







 本文详细介绍了如何在Linux环境下编译Spark 1.4.1源码,包括下载源码、安装Maven、Scala和JDK,以及编译过程中的注意事项和常见问题解答,特别提到了使用Maven编译和`make-distribution.sh`脚本来创建可直接运行的tgz包。
本文详细介绍了如何在Linux环境下编译Spark 1.4.1源码,包括下载源码、安装Maven、Scala和JDK,以及编译过程中的注意事项和常见问题解答,特别提到了使用Maven编译和`make-distribution.sh`脚本来创建可直接运行的tgz包。
Spark 编译前准备
1. 下载 Spark1.4.1 源码包,并解压
进入 spark 官网下载:http://spark.apache.org/downloads.html
或者笔者分享的百度云盘:链接:http://pan.baidu.com/s/17I67O 密码:3cwf
笔者解压到
tar -zxvf spark-1.4.1.tgz -C /home/hadoop/softwares/2. 安装 Maven
具体可参考笔者的 Maven 安装
3. 安装 Scala 2.10.4
下载地址:链接:http://pan.baidu.com/s/1sj46kn7 密码:fv4z
安装就是解压,然后配置环境变量,没啥了
export SCALA_HOME=/home/hadoop/softwares/scala-2.10.4
export PATH=${PATH}:$SCALA_HOME/bin在 linux 安装下 Scala 环境,键入 scala -version ,出现如下即可:

4. 安装 Oracle 的 JDK 7
