







前言
开始机器学习之旅 之前我们需要具备的基础~~~Numpy、Jupyter、Matplotlib 基础
然后看一个机器学习的一个入门和经典的知识点,鸢尾花分类,我们通过这个小例子入手,来了解一下什么是机器学习。
python的scikit-learn模块已经将鸢尾花的数据进行内置,所以只需要调用函数进行读取和训练即可,无需准备数据。
加油!!!
专有名词
- 机器学习 (machine learning)
- 预测分析 (predictive analytics)
- 统计学习 (statistical learning)
- 监督学习 (supervised learning)
- 无监督学习 (unsupervised learning)
- 样本 (sample)
- 特征 (feature)
- 特征提取 (feature extraction)
- 分类 (classification)
- 类别 (class)
- 标签 (label)
分类(classification)
散点图(Scatter Plot)
散点图矩阵(Pair Plot)
训练数据(training data)
训练集(training set)
留出集(hold-out set)
Jupyter notebook
其实这个很好使用 就是python如何用这里面就可以如何用,而且可以加上写博客有一样记录,加上一些可视化,可以在运行的时候记录笔记
博主的一些想法
我们在进行学习machine learning的时候必不可少的要用到jupyter
为什么要用这个玩意呢 因为他可以在网页中运行python以及进行markdown的编写就和csdn写博客一样进行记录
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
我们这里建议anaconda的环境进行机器学习,第一个是他自带了jupyter,第二个是可以使用他的虚拟环境配合上pycharm很是方便
我们这里简单过一下这个的基本用法以及 一些魔法命令
基础用法:
可以点击help中的keyboard shortcuts进行查看

我们来看下魔法命令
%run命令
%run 可以引入进来 编写的py模块
%run model/main.py
同时,我们也可以用 import 导入文件夹中的模块
%timeit
%timeit L = [i**2 for i in range(1000)]
是一个测试时间的魔法命令

那么我们想测试一段话呢
我们就需要使用%%timeit
来度量单元格内整体运行的时间 这个叫区域运行符
%time的方式也可以进行计时
%time可以测量一行代码执行的时间
%timeit可以测量一行代码多次执行的时间
%lsmagic
我们如果想查看其他的魔法命令就可以使用 %lsmagic

可以自己去测试发现一些更好玩的魔法命令
例如
%matplotlib inline这一句是IPython的魔法函数,可以在IPython编译器里直接使用,作用是内嵌画图,省略掉plt.show()这一步,直接显示图像。
Numpy基础创建
我们首先来看下为什么使用numpy中的array???
我们python中自带的有list可以存储数据
L = [i for i in range(10)]
print(L)
L[5]="Machine Learning"
print(L)
但是list效率相对较低,python中也可以限定存储一种类型的数组 import array
import array
arr = array.array('i',[i for i in range(10)])
print(arr[5])
这时就无法进行修改赋值,相对效率较高,但也有缺点,array只是把存储在其中的数据当做数组来看,二维数组,但是无论基于数组还是二维数组,他没法把这些数据当作向量或者矩阵,也无法配置向量和矩阵的相对的计算
所以我们在机器学习 中 array不方便
因此 numpy中的array孕育而生
因此 numpy中的array孕育而生
因此 numpy中的array孕育而生
import numpy as np
nparr = np.array([i for i in range(10)])
print(nparr)
numpy的array也封装了一些方法 比如查看类型 nparr.dtype
其他创建numpy.array的方法
全零矩阵
np.zeros(10)
np.zeros(10).dtype
np.zeros((3,5))
np.zeros(shape=(3,5), dtype = int)
全1矩阵
np.ones(10)
全定义的矩阵
np.full((shape=(3,5),fill_value=666)
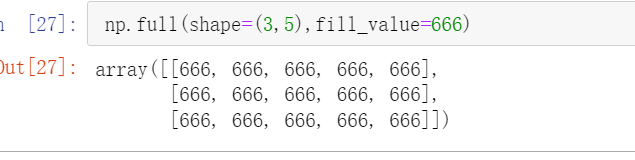 np.full((fill_value=666.0,shape=(3,5))
np.full((fill_value=666.0,shape=(3,5))
普通创建就是int型 先传666.0就是浮点型
arrange是连续数组 等步长的数组
a = np.arange(0,5,1)

linspace =np.linspace(0,20,11)也是用来创建连续数组但意思是在0-20之间等长的截出11个点
d= np.linspace(0,2,10)

