







目录
什么是循环依赖
概念
spring中多个bean互相引用
图示

代码示例
@Component
public class BeanA {
@Autowired
private BeanB beanB;
}
@Component
public class BeanB {
@Autowired
private BeanA beanA;
}
spring如何解决循环依赖?
注意
下属两种情况未解决循环依赖问题:
1.构造器注入
2.非单例
这个不用记,只是提一下。
言归正传,先说结论
用了一个map(这个map也就是常说的第三级缓存):
 不管有没有aop,都只用了这个map解决循环依赖。
不管有没有aop,都只用了这个map解决循环依赖。
你可能看其他资料说在有aop的情况下,使用了二级缓存来解决循环依赖,我认为这是错误的。
接下来会详解三级缓存,看完就明白为什么错了。
三级缓存介绍
// 1级缓存:属性赋值完成的bean,可以被spring拿来用了
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 2级缓存:调用3级缓存后,临时存放(不是每个bean都会调用第3级缓存的)
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 3级缓存:每个bean都会用到,在初始化bean之后,注入依赖前,会加入该map
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
源码简单分析
源码流程图
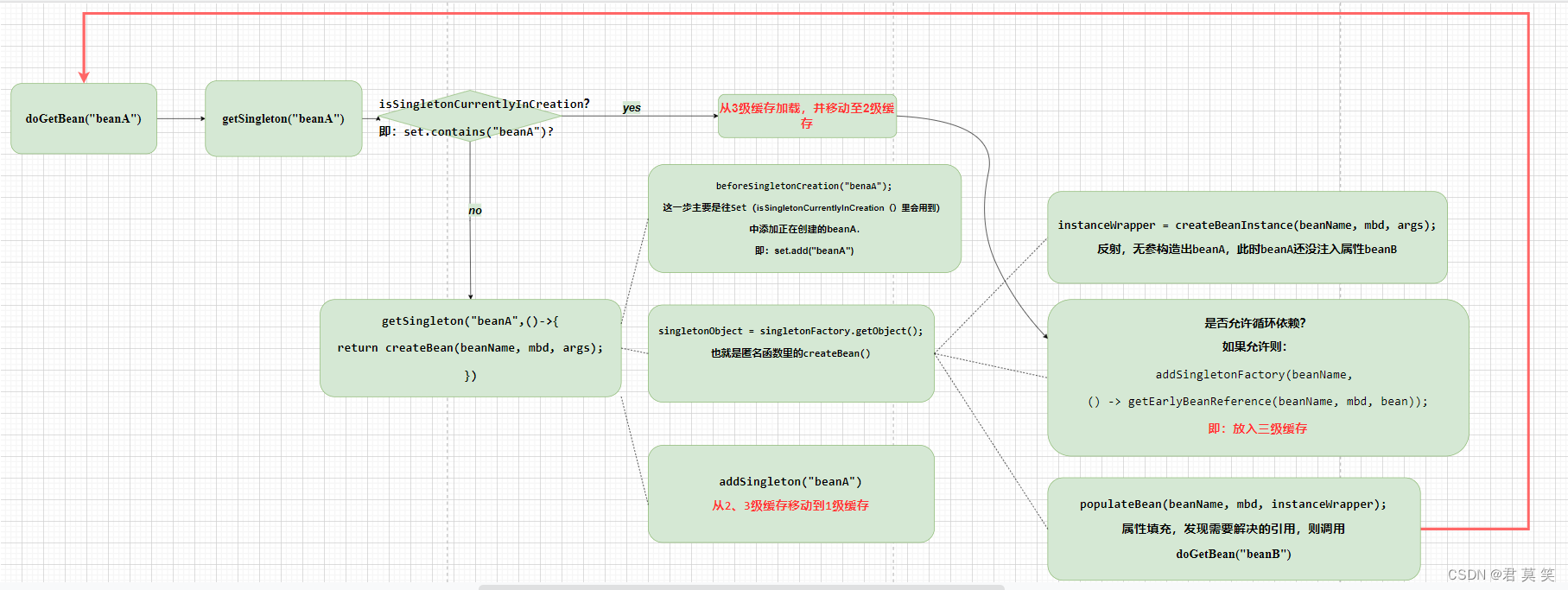
图1 循环依赖流程图
 上面这幅图是某书里的,比较简洁,我再具体描述一下(暂时不讨论AOP,下文会说到):
上面这幅图是某书里的,比较简洁,我再具体描述一下(暂时不讨论AOP,下文会说到):
- 0.从缓存查找beanA,没有
- 1.初始化beanA(没有注入beanB)
- 2.beanA加入第3级缓存
- 3.populate(),开始填充beanB
- 3.0 从缓存查找beanB,没有
- 3.1 初始化beanB
- 3.2 beanB加入第3级缓存
- 3.3 poputele(),开始填充beanB
- 3.3.0 从缓存查找 beanA,发现beanA在创建中,于是可以掏出3级缓存,进行beanA的创建(注意,如果beanA被代理的话,其代理对象也是这一步创建的)