虽然笔者使用 Open-jdk 1.7 编译成功了,但是还是暂时推荐读者使用 Oracle 的 JDK 7。jdk 1.7 下载及安装,具体参考笔者的 JAVA 配置
注意:实际中,笔者没像网上的人那样,直接把 open-jdk 删的不要不要的。我只是将 Oracle 的 jdk 的环境变量添加到原有系统变量 $PATH 的之前(路径搜索从前向后,搜索到就停止啦~),具体如下:
export JAVA_HOME=/home/hadoop/softwares/jdk1.7.0_71
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
Note:本博客采用 Maven 方式进行编译,其他的编译方式可参考该博文《Spark1.0.0 源码编译和部署包生成》:http://blog.csdn.net/u011414200/article/details/49422941
编译
进入 spark 1.4.1 源码目录下,编译之前的目录结构:

然后编译:
mvn -Dhadoop.version=2.5.0-cdh5.3.2 -Pyarn -Phive -Phive-thriftserver -DskipTests clean package但笔者希望将输出结果不仅在屏幕上显示,同时也希望保存到文档中,于是命令为(笔者就用这个):
mvn -Dhadoop.version=2.5.0-cdh5.3.2 -Pyarn -Phive -Phive-thriftserver -DskipTests clean package | tee building.txt题外话:其实好像用 cdh 版本的只要写以下编译语句就可以了(笔者未考证)
mvn -Pyarn -Phive -Phive-thriftserver -DskipTests clean package注意的是 hadoop version 和 scala 的版本设置成对应的版本。
