







 Apriori算法是关联分析中的经典算法,通过先验原理减少计算复杂度。它通过逐层生成频繁项集并剪枝,降低数据扫描次数。候选的产生与剪枝策略进一步优化了效率,如Fk-1×F1方法和Fk-1×Fk-1方法。支持度计数的优化使用了Hash树,降低了时间复杂度。
Apriori算法是关联分析中的经典算法,通过先验原理减少计算复杂度。它通过逐层生成频繁项集并剪枝,降低数据扫描次数。候选的产生与剪枝策略进一步优化了效率,如Fk-1×F1方法和Fk-1×Fk-1方法。支持度计数的优化使用了Hash树,降低了时间复杂度。
频繁项集的产生
格结构(lattice structure)常常用来表示所有可能的项集。
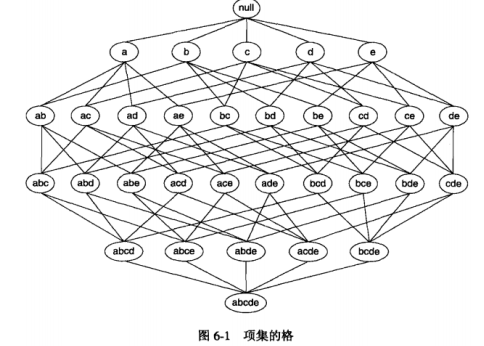
发现频繁项集的一个原始方法是确定格结构中每个候选项集的支持度。但是工作量比较大。另外有几种方法可以降低产生频繁项集的计算复杂度。
1. 减少候选项集的数目。如先验(apriori)原理,是一种不用计算支持度而删除某些候选项集的方法。
2. 减少比较次数。利用更高级得到数据结构或者存储候选项集或者压缩数据集来减少比较次数。
先验原理(Apriori)
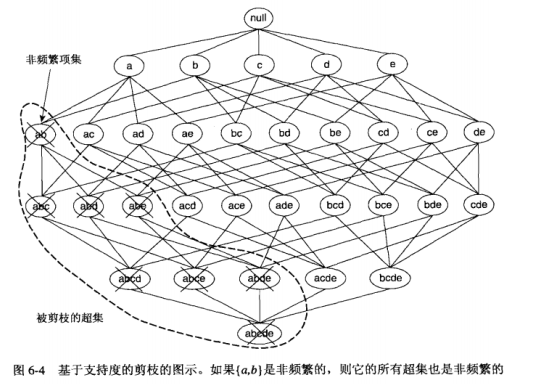
使用支持度对候选项集进行剪枝。
先验原理:如果一个项集是频繁的,则它的所有子集也一定是频繁的。
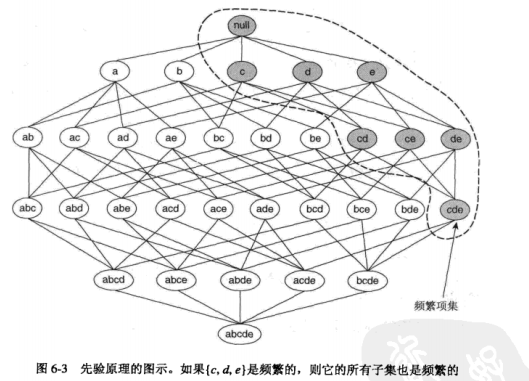
相反,如果一个项集是非频繁的,则它所有的超集都是非频繁的,这种基于支持度度量修剪指数搜索空间的策略称为基于支持度的剪枝,依赖于一个性质,即一个项集的支持度决不会超过它的自己的支持度,这个性质称为反之尺度度量的反单调性(anti-monotone)。
Apriori算法的频繁项集产生
Apriori算法是第一个关联规则挖掘算法,它开创性地使用基于支持度的剪枝技术,系统地控制候选项集指数增长。
算法:
1. 初始通过单遍扫描数据集,确定每个项的支持度,得到所有频繁1-项集的集合F1.
2. 迭代地使用上一步得到的k-1项集,产生新的候选k项集。
3. 为了对候选项的支持度技术,算法需要再次扫描一遍数据集。
4. 计算候选项的支持度,山区支持度小于minsup的左右后选集。
5. 当没有新的频繁项集产生,算法结束。

Apriori算法的频繁项集产生的部分有两个重要的特点:(1)逐层算法,从频繁1-项集到最长的项集,每次遍历项集格中的一层。(2)它使用产生-测试(generate-and-test)策略来发现频繁项集,每次迭代后的候选项集都由上一次迭代发现的频繁项集产生。算法总迭代次数为 kmax+1 ,其中 kmax 为频繁项集最大长度。
候选的产生与剪枝
剪枝:考虑候选k项集 X=i1,i2,i3…… ,如果X的一个真子集非频繁,则X将会被剪枝。对于每一个候选k-项集,确保 X−in
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









