







caffe层的类型图有:
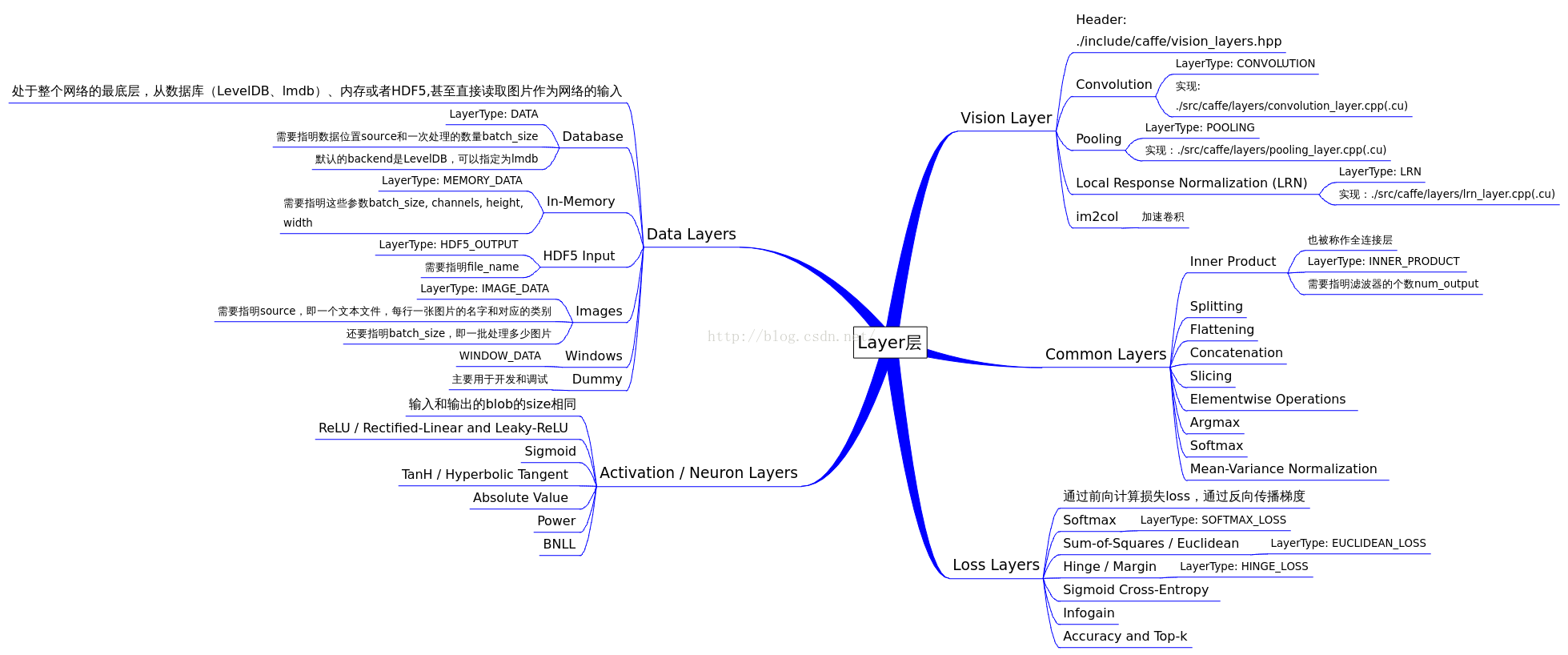
caffe官方对层的分类为:http://caffe.berkeleyvision.org/tutorial/layers.html
caffe Net在proto文件中的定义为:
message NetParameter {
optional string name = 1; //net的名字
// DEPRECATED. See InputParameter. The input blobs to the network.
repeated string input = 3;
// DEPRECATED. See InputParameter. The shape of the input blobs.
repeated BlobShape input_shape = 8;
repeated int32 input_dim = 4;
optional bool force_backward = 5 [default = false];//层是否进行反向传播自动地取决于网络架构和学习状态,为真则强制进行反向传播计算
optional NetState state = 6;
optional bool debug_info = 7 [default = false];//在网络进行forward,backword,update时打印debugging信息
// The layers that make up the net. Each of their configurations, including connectivity and behavior, is specified as a LayerParameter.
repeated LayerParameter layer = 100; // ID 100 so layers are printed last.
}layerParameter的proto定义有
message LayerParameter {
optional string name = 1; // the layer name
optional string type = 2; // the layer type
repeated string bottom = 3; // the name of each bottom blob
repeated string top = 4; // the name of each top blob
// The train / test phase for computation.
optional Phase phase = 10;
// The amount of weight to assign each top blob in the objective.
// Each layer assigns a default value, usually of either 0 or 1,
// to each top blob.
repeated float loss_weight = 5;
// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
repeated ParamSpec param = 6;
// The blobs containing the numeric parameters of the layer.
repeated BlobProto blobs = 7;
// Specifies whether to backpropagate to each bottom. If unspecified,
// Caffe will automatically infer whether each input needs backpropagation
// to compute parameter gradients. If set to true for some inputs,
// backpropagation to those inputs is forced; if set false for some inputs,
// backpropagation to those inputs is skipped.