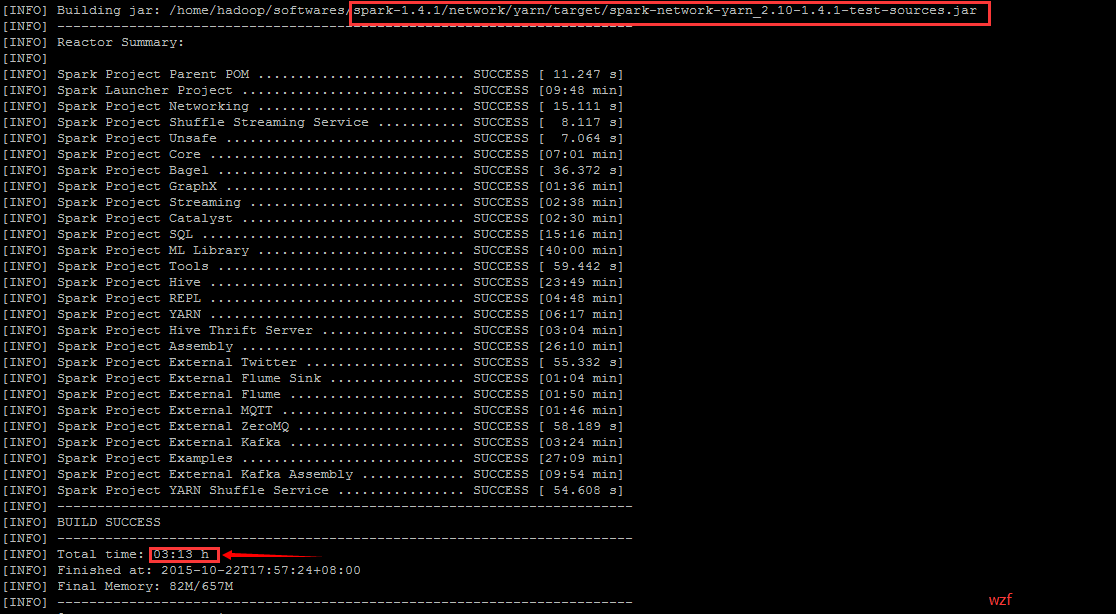
Note:
- Mvn 并不会默认生成 tar 包。你会得到很多 jar 文件 —— 每一个工程下面都有它自己的 jar 包(例如上图中的标注的)
ls /home/hadoop/softwares/spark-1.4.1/network/yarn/target
- 在 assembly/target/scala-2.10 目录下有个 spark-assembly-1.4.1-hadoop2.5.0-cdh5.3.2.jar 文件
ls /home/hadoop/softwares/spark-1.4.1/assembly/target/scala-2.10 
笔者将其拖入 windows 下,用解压工具打开 see 了下:
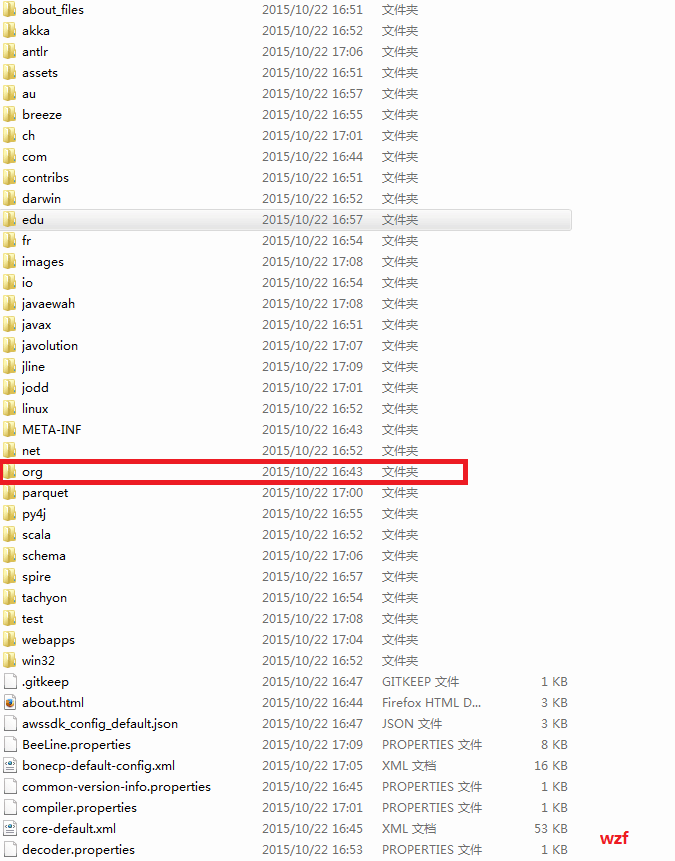
在 org 文件夹下:

该文件夹下的文件:
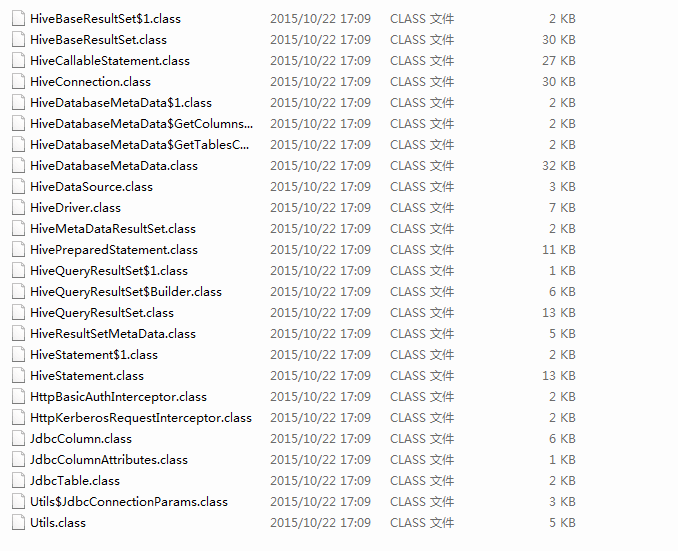
这就说明了编译成功了。
Make 生成二进制 tgz 包(解压可直接运行)
然后在源码目录下面 make-distribution.sh ,可以用来打 二进制bin包:
Note:运行这个命令,笔者瞬间觉得自己SB了,不用 mvn ,好像直接 ./make-distribution 就 OK 了,因为 make 自带 Maven 编译。
./make-distribution.sh --name custom-spark --skip-java-test --tgz -Pyarn -Dhadoop.version=2.5.0-cdh5.3.2 -Dscala-2.10.4 -Phive -Phive-thriftserver上述命令中 “–name custom-spark” 还有待商榷,貌似应该是 “hadoop-version”。
