







 本文探讨了在不均衡数据集下,SVM算法面临的问题及其本质,包括类间不均衡和样本集复杂度的影响。介绍了国内外在不均衡学习领域的研究现状,如算法层面和样本层面的处理方法,如SVM的多参数优化、单类SVM、欠抽样、过抽样和SMOTE等。同时,文章强调了评估指标的重要性,如精确率、召回率、G-mean和AUC,以全面评价分类器在不均衡数据集上的性能。
本文探讨了在不均衡数据集下,SVM算法面临的问题及其本质,包括类间不均衡和样本集复杂度的影响。介绍了国内外在不均衡学习领域的研究现状,如算法层面和样本层面的处理方法,如SVM的多参数优化、单类SVM、欠抽样、过抽样和SMOTE等。同时,文章强调了评估指标的重要性,如精确率、召回率、G-mean和AUC,以全面评价分类器在不均衡数据集上的性能。
概论
- 传统的样本一般是从精心设计的实验装置中筛选出来的,这些样本往往满足一定条件。
- 而我们获得的网络样本、金融样本以及生物样本中,这些观测样本往往具有涌现性,且与传统意义的样本并不相同,大量的样本中往往有用的样本点却很少。这种某类样本的数量明显少于其他类样本数量的样本集称为不均衡样本集
问题的本质
- 从技术角度上说,任何在不同类之间展现出不等分布的样本集都应该被认为是不均衡的,并且应该展现出明显的不平衡特征。具体来说,这种不均衡形式被称为类间不均衡,常见的多数类与少数类比例是100:1,1000:1,10000:1
- 有时对少数类错分情况的后果很严重,比如癌症患者被误诊为健康人。所以需要的分类器应该是在不严重损失多数类精度的情况下,在少数类上获得尽可能高的精度
- 同时也暗示着使用单一的评价准则,例如全局精度或是误差率,是不能给不均衡问题提供足够的评价信息。因此利用含有更多信息的评价指标,例如接收机特性曲线、精度-recall曲线和代价曲线
样本不均衡的程度不是阻碍分类学习的唯一因素,样本集的复杂度也是导致分类性能恶化的重要因素,另外相对不平衡比例的增大也可能使分类性能进一步恶化 。其中样本集复杂度是广义的术语,它包括重叠、缺少代表性样本、类别间分离程度小等
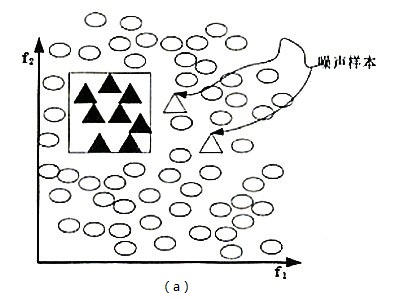
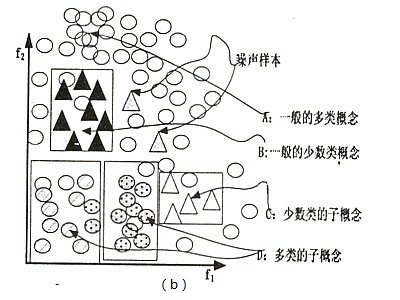
一个简单的例子,考虑到上图中,三角和空心圆分别代表少数类和多数类,通过检测,我们发现(a),(b)中的分布都是相对不均衡的,但是(a)中类间没有重叠的样本,且每一类只有一个聚类。而在(b)中既有多个聚类还有重叠的样本,其中的子集(聚类)C也许不会被分类器学习,这是因为它缺乏具有代表性的样本
- 由目标样本稀少导致的不均衡问题,所关注的目标类(少数类)很少,即类间的不均衡。此外,少数类样本集中也许还包含一个少数有限样本的子集(分离项),称之为类内的不均衡。小分离项存在导致分类性能大大地下降
符号定义
为了清晰的表述,首先定义一些用于描述不均衡样本分类的一些概念,考虑一个给定的含有 m 个样本的训练样本集 s 即 |s|=m ,我们定义:
- s={ (xi,yi)} ,i=1,…,m,其中 xi∈X 是n维特征空间 X={ f1,f2,...,fn} 的样本,且 yi∈Y={ 1,...,C} 是与样本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









