







 本文详细介绍了关联规则挖掘中的频繁项集、A-Priori算法,以及面对大规模数据集时的处理策略,如PCY算法、多阶段算法和多哈希算法。此外,还探讨了有限扫描算法,包括随机化算法、SON算法和Toivonen算法,以及如何应对数据流中的频繁项计数挑战。这些方法旨在提高效率,减少内存需求,确保在处理海量数据时能准确挖掘出有价值的信息。
本文详细介绍了关联规则挖掘中的频繁项集、A-Priori算法,以及面对大规模数据集时的处理策略,如PCY算法、多阶段算法和多哈希算法。此外,还探讨了有限扫描算法,包括随机化算法、SON算法和Toivonen算法,以及如何应对数据流中的频繁项计数挑战。这些方法旨在提高效率,减少内存需求,确保在处理海量数据时能准确挖掘出有价值的信息。
文章目录
1 定义
1.1 频繁项集
- 支持度是项出现的次数
- 支持度是频繁项集的阈值
假定有个支持度闾值(support threshold) s 。如果I是一个项集, I的支持度(support) 是指包含I (即I是购物篮中项集的子集)的购物篮数目。如果I的支持度不小千S,则称I是频繁项集(frequent itemset)。
1.2 关联规则
关联规则往往采用 if-then 形式的规则集合来表示 I → j。意义是,如果 I 中多有项出现在某个购物篮的话,那么 j “有可能” 也出现在这一购物篮。
定义置信度(confidence)来给出可能的概率大小。
2 A-Priori 算法
根据项集的单调性对项集进行剪枝
- 如果项集I是频繁的,那么其所有的子集都是频繁的。
- 一个集合的子集不是频繁项集,那么该集合也不可能是频繁项集。
那么可以列出最大频繁项集,并且最大频繁项集的所有子集都是频繁的。