笔者所用命令为:
./make-distribution.sh --name cdh5.3.2 --skip-java-test --tgz -Pyarn -Dhadoop.version=2.5.0-cdh5.3.2 -Dscala-2.10.4 -Phive -Phive-thriftserver | tee building_distribution.txt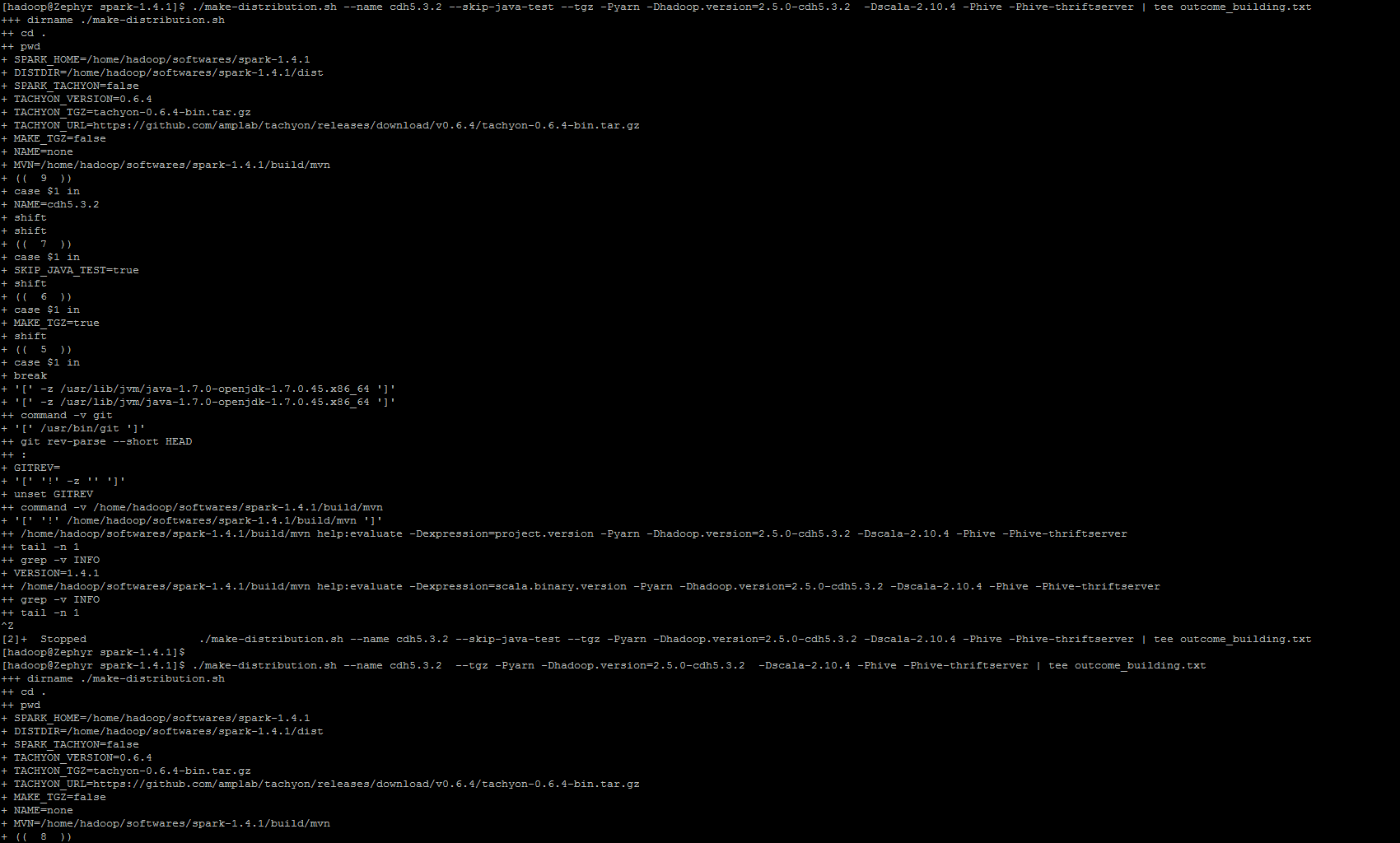
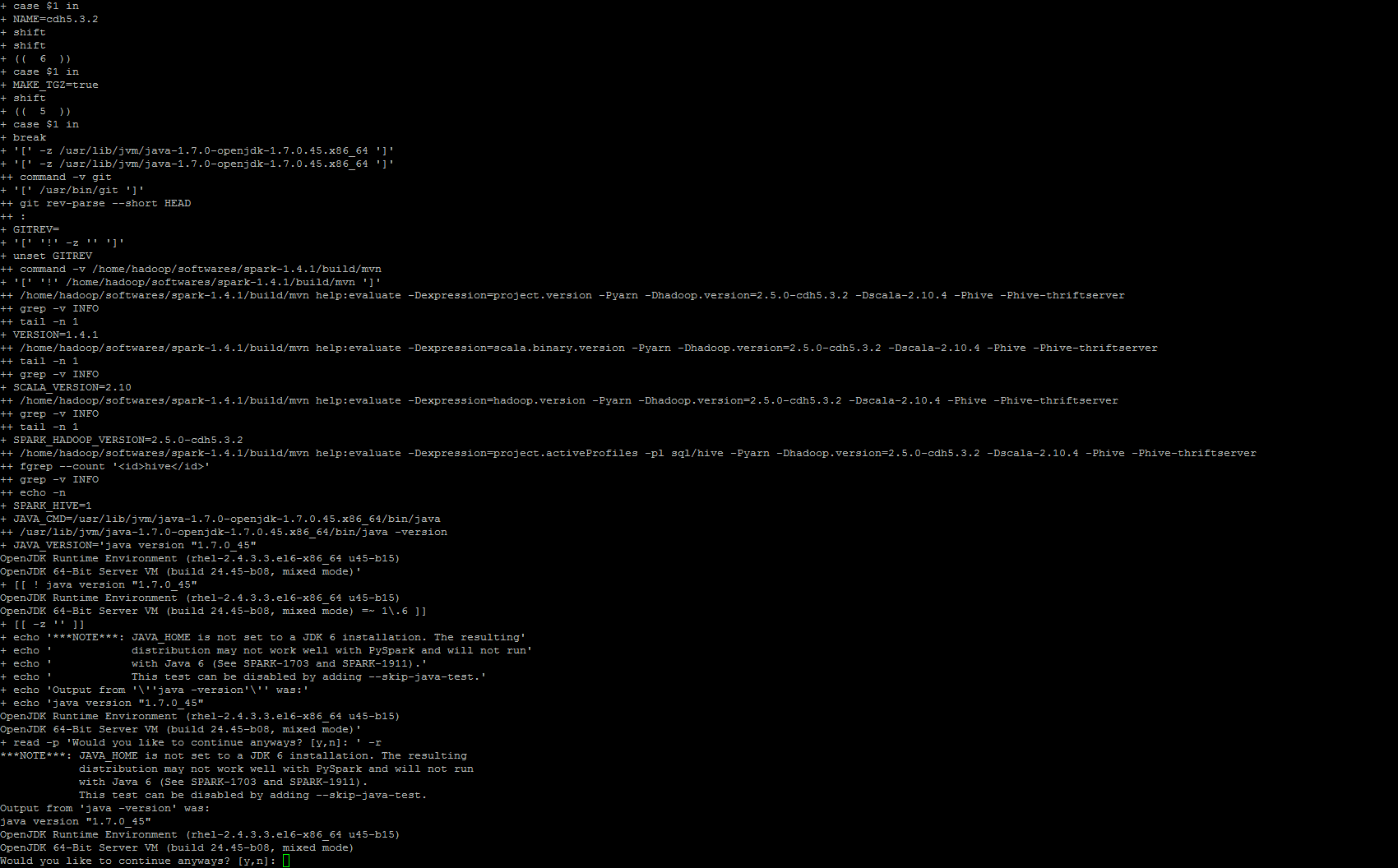
最后,它提示 (Y/N),笔者小心翼翼地选择了 Y,然后就进入漫长的编译阶段…
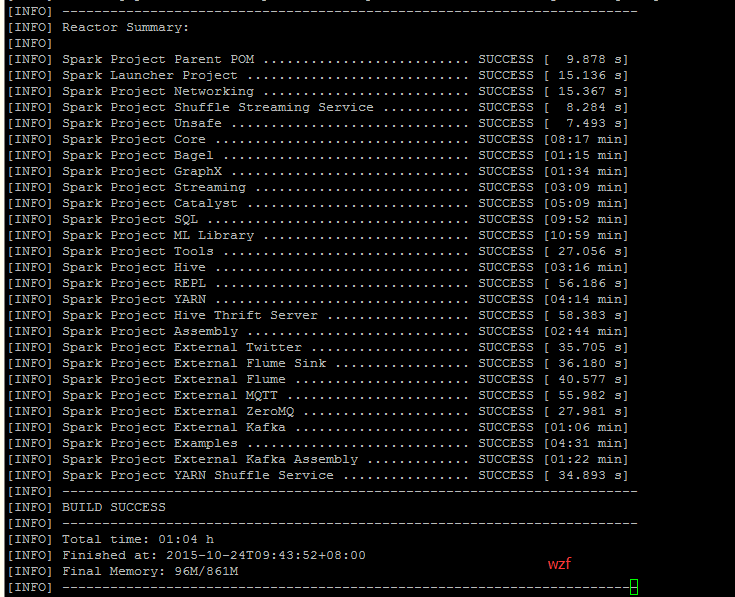
最终经历了种种困难后,终于成功编译了,如下图:
然后在该目录下:
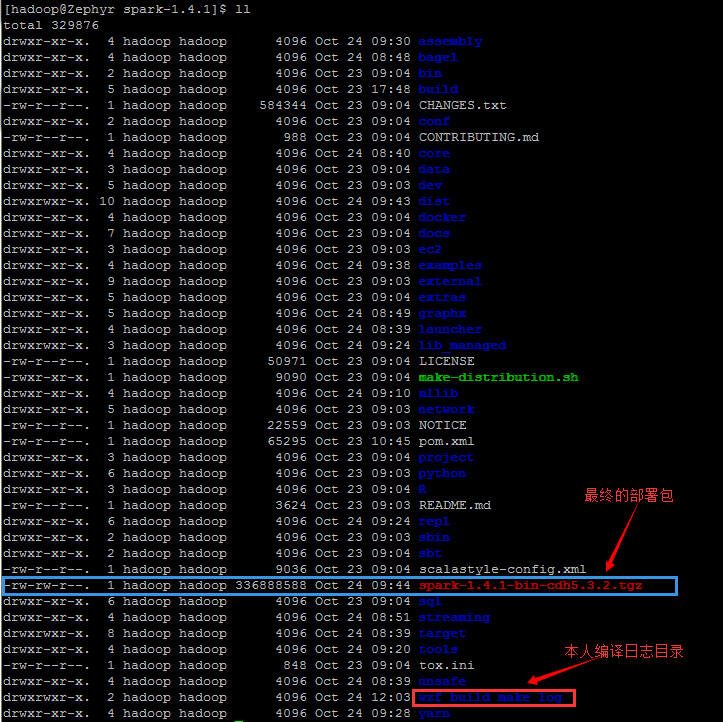
这个部署包 322 M 大小
在该目录下,生成了 spark-1.4.1-bin-cdh5.3.2.tgz 文件,322M 大小(后记:经初步检测,能正常使用),到此,笔者编译就告一段落了。
Q & A
Q1: warning: [options] bootstrap class path not set in conjunction with -source 1.6
原因:
This is not Ant but the JDK’s javac emitting the warning.
