






参考了很多博客,只是整理一些自己想了解的知识,大家一起学习!
1 POD
pod是k8s最小的操作单元
同一pod内的容器是不会分散到不同节点之上的,因为pod是k8s资源中的最小单位,不能把它的内容分散开部署 。pod内部可以封装一个容器,也可以封装多个容器;在物理机节点上,pod和pod之间是相互独立;
pod之间的网络通信:
https://blog.csdn.net/qq_42642159/article/details/122719094
2、etcd数据存储
etcd是一个高可用分布式的非关系型数据库,核心算法Raft。具有以下特点:
数据一致性:存储到集群中的值必然是全局一致的。
完全复制:集群中每个节点都有完整的存档;
高可用性:避免单点故障或者硬件问题,集群之间没有单点故障。
多节点之间采用Raft算法保障数据一致性.
Raft:ETCD所采用的保证分布式系统强一致性的算法
Leader:Raft算法中通过竞选而产生的处理所有数据提交的节点
Follower:竞选失败的节点作为Raft中的从属节点, 为算法提供强一致性保证
Candidate:Follower超过一定的时间还接收不到Leader的心跳时, 会转变为Candidate开始竞选。
具体内容可参考:https://blog.csdn.net/solihawk/article/details/127270482
3、docker
docker是容器,而k8s可以理解为容器管理工具。
Docker基于LXC来实现类似VM的功能,可以在更有限的硬件资源上提供给用户更多的计算资源。与同VM等虚拟化的方式不同,LXC不属于全虚拟化、部分虚拟化或半虚拟化中的任何一个分类,而是一个操作系统级虚拟化。
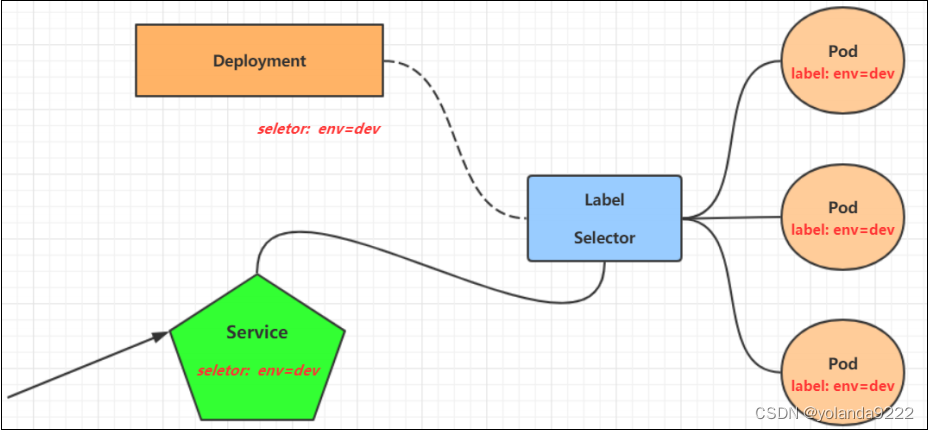
4、service
Service 资源主要用于为 Pod 对象提供一个固定、统一的访问接口及负载均衡的能力。
service 是一组具有相同 label pod 集合的抽象,集群内外的各个服务可以通过 service 进行互相通信。
endpoint 是 k8s 集群中的一个资源对象,存储在 etcd 中,用来记录一个 service 对应的所有 pod 的访问地址。
k8s中pod通过label标签名称来识别关联,它们的label name一定是一样的。ingress,service,depoyment通过标签选择器selector 中app:name来关联
5、异常状态排查
Pod 处于 CrashLoopBackOff 状态:
说明该 Pod 在正常启动过后异常退出过,此状态下 Pod 的 restartPolicy 如果不是 Never 就可能会被重启拉起,且 Pod 的 RestartCounts 通常大于0。
可能原因:
1、容器进程主动退出 :退出状态码通常在0 - 128之间,导致异常的原因可能是业务程序 Bug,也可能是其他原因。
2、系统 OOM:如果发生系统 OOM,Pod 中容器退出状态码为137,表示其被 SIGKILL 信号停止,同时内核将会出现以下报错信息。Out of memory: Kill process …
3、cgroup OOM:如果是因 cgroup OOM 而停止的进程,可看到 Pod 事件下 Reason 为 OOMKilled,说明容器实际占用的内存已超过 limit,同时内核日志会报 Memory cgroup out of memory 错误信息。

4、节点内存碎片化:
健康检查失败。Kubernetes 健康检查包含就绪检查(readinessProbe)和存活检查(livenessProbe),不同阶段的检查失败将会分别出现以下现象:
Pod IP 从 Service 中摘除。通过 Service 访问时,流量将不会被转发给就绪检查失败的 Pod。
kubelet 将会停止容器并尝试重启。
