







本文部分资料转自 Hadoop日志存放路径详解
本文部分资料转自 Hadoop历史服务器详解
本文部分资料转自 董的博客:Hadoop 2.0中作业日志收集原理以及配置方法
一. Hadoop 日志存放路径详解
Hadoop 的日志有很多种,很多初学者往往遇到错而不知道怎么办,其实这时候就应该去看看日志里面的输出,这样往往可以定位到错误。Hadoop的日志大致可以分为两大类,且这两类的日志存放的路径是不一样的。本文基于Hadoop 2.x 版本进行说明的。
1. Hadoop 系统服务输出的日志
2. Mapreduce 程序输出来的日志
- 作业运行日志
- 任务运行日志 (Container 日志)
Hadoop 2.0 提供了跟 1.0 类似的作业日志收集组件,从一定程度上可认为直接重用了 1.0 的代码模块,考虑到YARN 已经变为通用资源管理平台,因此,提供一个通用的日志收集模块势在必行,由于目前通用日志收集模块正在开发中(可参考 “YARN-321” ),本文仅介绍MRv2(MapReduce On YARN)自带的日志收集模块,包括工作原理以及配置方法。
在 Hadoop 2.0 中,Mapreduce 程序的日志包含两部分,作业运行日志 和 任务运行日志(Container 日志)
1.1 Hadoop系统服务输出的日志
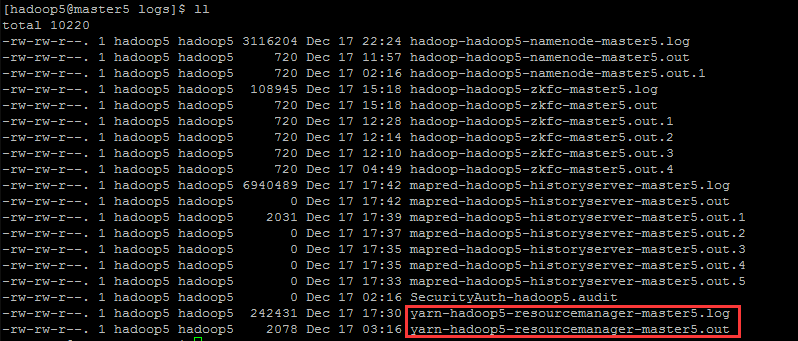
诸如 NameNode、DataNode、ResourceManage 等系统自带的服务输出来的日志默认是存放在 ${HADOOP_HOME}/logs 目录下。比如 resourcemanager 的输出日志为 yarn-${USER}-resourcemanager-${hostname}.log
- yarn 指的就是该日志的属性即为 YARN,其他类似的有 mapred、hadoop 等
${USER}s是指启动 resourcemanager 进程的用户- resourcemanager 就是指明 resourcemanager 进程,其他类似的有 namenode、zkfc、historyserver 等
${hostname}是 resourcemanager 进程所在机器的 hostname
当日志到达一定的大小(可以在 ${HADOOP_HOME}/etc/hadoop/log4j.properties 文件中配置)将会被切割出一个新的文件,切割出来的日志文件名类似 yarn-${USER}-resourcemanager-${hostname}.log.数字 的形式,后面的数字越大,代表日志越旧。在默认情况下,只保存前 20 个日志文件,比如下面:
1.2 配置 Hadoop 系统服务日志
1. 配置 log4j 日志的属性参数
比如 resourcemanager(在 ${HADOOP_HOME}/etc/hadoop/log4j.properties):
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager
$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager
.RMAppManager$ApplicationSummary=false
log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender
log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/
${yarn.server.resourcemanager.appsummary.log.file}
log4j.appender.RMSUMMARY.MaxFileSize=256MB(多大切割日志)
log4j.appender.RMSUMMARY.MaxBackupIndex=20(说明保存最近20个日志文件)
log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout
log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