If you use Java 7’s javac and -source for anything smaller than 7 javac warns you you should also set the bootstrap classpath to point to an older rt.jar - because this is the only way to ensure the result is usable on an older VM.
https://blogs.oracle.com/darcy/entry/bootclasspath_older_source
This is only a warning, so you could ignore it and even suppress it with
<compilerarg value="-Xlint:-options"/>Alternatively you really install an older JVM and adapt your bootclasspath accordingly (you need to include rt.jar, not the bin folder)
解决办法:忽略不管呗~
Q2:编译中断失败 (compile failed. CompileFailed)
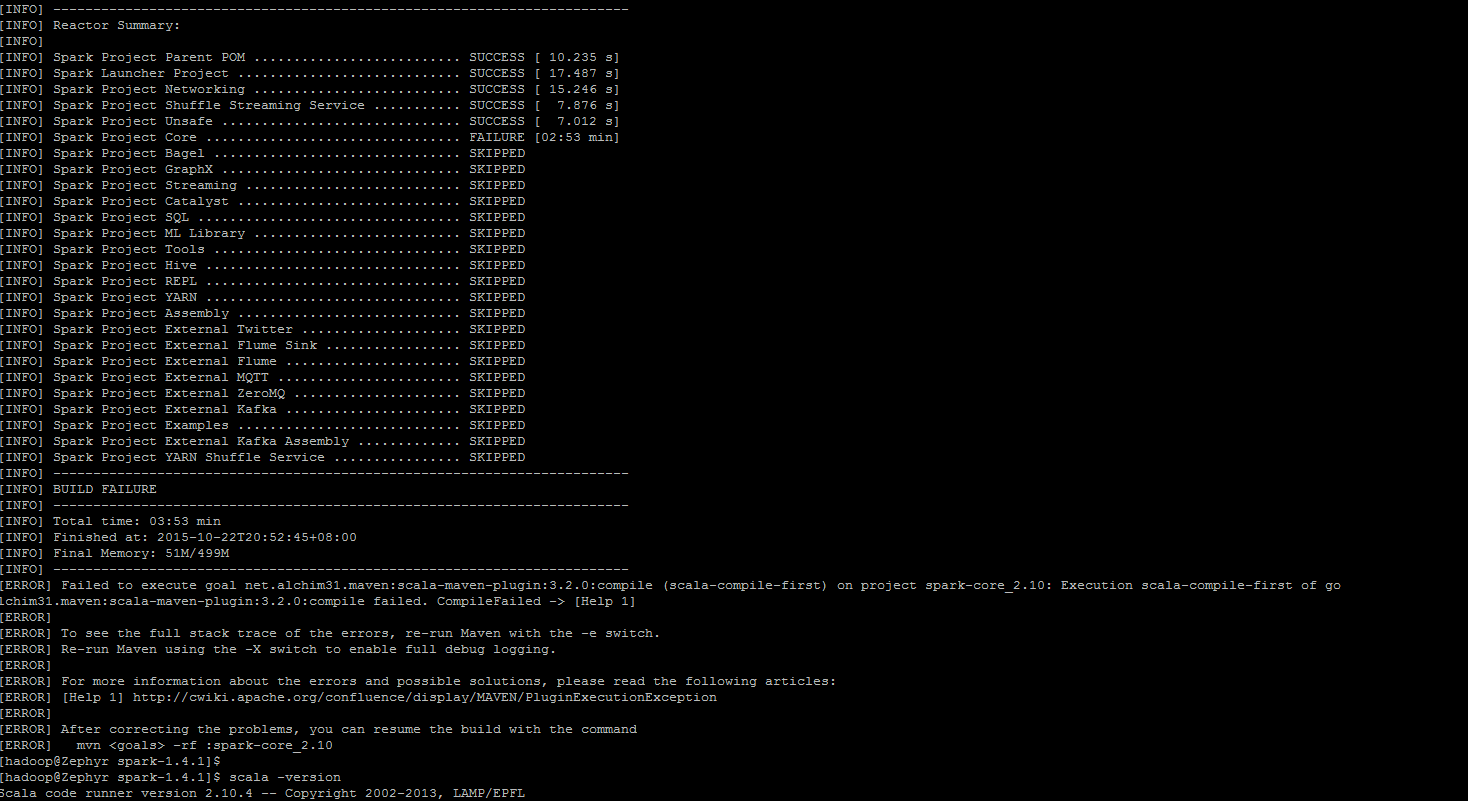
Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project spark-sql_2.10: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile failed. CompileFailed -> [Help 1]
Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:testCompile (scala-test-compile-first) on project spark-sql_2.10: Execution scala-test-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.0:testCompile failed. CompileFailed -> [Help 1]
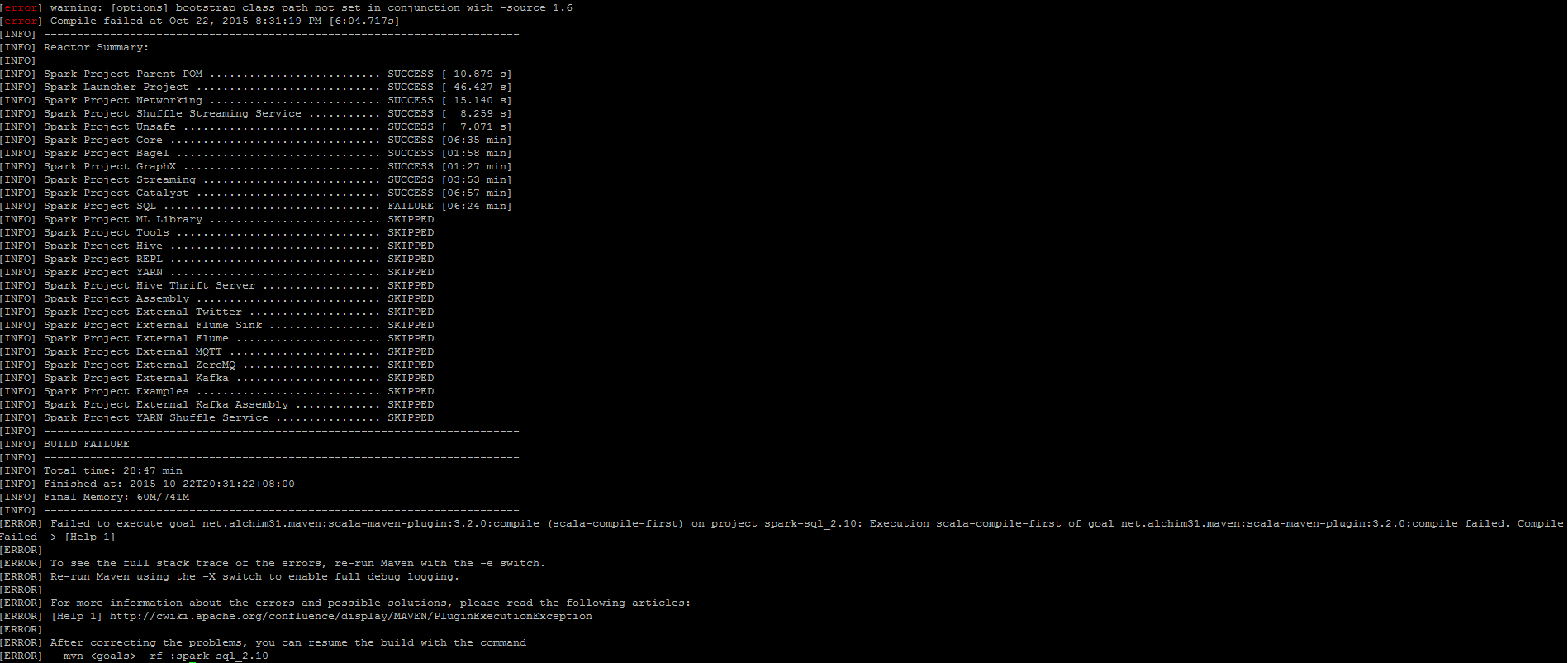
Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project spark-core_2.10: Execution scala-compile-first of golchim31.maven:scala-maven-plugin:3.2.0:compile failed. CompileFailed -> [Help 1]
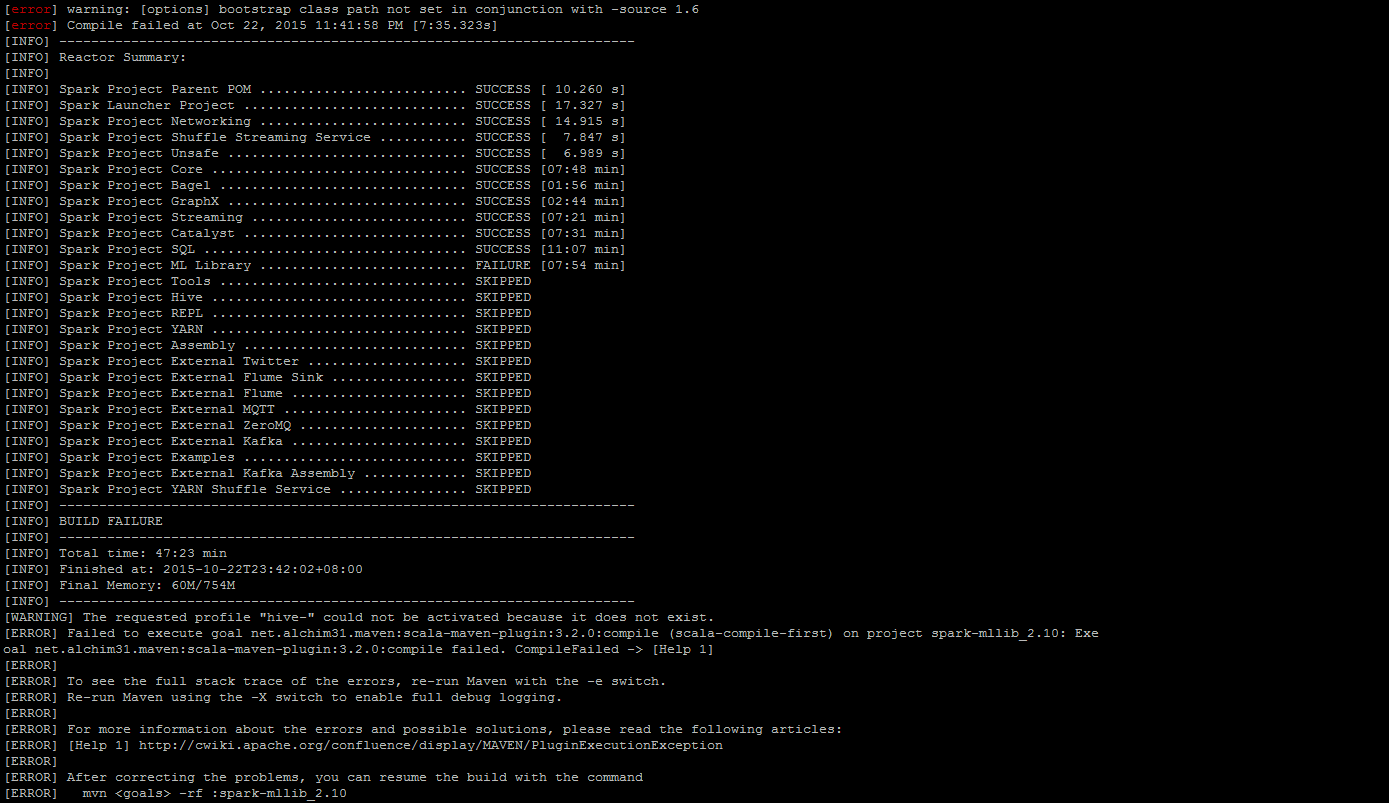
[WARNING] The requested profile “hive-” could not be activated because it does not exist.
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project spark-mllib_2.10: Exeoal net.alchim31.maven:scala-maven-plugin:3.2.0:compile failed. CompileFailed -> [Help 1]
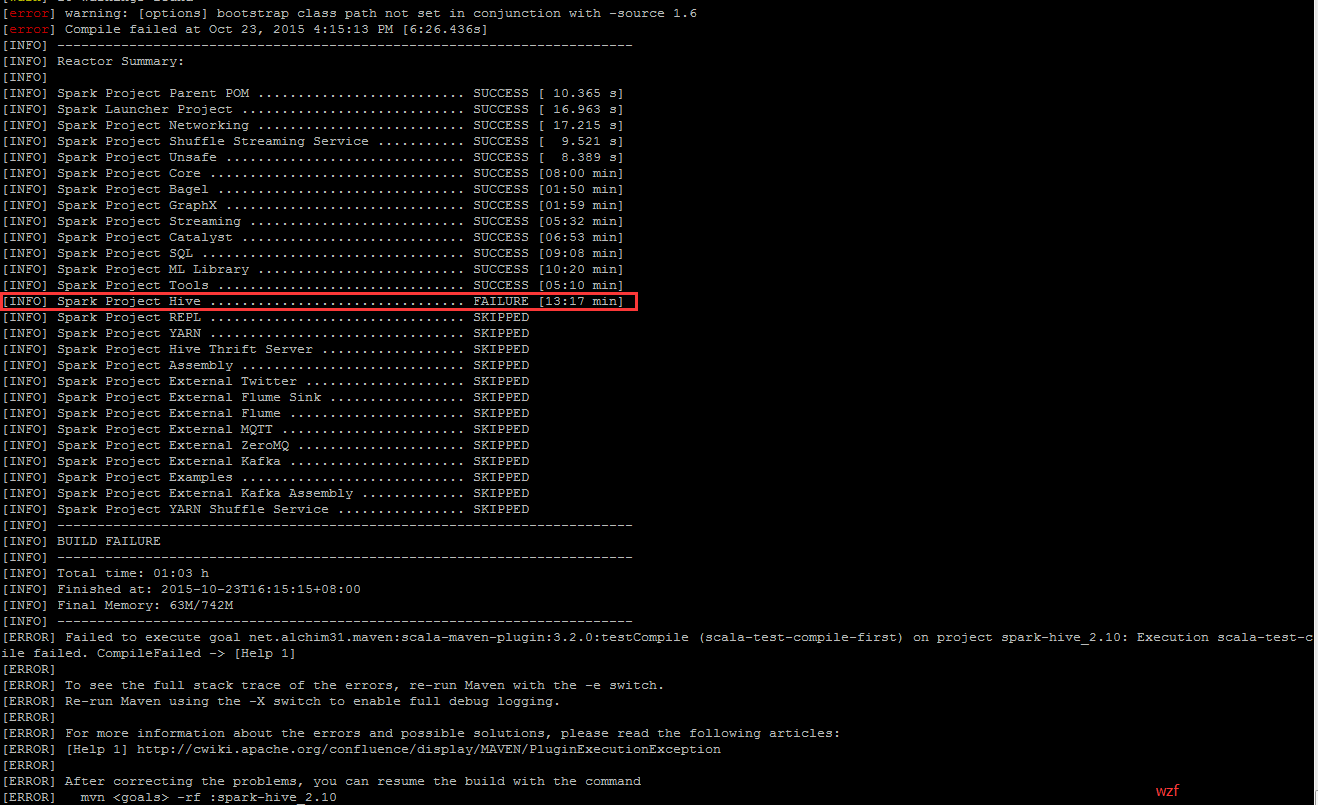
原因:
- 网速问题?