简言之:
容器中部署的程序存在Bug,无法正常启动,就会出现此状态,可以查询容器的启动日志,从日志中获取重要线索,逐个进行排查定义Pod资源时,对于Pod中的容器进行了资源限额,可能限额的资源不够容器使用,就会导致Pod处于此状态。
CrashLoopBackOff状态存在偶发性,可能上一秒还是Running状态,下一秒就成了CrashLoopBackOff状态了。一般Pod资源处于CrashLoopBackOff状态都是和容器有关,通过排查容器输出的日志即可解决问题。
6、授权绑定
角色
代表着一组定义在资源上的可操作动作(权限)的集合,用于指定一组权限。
Role:授权特定命名空间的访问权限
ClusterRole:授权所有命名空间的访问权限
角色绑定
RoleBinding:将角色绑定到主体(即subject)
subject包括:主体(subject)、User:用户 Group:用户组 以及 ServiceAccount:服务账号)
ClusterRoleBinding:将集群角色绑定到主体
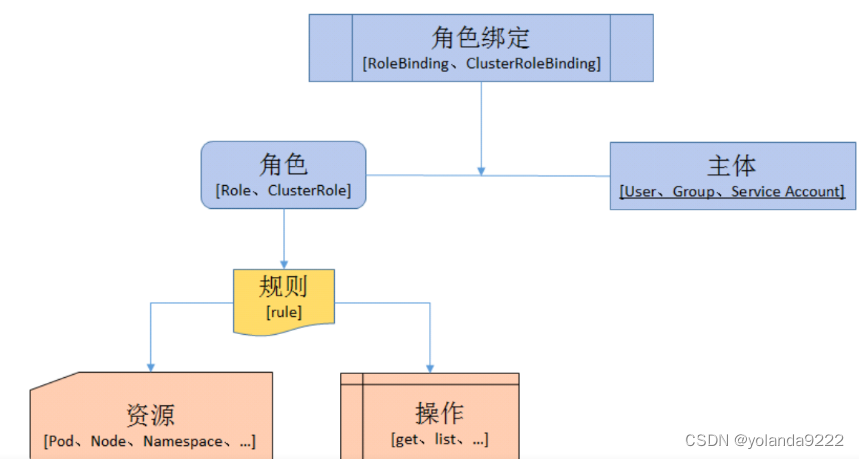
定义好了角色也就是一个权限的集合,然后创建了一个ServiceAccount也就是一个服务账号,然后将这两个东西绑定起来,就是授权的过程了。
7、master节点和node节点
K8S集群的master节点和node节点,区别就是运行的服务不一样
master节点运行的服务:Etcd、ApiServer、ControllerManager、Scheduler
node节点运行的服务:Kubelet、Kube-Proxy
参考:https://blog.csdn.net/u010264186/article/details/108659488
Etcd:K8S集群的数据中心,所有的资源都会存储到etcd中,K8S在启动的时候,都会去Etcd读取数据
Apiserver:K8S最核心的服务,我们在敲入命令对K8S进行操作的时候,由Apiserver来执行我们输入的命令,调度系统
ControllerManager:直译过来就是控制中心,字面意思也能看出来,它的作用就是控制容器,一直监控容器的状态,如果出现了异常,会对容器进行重启、删除创建新容器等等操作
Scheduler:K8S集群的调度中心,它监控node节点的状态,获取集群资源,按照预设的分配规则或者系统自己处理,合理分配使用集群的所有资源,来确定使用哪个node来执行任务(再说通俗点就是决定把pod创建到哪台node上)
Kubelet:控制node节点上的容器
Kube-Proxy:在node节点上的容器起该服务,可以在node机器上映射一个端口,通过node ip+port,可供外部用户的访问
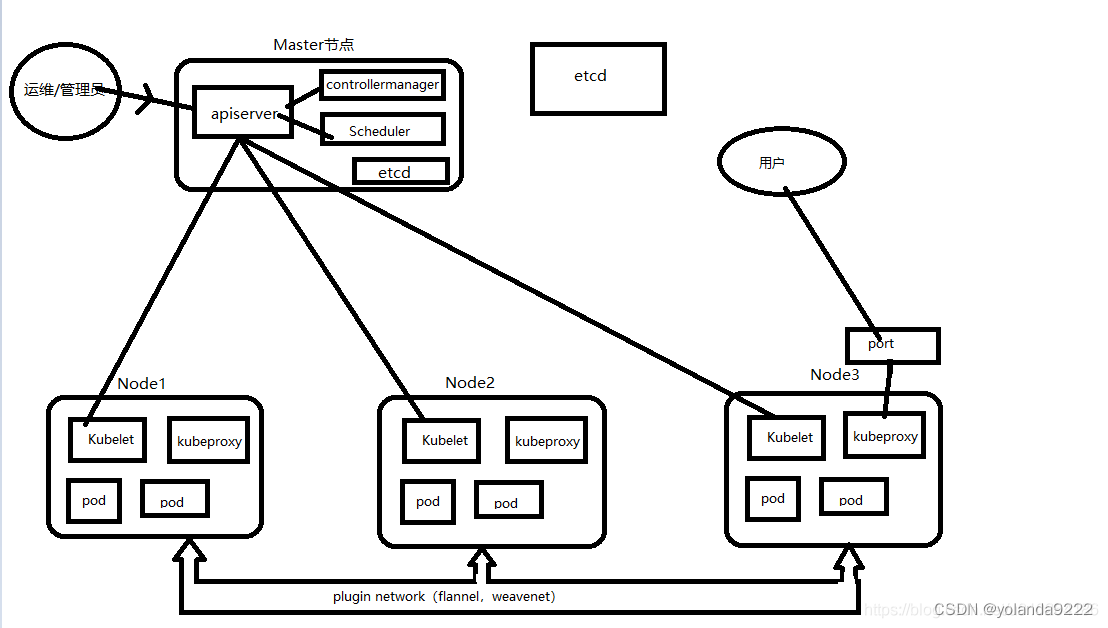
用户执行命令,apiserver来执行调度,执行命令,controller manager保证每一个pod都高可用,pod一旦挂死,就重启,重启失败或者pod所在的node都挂死,就在另外的node上启动pod,确保pod的高可用;scheduler获取集群的资源情况,合理分配pod起在那个node上;etcd存储整个K8S的数据、资源,每当K8S启动时,都会去etcd读取数据
Kubelet直接接受apiserver的调度,apiserver控制kubelet创建pod,kubelet控制pod创建容器;
kubeproxy可以映射端口,将服务的端口暴露出来,这样用户可以访问到这个node中的服务
上图可以看到2个etcd,是为了说明etcd其实可以直接部署在master接点上,也可以单独部署,只需要在部署K8S的时候,指定好etcd即可。只需要选择一种方式就好
补充说明一点,容器之间需要扩主机通信时,此时就需要网络插件plugin network,有多种插件可供使用。本章节原文链接:https://blog.csdn.net/u010264186/article/details/108659488