Random
随机生成一个数
np.random.randint(0,10)
np.random.randint(0,10,10) //随机生成十个数但都是闭区间可以用下面这个进行检测
np.random.randint(0,1,10)

np.random.randint(4,8,size=(3,5))
np.random.seed(666)//随机种子是伪随机数
np.random.seed(666)
np.random.randint(4,8,size=(3,5))
//这样之后生成的一直是固定的
np.random.random()//生成浮点数

符合正态分布的浮点数就需要
np.random.normal()
//生成均值为0方差为1的浮点数
np.random.normal(10,100)
np.random.normal(10,100,(3,5))
//查具体的函数
np.random.normal?

Numpy.array的基础操作
转换数组为二维数组 reshape
X = np.arange(15).reshape(3,5)
X
output为:array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
基本属性:
x.size 查看几个元素
x.ndim 查看是几维度的数组
X.shape 查看几个元素的元组

数据访问:
x[-1] 访问单数组
x[1,1]访问多维数组
单数组的切片
x[:-1]
多维数组的切片
X[:2,:3]
在numpy中的特点
如果我们创建一个多维数组
X = np.arange(15).reshape(3,5)
然后用切片的方法进行给一个赋值例如
SubX=X[:2,:3]
SubX=[0,0]=100
然后我们查看SubX和X的值 发现 X的值也进行了改变
因为对于numpy来说讲究效率
对于子矩阵是进行引用的方式
//copy之后就得到了副本就和原矩阵脱离了关系
SubX=X[:2,:3].copy()
Reshape:
我们的数组中的元素不需要变,需要对维度进行改变,就需要了reshape的方法
A=x.reshape(2,5)
B= x.reshape(1,10)
这里两个注意点:
1.reshap后的维度和之前的维度是不同的
2.reshape(1,10)的意思是他现在有两个维度 不过只有一个维度有10个元素

我们只想要每行一个元素该怎么办??或者说对行数进行控制
B= x.reshape(10,-1)
x.reshape(-1,10)
x.reshape(2,-1)
x.reshape(3,-1)//这个是报错的 因为10不能被三整除的
填-1的时候会自动计算有几个元素或者几行
使用numpy的数组可以方便的构建矩阵也可以进行数据的转换
数组的合并和分割
合并
np.concatenate函数可以进行合并,也可以自己给自己进行拼接
也可以设置axis参数 为轴 拼接
np.concatenate([x,y,z])
np.concatenate([a,a],axis=1)//按照列的方向进行拼接
如果维度不同可以手动设置维度reshape
也可以用vstack函数竖直方向自动叠加
hstack可以进行水平方向堆叠
但是如果是非法的矩阵 (三维和一维的向量 竖直可以 水平不行的)
np.vstack([A,z])
np.hstack([A,z])
分割
使用split进行分割 第一个是分割 1-3 第二个是3-7 第三个是 7:进行切割
x=np.arange(10)
x1,x2,x3 = np.split(x,[3,7])
//两段
x1,x2= np.split(x,[3])
二维数组也是一样的
可以用np.hsplit 也可以用 np.vsplit进行上下的分割左右的分割
也可以用x1,x2= np.split(x,[3]) 进行二维的维度的分割
x1,x2= np.split(x,[3],axsi=1) 为轴分割 效果是一样的
有什么用呢?我们来看下
如果有个数据我们想取出很多维度的最后一个元素为新数组,就可以使用这样的方法
X,y = np.hsplit(data,[-1])

再加上y[:,0]抽成向量
Numpy.array运算
a=(0,1,2)
a*2(0,2,4)
n=10
L=[i for i in range(n)]
2*L
正常运算的话得到的却是
output:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
两个数组的拼接
我们也可以用for循环进行改写
for e in L:
A.append(2*e)
但是如果运行的多了就会很占用
我们使用numpy的数组 会大大的快于python

更厉害的是他直接支持python不支持的操作
可以直接达到这个效果
n=10
L= np.arange(n)