- 3.3.1 beanA创建完后,移动到第2级缓存(还没注入属性beanB)
- 3.4 beanB中的属性beanA注入完成
- 4 beanA中的属性beanB注入完成
详解循环依赖
上面的流程,应该算比较容易理解的。
大致意思就是:创建beanA的时候发现依赖beanB,于是创建beanB,此时又发现依赖beanA,于是又去创造beanA。
那么这是不是死循环了呢?
所以我们先看看循环终止条件:
循环终止条件在此方法里

看懂这个方法就能理解循环依赖了。
下面详细讲一下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从1级缓存拿
Object singletonObject = this.singletonObjects.get(beanName);
// 1级缓存拿不到,则去2级缓存拿
// 不要忽略isSingletonCurrentlyInCreation这个方法,得益于这个方法,我们才能终止循环,下文会详解
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从2级缓存拿
singletonObject = this.earlySingletonObjects.get(beanName);
// 从3级缓存拿.注意,如果allowEarlyReference是false,则不会进入
if (singletonObject == null && allowEarlyReference) {
// 则从3级缓存加载,最后移动到2级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用3级缓存,getEarlyBeanReference(beanName, mbd, bean)
singletonObject = singletonFactory.getObject();
// 放入2级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
上述代码我加了注释,应该比较容易理解,但是两个要注意的点:
1.isSingletonCurrentlyInCreation(循环终止条件判断)
如下图,如果一个bean存在于该set中,则开始调用第3级缓存中的方法,产生bean。
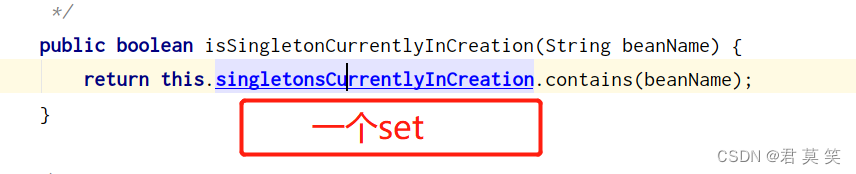
那beanName是什么时候加入这个set的呢?
