线程的CAS操作越来越接近 自旋锁(spin lock)。计数操作本来是一个很简单的操作,实际需要耗费的cpu时间应该是越少越好,AtomicXXX在高并发计数时,大量的cpu时间都浪费会在 自旋 上了,这很浪费,也降低了实际的计数效率。
// jdk1.8的AtomicLong的实现代码,这段代码在sun.misc.Unsafe中
// 当线程竞争很激烈时,while判断条件中的CAS会连续多次返回false,这样就会造成无用的循环,循环中读取volatile变量的开销本来就是比较高的
// 因为这样,在高并发时,AtomicXXX并不是那么理想的计数方式
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!compareAndSwapLong(o, offset, v, v + delta));
return v;
}
说LongAdder比在高并发时比AtomicLong更高效,这么说有什么依据呢?LongAdder是根据ConcurrentHashMap这类为并发设计的类的基本原理——锁分段,来实现的,它里面维护一组按需分配的计数单元,并发计数时,不同的线程可以在不同的计数单元上进行计数,这样减少了线程竞争,提高了并发效率。本质上是用空间换时间的思想,不过在实际高并发情况中消耗的空间可以忽略不计。
现在,在处理高并发计数时,应该优先使用LongAdder,而不是继续使用AtomicLong。当然,线程竞争很低的情况下进行计数,使用Atomic还是更简单更直接,并且效率稍微高一些。
其他情况,比如序号生成,这种情况下需要准确的数值,全局唯一的AtomicLong才是正确的选择,此时不应该使用LongAdder。
下面简要分析下LongAdder的源码,有了ConcurrentHashMap(LongAdder比较像1.6和1.7的,可以看下1.7的)的基础,这个类的源码看起来也不复杂。
一、类的关系
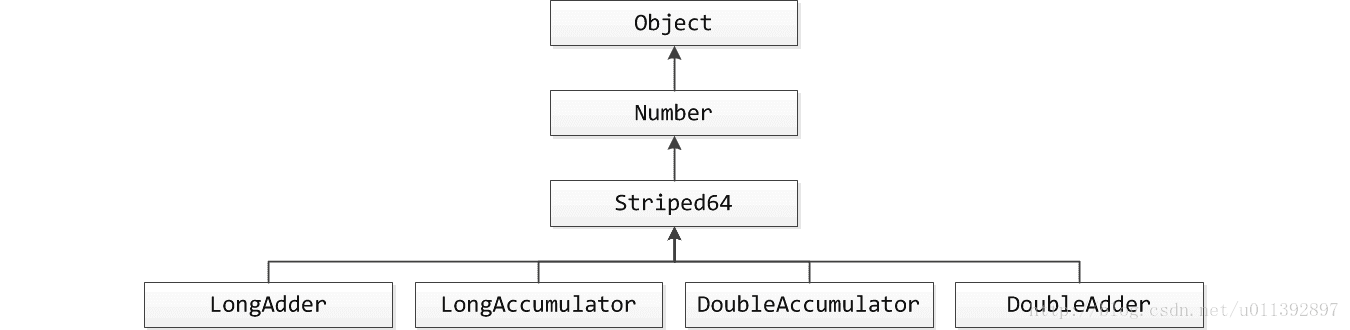
公共父类Striped64是实现中的核心,它实现一些核心操作,处理64位数据,很容易就能转化为其他基本类型,是个通用的类。二元算术运算累积,指的是你可以给它提供一个二元算术方式,这个类按照你提供的方式进行算术计算,并保存计算结果。二元运算中第一个操作数是累积器中某个计数单元当前的值,另外一个值是外部提供的。
举几个例子:
假设每次操作都需要把原来的数值加上某个值,那么二元运算为 (x, y) -> x+y,这样累积器每次都会加上你提供的数字y,这跟LongAdder的功能基本上是一样的;
假设每次操作都需要把原来的数值变为它的某个倍数,那么可以指定二元运算为 (x, y) -> x*y,累积器每次都会乘以你提供的数字y,y=2时就是通常所说的每次都翻一倍;
假设每次操作都需要把原来的数值变成它的5倍,再加上3,再除以2,再减去4,再乘以你给定的数,最后还要加上6,那么二元运算为 (x, y) -> ((x*5+3)/2 - 4)*y +6,累积器每次累积操作都会按照你说的做;
......
LongAccumulator是标准的实现类,LongAdder是特化的实现类,它的功能等价于LongAccumulator((x, y) -> x+y, 0L)。它们的区别很简单,前者可以进行任何二元算术操作,后者只能进行加减两种算术操作。
Double版本是Long版本的简单改装,相对Long版本,主要的变化就是用Double.longBitsToDouble 和Double.doubleToRawLongBits对底层的8字节数据进行long <---> double转换,存储的时候使用long型,计算的时候转化为double型。这是因为CAS是sun.misc.Unsafe中提供的操作,只对int、long、对象类型(引用或者指针)提供了这种操作,其他类型都需要转化为这三种类型才能进行CAS操作。这里的long型也可以认为是8字节的原始类型,因为把它视为long类型是无意义的。java中没有C语言中的 void* 无类型(或者叫原始类型),只能用最接近的long类型来代替。
四个实现类的区别就上面这两句话,这里只讲LongAdder一个类。
二、核心实现Striped64
四个类的核心实现都在Striped64中,这个类使用分段的思想,来尽量平摊并发压力。类似1.7及以前版本的ConcurrentHashMap.Segment,Striped64中使用了一个叫Cell的类,是一个普通的二元算术累积单元,线程也是通过hash取模操作映射到一个Cell上进行累积。为了加快取模运算效率,也把Cell数组的大小设置为2^n,同时大量使用Unsafe提供的底层操作。基本的实现桶1.7的Concurr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4764
4764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