在numpy中把数据看成向量或者矩阵的方式叫universal functions
可以直接把数组进行正常是数据运算!!!!
这里不多进行举例了 就是可以进行线性代数中的矩阵运算 很强大
Matplotlib
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
我们在机器学习的时候需要用到 所以也简单学习下
import matplotlib as mpl
import matplotlib.pyplot as plt
生成个数组
import numpy as np
x = np.linspace(0,10,100)
y = np.sin(x)
绘制一下x,y
plt.plot(x,y)

plt.plot(x,siny)
plt.plot(x,cosy)
也可以画两个函数
//也可以改变颜色和线条
plt.plot(x,siny)
plt.plot(x,cosy,color='red',linestyle='--')
//xlim 改变x,y轴的范围的方法
plt.plot(x,siny)
plt.plot(x,cosy,color='red',linestyle='--')
plt.xlim(-5,15)
plt.ylim(0,1.5)
当然还有另一种方法x,y都可以调节 就是 axis
plt.axis([-1,11,-2,2])

前两个是x的左右范围 后两个是y的左右范围
我们知道了x y的范围但不知道他的意义,我们可以通过plt.xlabel
plt.plot(x,siny)
plt.plot(x,cosy,color='red',linestyle='--')
plt.xlabel("x axis")
plt.ylabel("y value")

我们进一步加上 x和y对应的颜色曲线 使用到plot中的label参数 再加上 plt.legent就搞定了
plt.plot(x,siny,label="sin(x)")
plt.plot(x,cosy,color='red',linestyle='--',label="cos(x)")
plt.xlabel("x axis")
plt.ylabel("y value")
plt.legend()
plt.title("welcome to the machine learning")

取标题的画 我们就需要plt.title(“welcome to the machine learning”)
Scatter plot散点图
通常
绘制二维的时候特征使用散点图
plt.scatter(x,siny)
x=np.random.normal(0,1,100)
y=np.random.normal(0,1,100)
plt.scatter(x,y,alpha=0.5)
alpha 是透明度 alpha=1是正常 0是全透明

数据加载和探索
我们进入机器学习的大门!!!
导入下真实的数据进行探索 正式进入sklearn的大门
一位科学家对鸢尾花产生了浓厚的兴趣,于是他收集了一些花的数据:花瓣的长度和宽度,花萼的长度和宽度。 他还有一些鸢尾花的测量数据,这些花已经被分类为:setosa,versicolor,virginica三个品种。我们假设他只会在野外遇到这三种花。
我们要根据花的数据特征对花的种类进行分类 一个三分类的问题
先引入数据 在sklearn中自带的有,由于太过经典,这个案例也被引入了我们的scikit-learn的datasets模块中。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
//打印数据集的内容
print(iris.DESCR)
iris = datasets.load_iris()
datasets.load_iris()相当于一个字典 保存了一些库中自带的数据

就是导入的sklearn的数据中 有一些关键字 keys
我们看到有
desecr详细的描述
data数据的信息 也是对应的x的数据
target花的类型 也就是对应的 y
featurename数据中的四列表示的什么意思 feature_name out如下花瓣的长度宽度 花萼的长度宽度
[‘sepal length (cm)’,
‘sepal width (cm)’,
‘petal length (cm)’,
‘petal width (cm)’]
//特征
iris.data #四个特征
iris.data.shape
iris.feature_names #这四列代表什么意思
iris.target #target的属性 是一个一位数组 对应的这150个样本对应的鸢尾花的类型
iris.target_names

我们来绘图看一下
X = iris.data[:,:2]
X.shape
plt.scatter(X[:,0],X[:,1])
//不同特征不同颜色
y=iris.target
plt.scatter(X[y==0,0],X[y==0,1],color="red")
plt.scatter(X[y==1,0],X[y==1,1],color="blue")
plt.scatter(X[y==2,0],X[y==2,1],color="green")
//不同样式
plt.scatter(X[y==0,0],X[y==0,1],color="red",marker="o")
plt.scatter(X[y==1,0],X[y==1,1],color="blue",marker="x")
plt.scatter(X[y==2,0],X[y==2,1],color="green",marker="+")

以上只是选择了两个维度来看 可以进行换一个维度进行查看
X = iris.data[:,2:]
plt.scatter(X[y==0,0],X[y==0,1],color="red",marker="o")
plt.scatter(X[y==1,0],X[y==1,1],color="blue",marker="x")
plt.scatter(X[y==2,0],X[y==2,1],color="green",marker="+")

接下来就要开始分数据集进行预测了~~~ 本章就到这里吧 内容有点长 我们下一篇博客继续看!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