- 时间太长了,超出编译的最大时间
- 编译主机负荷大?
解决办法:
- 删除本地 Maven 仓库,然后多次重新编译
- 要么
mvn <goals> -rf :spark-sql_2.10// 从失败的地方(比如 spark-sql_2.10 )开始编译
./make-distribution.sh --name cdh5.3.2 --skip-java-test --tgz -Pyarn -Dhadoop.version=2.5.0-cdh5.3.2 -Dscala-2.10.4 -Phive -Phive-thriftserver -rf :spark-sql_2.10- 修改spark1.4.1源码下的 pom.xml 文件
<dependency>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
</dependency>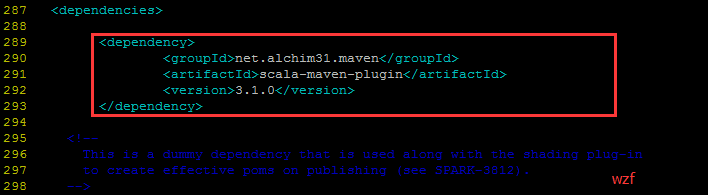
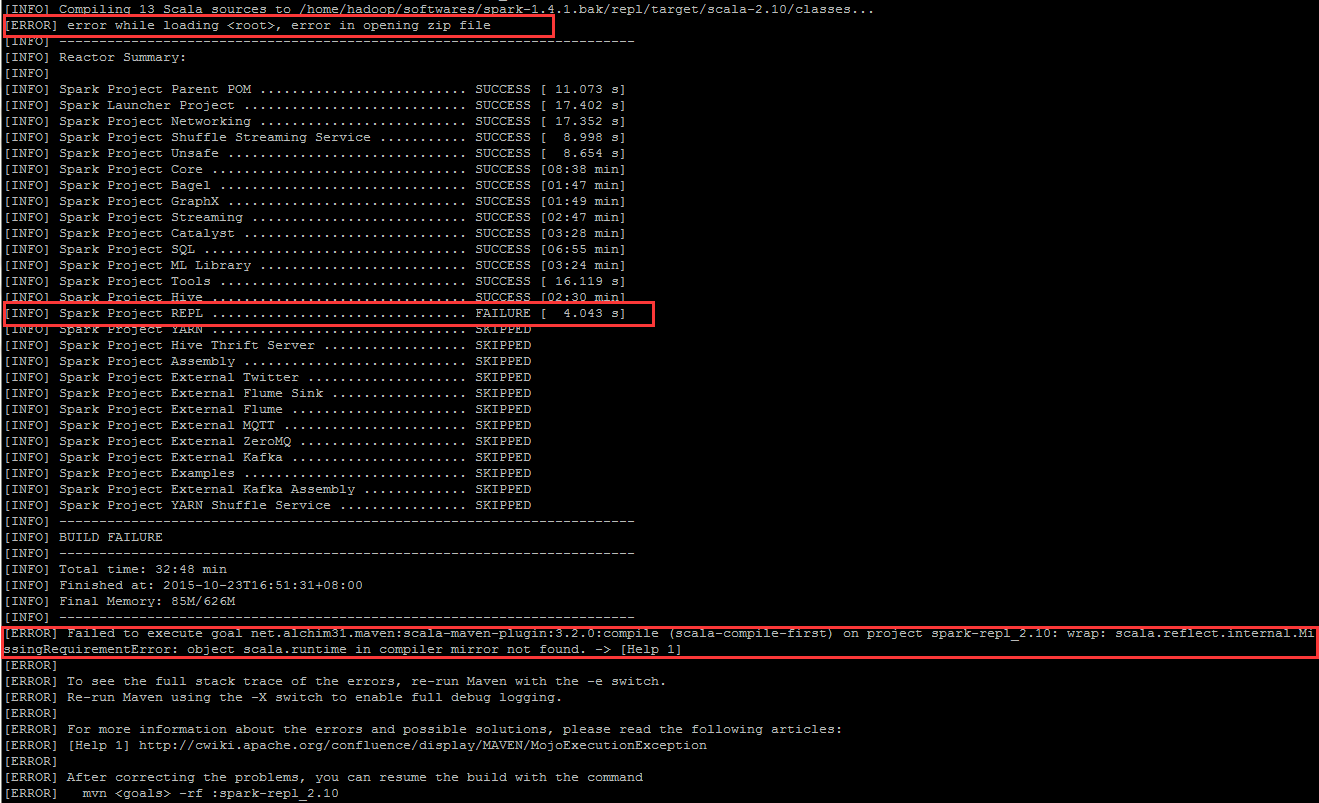
Q3: spark-repl_2.10 的 MissingRequirementError
[ERROR] error while loading , error in opening zip file
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project spark-repl_2.10: wrap: scala.reflect.internal.MissingRequirementError: object scala.runtime in compiler mirror not found. -> [Help 1]
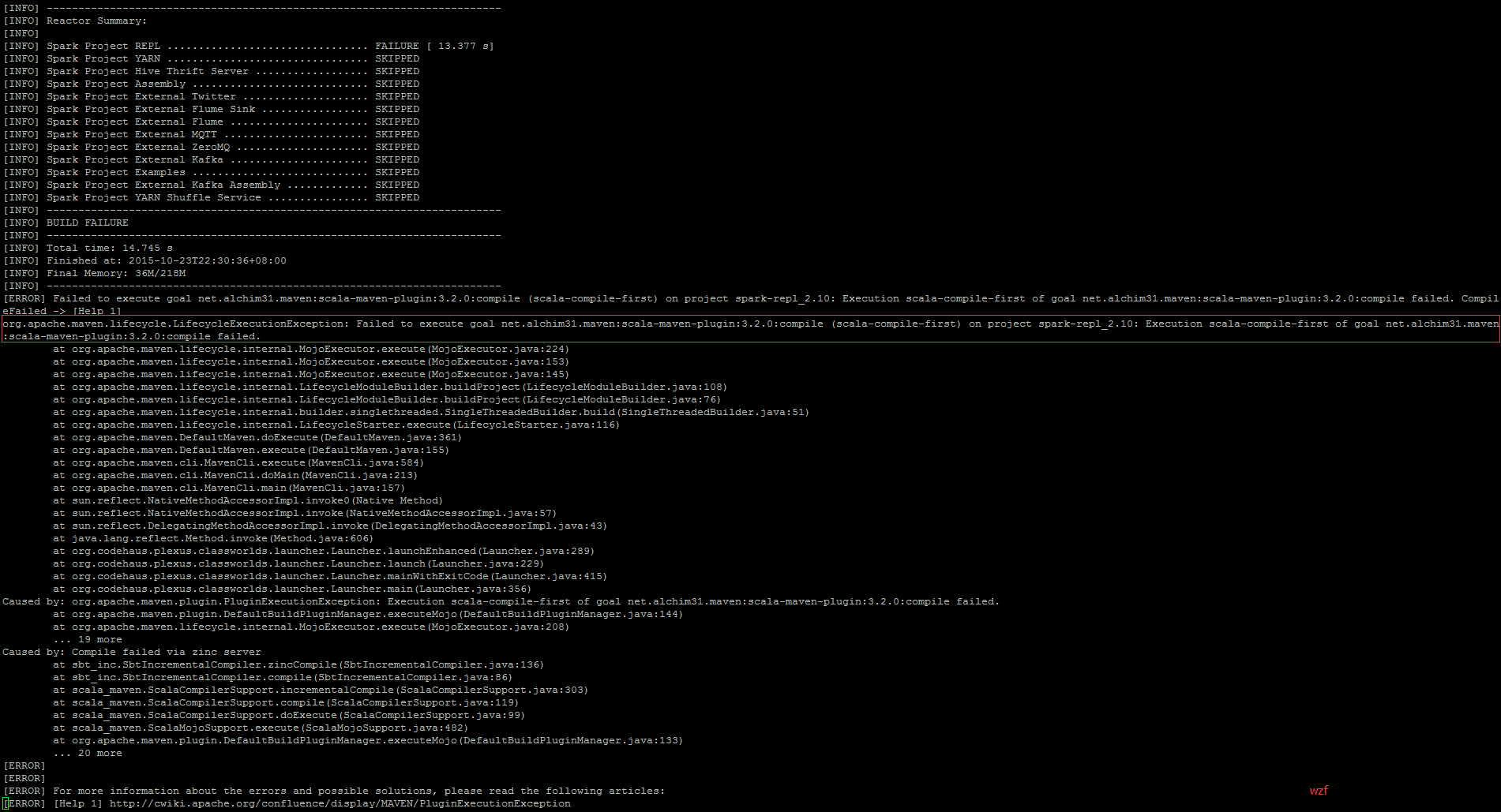
org.apache.maven.lifecycle.LifecycleExecutionException: Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project spark-repl_2.10: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile failed.
Google 到的困难原因:
回答一
This error is actually an error from scalac, not a compile error from the code. It sort of sounds like it has not been able to download scala dependencies. Check or maybe recreate your environment.回答二
This error is very misleading, it actually has nothing to do with scala.runtime or the compiler mirror: this is the error you get when you have a faulty JAR file on your classpath.
Sadly, there is no way from the error (even with -Ydebug) to tell exactly which file. You can run scala with -Ylog-classpath, it will output a lot of classpath stuff, including the exact classpath used (look for “[init] [search path for class files:”). Then I guess you will have to go through them to check if they are valid or not.