8、健康探查
默认情况下,kubelet根据容器运行状态作为健康依据,不能监控容器中应用程序状态,例如程序假死。这就会导致无法提供服务,丢失流量。因此引入健康检查机制确保容器健康存活。
Pod通过两类探针来检查容器的健康状态:
livenessProbe(存活探测)
通过http、shell命令或者tcp等方式去检测容器中的应用是否健康,然后将检查结果返回给kubelet,如果检查容器中应用为不健康状态提交给kubelet后,kubelet将根据Pod配置清单中定义的重启策略restartPolicy来对Pod进行重启。
readinessProbe(就绪探测)
通过http、shell命令或者tcp等方式去检测容器中的应用是否健康或则是否能够正常对外提供服务,如果能够正常对外提供服务,则认为该容器为(Ready状态),达到(Ready状态)的Pod才可以接收请求。避免Pod对象启动后立即让其处理客户端请求,而是等待容器初始化工作执行完成并转为Ready状态后再接收客户端请求。如果容器或则Pod状态为(NoReady)状态,Kubernetes则会把该Pod从Service的后端endpoints Pod中去剔除。
以上两种探测通过如下几种方式对容器进行健康检查:
ExecAction:在容器中执行命令,命令执行后返回的状态为0则成功,表示我们探测结果正常
TCPSocketAction: 通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康
HTTPGetAction: 通过容器的IP地址,端口号以及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康
9、隔离机制
由于容器本身之间相互隔离,通过linux namespace、group组实现隔离。那么space用于隔离文件系统,进程和网络。
(1) 文件系统隔离:每个容器都有自己的root文件系统
(2) 进程隔离:每个容器都运行在自己的进程环境
(3) 网络隔离:容器间的虚拟网络接口和IP都是分开的
pod要实现共享网络机制,需要具备同一个pod里面的容器共享namespace。
10、kube-Proxy
kube-proxy 是 Kubernetes 的核心组件,部署在每个 Node 节点上,它是实现 Kubernetes Service 的通信与负载均衡机制的重要组件; kube-proxy 负责为 Pod 创建代理服务,从 apiserver 获取所有 server 信息,并根据 server 信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
在 k8s 中提供相同服务的一组 pod 可以抽象成一个 service,通过 service 提供统一的服务对外提供服务,kube-proxy 存在于各个 node 节点上,负责为 service 提供 cluster 内部的服务发现和负载均衡,负责 Pod 的网络代理,它会定时从 etcd 中获取 service 信息来做相应的策略,维护网络规则和四层负载均衡工作。k8s 中集群内部的负载均衡就是由 kube-proxy 实现的,它是 k8s 中内部的负载均衡器,也是一个分布式代理服务器,可以在每个节点中部署一个,部署的节点越多,提供负载均衡能力的 Kube-proxy 就越多,高可用节点就越多。
简单点讲就是 k8s 内部的 pod 要访问 service ,kube-proxy 会将请求转发到 service 所代表的一个具体 pod,也就是 service 关联的 Pod。














 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