在createBean之前(),会先将beanName添加进该set中,代表这个bean正在被创建。
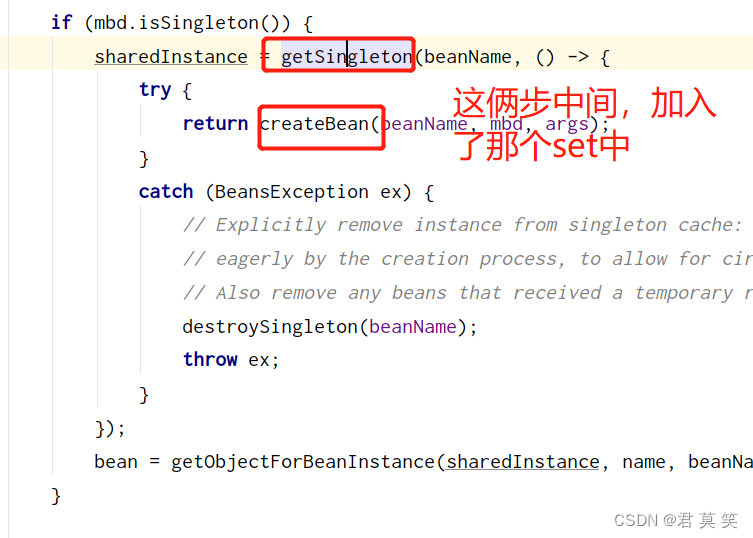
这也就能理解,为什么spring创建bean的代码会像下图这样,用:(注意这个getSingleton和上面那个不一样,是重载方法):
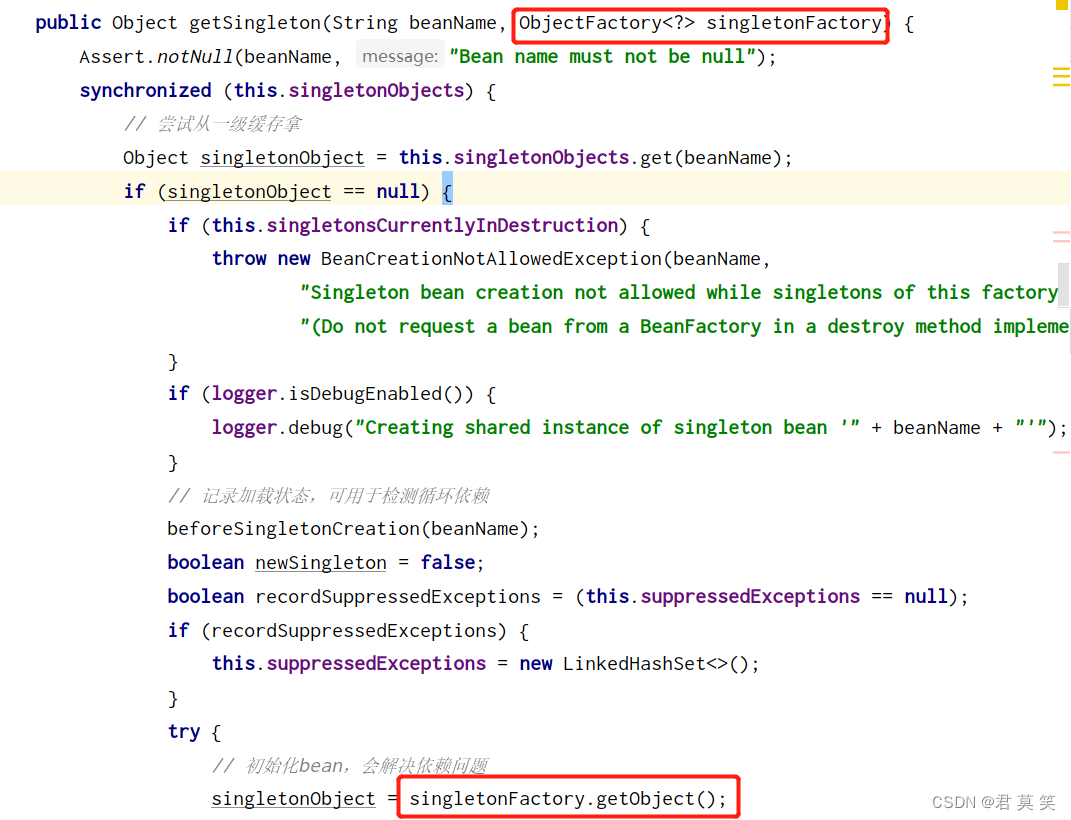
可能有人看不太懂这个写法,如下图,这是个函数式接口,里面只有一个方法:getObject()。
调用getObject()即可调用上图的createBean()。
下图中的beforeSingletonCreation(),就是set.add()的步骤。
而singletonFactory.getObject就会调用上图中的createBean()
那么使用set,来终止循环依赖,像不像一道经典算法题:
如何判断一个链表(或者图)成环?