I recently tried to improve that (SI-5463), at least to get a clear error message, but couldn’t find a satisfyingly clean way to do this…回答三
I have checked to ensure that in my class path that ALL jars from SCALA_HOME/lib/ are included
As we figured out at #scala, the documentation was missing the fact that one needs to provide the -Dscala.usejavacp=true argument to the JVM command that invokes scalac. After that everything worked fine, and I updated the docs: http://docs.scala-lang.org/overviews/macros/overview.html#debugging_macros.
Q4: 其他潜在的问题
为了防止Spark(1.4.1)与Hadoop(2.5.0)所使用的Protocol Buffers版本不一致会造成不能正确读取HDFS文件, 所以需要对pom.xml进行相应修改。
<!--<protobuf.version>2.4.1</protobuf.version>-->
<protobuf.version>2.5.0</protobuf.version>重要的参考资料
《Spark1.0.0 源码编译和部署包生成》:http://blog.csdn.net/u011414200/article/details/49422941
《spark1.4.0基于yarn的安装心得体会 》:http://blog.csdn.net/xiao_jun_0820/article/details/46561097
目前线上用的是cdh5.3.2中内嵌的spark1.2.0版本,该版本BUG还是蛮多的,尤其是一些spark sql的BUG,简直不能忍。spark1.4.0新出的支持SparkR,其他用R的同时很期待试用该版本看看sparkR好不好用,于是乎打算升级一下spark的版本。《CDH5.1.0编译spark-assembly包来支持hive 》:http://blog.csdn.net/aaa1117a8w5s6d/article/details/44307207
maven的配置文件apache-maven-3.2.5/conf/settings.xml 增加私服地址,同时提供测试代码《用Maven编译Spark 1.0.0源码以错误解决》:http://www.iteblog.com/archives/1038
- Exception in thread “main” java.lang.OutOfMemoryError
- Cannot run program “javac”: java.io.IOException
- Please set the SCALA_HOME
- 选择相应的Hadoop和Yarn版本
《Open JDK导致的Maven Build出错 》 :http://blog.csdn.net/mydeman/article/details/6234750
不推荐大家使用OPEN-JDK- 《net.alchim31.maven/scala-maven-plugin/3.1.0 scala-maven-plugin maven依赖》:http://maven.outofmemory.cn/net.alchim31.maven/scala-maven-plugin/3.1.0/
《用SBT编译Spark的WordCount程序》:http://www.aboutyun.com/thread-8587-1-1.html
有空再搞…















 9298
9298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