//
// The size must be either 0 or equal to the number of bottoms.
repeated bool propagate_down = 11;//是否进行反向传播计算,true则自动判断是否需要,false则强制跳过
// Rules controlling whether and when a layer is included in the network,
// based on the current NetState. You may specify a non-zero number of rules
// to include OR exclude, but not both. If no include or exclude rules are
// specified, the layer is always included. If the current NetState meets
// ANY (i.e., one or more) of the specified rules, the layer is
// included/excluded.
repeated NetStateRule include = 8;
repeated NetStateRule exclude = 9;
// Parameters for data pre-processing.
optional TransformationParameter transform_param = 100;
// Parameters shared by loss layers.
optional LossParameter loss_param = 101;
// Layer type-specific parameters.
optional AccuracyParameter accuracy_param = 102;
optional ArgMaxParameter argmax_param = 103;
optional BatchNormParameter batch_norm_param = 139;
optional BiasParameter bias_param = 141;
optional ConcatParameter concat_param = 104;
optional ContrastiveLossParameter contrastive_loss_param = 105;
optional ConvolutionParameter convolution_param = 106;
optional CropParameter crop_param = 144;
optional DataParameter data_param = 107;
optional DropoutParameter dropout_param = 108;
optional DummyDataParameter dummy_data_param = 109;
optional EltwiseParameter eltwise_param = 110;
optional ELUParameter elu_param = 140;
optional EmbedParameter embed_param = 137;
optional ExpParameter exp_param = 111;
optional FlattenParameter flatten_param = 135;
optional HDF5DataParameter hdf5_data_param = 112;
optional HDF5OutputParameter hdf5_output_param = 113;
optional HingeLossParameter hinge_loss_param = 114;
optional ImageDataParameter image_data_param = 115;
optional InfogainLossParameter infogain_loss_param = 116;
optional InnerProductParameter inner_product_param = 117;
optional InputParameter input_param = 143;
optional LogParameter log_param = 134;
optional LRNParameter lrn_param = 118;
optional MemoryDataParameter memory_data_param = 119;
optional MVNParameter mvn_param = 120;
optional ParameterParameter parameter_param = 145;
optional PoolingParameter pooling_param = 121;
optional PowerParameter power_param = 122;
optional PReLUParameter prelu_param = 131;
optional PythonParameter python_param = 130;
optional RecurrentParameter recurrent_param = 146;
optional ReductionParameter reduction_param = 136;
optional ReLUParameter relu_param = 123;
optional ReshapeParameter reshape_param = 133;
optional ScaleParameter scale_param = 142;
optional SigmoidParameter sigmoid_param = 124;
optional SoftmaxParameter softmax_param = 125;
optional SPPParameter spp_param = 132;
optional SliceParameter slice_param = 126;
optional TanHParameter tanh_param = 127;
optional ThresholdParameter threshold_param = 128;
optional TileParameter tile_param = 138;
optional WindowDataParameter window_data_param = 129;
}相关的一些Message有:
NetState
message NetState {
optional Phase phase = 1 [default = TEST];
optional int32 level = 2 [default = 0];
repeated string stage = 3;
}paramSpec
// Specifies training parameters (multipliers on global learning constants,
// and the name and other settings used for weight sharing).
message ParamSpec {
// The names of the parameter blobs -- useful for sharing parameters among
// layers, but never required otherwise. To share a parameter between two
// layers, give it a (non-empty) name.
optional string name = 1;
// Whether to require shared weights to have the same shape, or just the same
// count -- defaults to STRICT if unspecified.
optional DimCheckMode share_mode = 2;
enum DimCheckMode {
// STRICT (default) requires that num, channels, height, width each match.
STRICT = 0;
// PERMISSIVE requires only the count (num*channels*height*width) to match.
PERMISSIVE = 1;
}
// The multiplier on the global learning rate for this parameter.
optional float lr_mult = 3 [default = 1.0];
// The multiplier on the global weight decay for this parameter.
optional float decay_mult = 4 [default = 1.0];
}NetstateRule
message NetStateRule {
// Set phase to require the NetState have a particular phase (TRAIN or TEST)
// to meet this rule.
optional Phase phase = 1;
// Set the minimum and/or maximum levels in which the layer should be used.
// Leave undefined to meet the rule regardless of level.
optional int32 min_level = 2;
optional int32 max_level = 3;
// Customizable sets of stages to include or exclude.
// The net must have ALL of the specified stages and NONE of the specified
// "not_stage"s to meet the rule.
// (Use multiple NetStateRules to specify conjunctions of stages.)
repeated string stage = 4;
repeated string not_stage = 5;
}LossParameter
// Message that stores parameters shared by loss layers
message LossParameter {
// If specified, ignore instances with the given label.
optional int32 ignore_label = 1;
// How to normalize the loss for loss layers that aggregate across batches,
// spatial dimensions, or other dimensions. Currently only implemented in
// SoftmaxWithLoss and SigmoidCrossEntropyLoss layers.
enum NormalizationMode {
// Divide by the number of examples in the batch times spatial dimensions.
// Outputs that receive the ignore label will NOT be ignored in computing
// the normalization factor.
FULL = 0;
// Divide by the total number of output locations that do not take the
// ignore_label. If ignore_label is not set, this behaves like FULL.
VALID = 1;
// Divide by the batch size.
BATCH_SIZE = 2;
// Do not normalize the loss.
NONE = 3;
}
// For historical reasons, the default normalization for
// SigmoidCrossEntropyLoss is BATCH_SIZE and *not* VALID.
optional NormalizationMode normalization = 3 [default = VALID];
// Deprecated. Ignored if normalization is specified. If normalization
// is not specified, then setting this to false will be equivalent to
// normalization = BATCH_SIZE to be consistent with previous behavior.
optional bool normalize = 2;
}














 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