2.allowEarlyReference
boolean类型的变量,
注意,
根据上面的代码,只有allowEarlyReference为true,才能调用第3级缓存!
而调用完第3级缓存,马上会移动到第2级缓存!
知道你们懒得回去翻,我直接再copy一次:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从1级缓存拿
Object singletonObject = this.singletonObjects.get(beanName);
// 1级缓存拿不到,则去2级缓存拿
// 不要忽略isSingletonCurrentlyInCreation这个方法,得益于这个方法,我们才能终止循环,下文会详解
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从2级缓存拿
singletonObject = this.earlySingletonObjects.get(beanName);
// 从3级缓存拿.注意,如果allowEarlyReference是false,则不会进入
if (singletonObject == null && allowEarlyReference) {
// 则从3级缓存加载,最后移动到2级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用3级缓存,getEarlyBeanReference(beanName, mbd, bean)
singletonObject = singletonFactory.getObject();
// 放入2级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
而只有一个地方该参数是true:
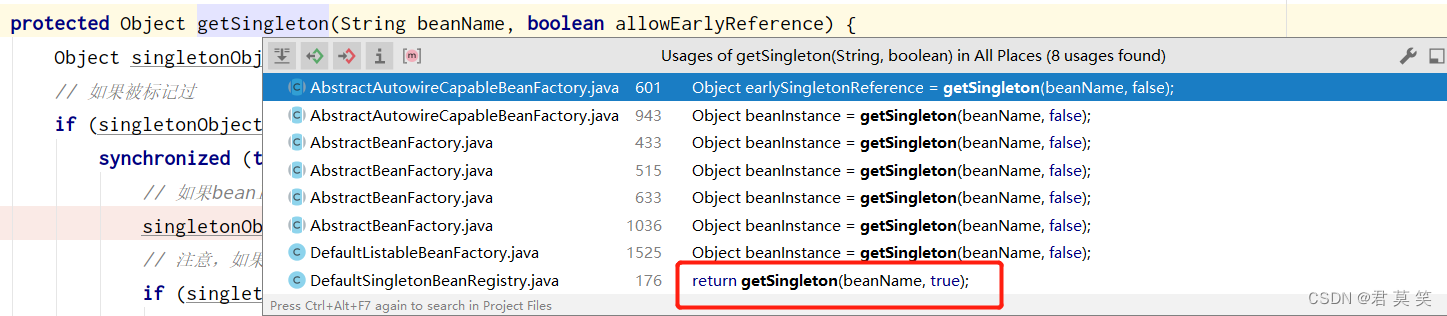
其实这个调用的地方,再往上翻就回到了本小节最开头提到的地方(循环终止条件):
所以这就说明了,当递归创建bean的时候,如果发现成环了,那么就开始调用第三级缓存。
所以并不是所有的bean都会用到第3级缓存,甚至只是少数bean才会用到。
那么为什么我要强调第3级缓存被调用的地方呢?
下面慢慢分析:
详解3级缓存
因为很多人理解上存在误区,觉得每个bean在创建的时候都要依赖第3级缓存,其实不是的,只有某条引用链上的尾结点(也就是头结点,循环引用嘛,最终会形成一个环形的依赖)才会通过第3级缓存创建bean,并在创建完后迅速移动到第2级缓存。
具体地说:
第3级缓存:保存了创建bean的方法。可以简单理解为:
如果待创建的bean:
(1)没有被aop代理的情况下,singletonFactory.getObject()调用map中的方法,返回原对象
(2)存在被aop代理的情况下,singletonFactory.getObject()会生成并返回代理对象。
通过第3级缓存创建出来的对象,直接就会移动到第2级缓存。
直接上图吧,可能会更清晰一些(不考虑aop):
 那么如果考虑aop。就比较复杂了。
那么如果考虑aop。就比较复杂了。
下面分两种情况讨论:
比如A–>B–>C–>A
1.某条引用链尾结点存在aop(A节点有aop代理)
2.引用链中间节点存在aop(B或者C有aop代理)
为什么我要分两种情况呢?