2.1 例题
- Apriori:这是一个不断找,然后筛选的过程,然后找到最大频繁项集

第一次扫描,k=1
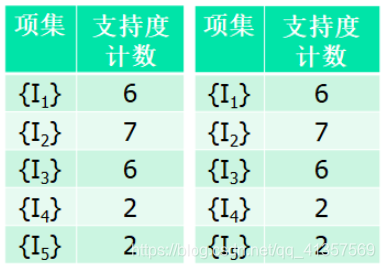
第二次扫描,k=2
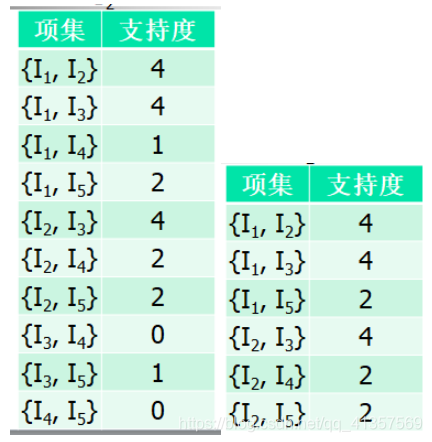
第三次扫描,k=3
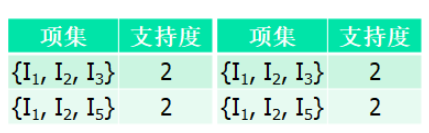
当 k=4 时,没有找到频繁项集,扫描结束
3 更大数据集在内存中的处理
3.1 PCY 算法
- 第一遍扫描结束时,每个桶中都有一个计数值,记录的是所有哈希到该桶中的项对的数目之和。如果某个桶中的计数值不低于支持度阈值,那么该桶称为频繁桶。
候选项对 {i, j}满足:
(1)i 和 j 都是频繁项
(2){i, j} 哈希到一个频繁桶
- 在 PCY 的两次扫描之间,哈希表被概括表示成一个位图 (bitmap),其中每一位表示一个桶。位为1表示对应的桶是频繁的,而为0就表示不频繁。
3.2 多阶段算法
多阶段算法(Multistage Algorithm) 通过使用多个连续的哈希表来进一步降低 PCY 算法中的候选对数目,当然其付出的代价是需要两次以上的扫描过程来发现频繁项组成的对
步骤:
- 多阶段算法的第一遍扫描和PCY的一样。第一遍扫描之后,频繁桶会被识别出来并概括为一个位图,这和PCY算法的情况也一样。
- 但是多阶段算法的第二遍扫描并不对候选对计数。取而代之的是利用可用内存基于另一个哈希函数建立另一张哈希表。在第二遍扫描中,我们将某些项对哈希到第二张哈希表的桶中第二遍扫描之后,第二张哈希表也会概括成一个位图存在内存中。
多阶段算法和PCY 的本质区别:
(1) i 和 j 都是频繁项;
(2) {i, j} 哈希到第一张哈希表的某个频繁桶中;
(3) {i, j} 哈希到第二张哈希表的某个频繁桶中。
3.3 多哈希算法
多哈希算法在第一次扫描中同时在内存使用两个哈希函数和两张独立的哈希表。
4 有限扫描算法
4.1 随机化算法
前提: 当数据量非常大,整个购物篮数据无法放入内存,这时,进行统计会有一定困难
解决方法:对购物篮进行随机抽样,只要样本数据足够大,还是能够提取出逼近真实情况的频繁项集的。由于是抽样,涉及概率p,所以频繁项支持度的阈值s也需要降低,但是由于概率的乘法定理,抽样的频繁项集肯定是小于实际的数目,所以,需要降低阈值,可以将新的阈值设置的更小点,如0.9ps。
抽样带来的新问题: 伪正例(非频繁项集被统计成频繁项集)、伪反例(频繁项集没有提取出来)。伪正例可以通过后续的处理,排除掉,但是无法消除伪反例的情况。
4.2 SON 算法
SON 算法能够在两次扫描的代价下去掉所有的伪反例和伪正例。
基本思路:
- 将文件分为多个组块,每个组块占整个文件的比例为p,组块的数量是 1/p。
- 在每个组块中采用简单随机算法
- 以将所有在一个或多个组块上发现的所有频繁项集(支持度 > ps,s 是整体的支持度阈值)进行合并。这些项集为候选(candidate) 项集
为什么能够去掉伪正例和伪反例?
- 如果某个项集在任意组块上都不频繁,那么它在每个组块上的支持度都低千ps 。由于组块的数目是 1/p, 因此我们得出结论:该项集在所有数据集上的支持度将低于(1/p)ps=s。所以,在所有数据集上频繁的项集至少会在一个组块上是频繁的,于是我们可以确认所有真正频繁的项集都在候选项集中,也就是说不存在伪反例。
4.3 Toivonen 算法
Toivonen 步骤
- Toivonen算法首先选择输入数据集中的一个小样本并基于该数据获得候选频繁项集
- 下一步就是要构建反例边界:非频繁集,但去掉任何一个元素就是频繁集。
为完成Toivonen算法,我们要对整个数据集进行一遍扣描,通过扫描对样本数据上的所有频繁项集或反例边界中的项集进行计数。两种可能的结果如下。
(1)反例边界中的所有集合在整个数据集上也都不是频繁的。这种情况下,正确的频繁项集是那些在整个数据集上仍然频繁的样本频繁项集。
(2)反例边界上的某些集合在整个数据集上是频繁的。这时没办法确定,必须在一个新的随机样本数据上重新执行算法。
5. 流中频繁项计数
面临的问题:
(1)数据流可能速率很高,无法存储整个流进行分析
(2)随时间的推移,频繁项集也会发生变化
解决方法:
(1) 抽样技术
定期收集数据流,存为文件后,再分析。分析期间,不再将数据流放入正在分析的文件。不过,可以存储为另一个文件,供下次分析。
(2)窗口的衰减模型
可以将倒数第i个出现的购物篮赋予(1-c)^i 的权值。这样就形成了流中的一个衰减窗口。当某个项集出现在当前购物篮中,并且其所有真子集已经开始计数,那么此时开始对此项集开始计数。这样需要计数的项集的规模就不会太大。由于窗口不断衰减,将所有计数值都乘以(1-c),并去掉计数低于1/2的项集。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