因为这两者创建代理的时机是不一样的,很多资料说2级缓存是用来解决aop的,这种说法不全对。因为:
暂停一下,请翻开spring 5.0.x源码,找到
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
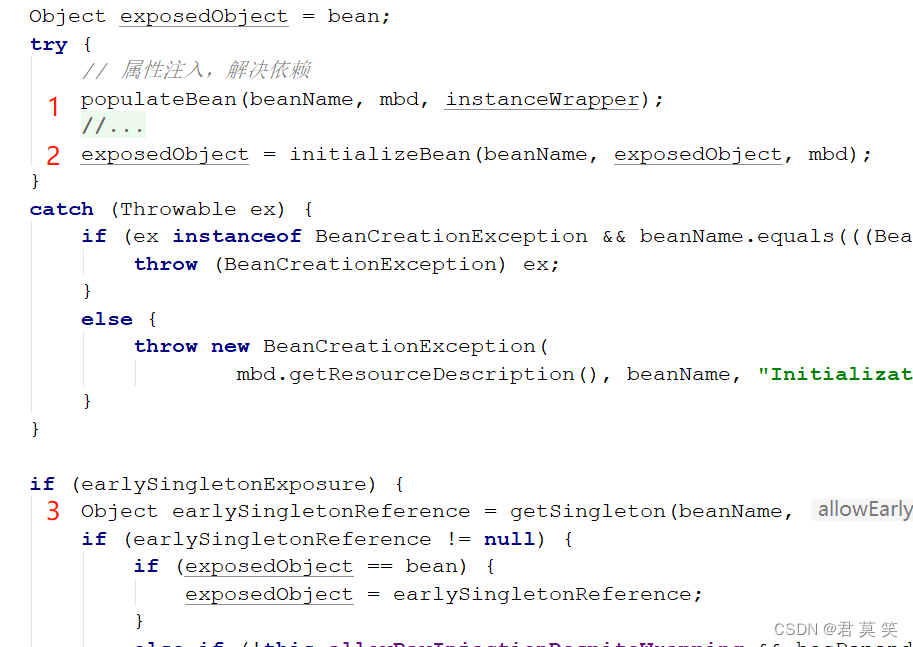
上图的exposedObject=bean,bean就是用构造器造出来的(当然也有别的创建方式,可以点进上面的方法进去看看)半成品对象。
暂停结束
如果是case 1:创建代理的时机就是我们上文讨论的一大篇。也就是用第3级缓存创建,然后转移到第2级缓存。这个时机其实是在populate(beanB)中就完成的。
但是还有问题,exposedObject和2级缓存中的对象,不是一个对象呀!是的,所以这种情况下,会执行上图中的第3步,从2级缓存拿beanA的代理对象,并替换原来创建的beanA。
如果是case 2:假设是beanB吧,创建代理的时机,是在上图中的第2步。这个第2步里面会执行很多aware以及BeanPost方法。
这个其实很简单,因为至始至终,代理beanB都没有用到2、3级缓存。
所以解答一个喜欢被问的面试题:
spring可不可以只用2级缓存(只用2个map)?
答:我觉得可以,首先分两种情况:
case2不必多说,当然可以,这缓存我们都没用过,简直是摆设。
在case1的情况下,我们是不是可以在创建代理对象的时候,也就是调用第3级缓存后,直接丢到第1级缓存去呢?















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









