









 本文提出了一种针对多轮Text-to-SQL任务的交互式方法,使用两阶段模型生成中间表示Tree-SQL,再转化为SQL语句。针对上下文相关问题,提出重用策略,通过概率分配重用历史Tree-SQL中的子树,有效减少错误传播。在SParC数据集上,该方法实现了State-of-the-Art性能,特别是在值预测方面。
本文提出了一种针对多轮Text-to-SQL任务的交互式方法,使用两阶段模型生成中间表示Tree-SQL,再转化为SQL语句。针对上下文相关问题,提出重用策略,通过概率分配重用历史Tree-SQL中的子树,有效减少错误传播。在SParC数据集上,该方法实现了State-of-the-Art性能,特别是在值预测方面。
论文笔记:An Interactive NL2SQL Approach with Reuse Strategy
目录
导语
- 会议:DASFAA 2021
- 地址:https://link.springer.com/chapter/10.1007/978-3-030-73197-7_19
摘要
本文研究了多轮的Text-to-SQL交互任务,与之前使用端到端方式的模型不同,本文提出使用两阶段模型。首先生成一个SQL语法树,称为Tree-SQL,作为一种中间表示。然后再从Tree-SQL推断出最终的SQL语句。对于这类上下文相关(context-dependent)的问题,提出了一种重用策略(Reuse strategy),可以将之前预测的Tree-SQL中的子树赋予一个概率。在SParC数据集的具有“value selection”任务上,所提出方法实现了SOTA的表现。同时,本文也通过实验验证了重用策略的有效性。
关键词
Context-dependent semantic parsing, Reuse strategy, Intermediate representation
1 简介
单轮的跨数据库Text-to-SQL任务,如Spider数据集是不现实的。因为Spider中假设所有的问题都是上下文独立(context-independent)的无关问题,即在单回合交互中将每个问题映射到独立可执行的SQL查询。在真实的场景中,一个数据分析者通常会通过在多回合交互中询问一系列相关问题来搜索数据库。这些问题通常在语义上相关,因此一个问题可能包括对以前问题部分的引用/重用。
SParC数据集对处理丰富的上下文信息和问题之间的主题关系提出了新的挑战。此外,该任务强调泛化,因为每个数据库在训练数据集或开发/测试数据集中只出现一次。解决与上下文相关的Text-to-SQL任务并非易事,因为大多数现有的神经模型都不能提供令人满意的结果。
受到IRNet模型(可以参考我的博客)在解决上下文无关的Text-to-SQL任务时的启发,由于自然语言语句和SQL语句之间的不匹配,我们也引入一种中间表示,称为Tree-SQL,这是一种符合SQL语法的树结构。并且,这种表示可以被用来支持值的预测(value prediction),这在之前的大多数工作中都没有考虑到,而且无法生成完整的SQL语句来执行。
对于这类context-dependent的问题的解决,一种直观的认识是在预测下一个SQL语句时,重新使用上文中生成的Tree-SQL历史信息。具体来说,我们为Tree-SQL的每个子树分配一个概率,该概率表示在预测新SQL时它被重用的可能性。对于值预测,我们通过将开放域的值选择(value selection)问题转换为问题的封闭域值提取(value extraction),为SQL查询中的特定数值/字符串值生成正确的预测。
2 相关工作
对于NL2SQL任务,在WikiSQL数据集和更复杂的Spider数据集上,上下文无关(context-independent)的语义解析已经得到了很好的研究。一些研究在这两个数据集上都取得了很好的结果。与上下文无关的语义分析相比,上下文相关的语义分析是近年来才逐渐流行起来的,并且已经有了一些基准数据集,如ATIS、SequentialQA和SParC。在这些数据集中,SParC是最具挑战性的一个,它具有复杂的语义问题和数据库模式(schema)。
Suhr等人提出了一种基于ATIS单域数据集的模型,该模型语义薄弱,上下文类型较少。它维护一个交互级(interaction-level)编码器,并为下一次预测复制先前预测的查询片段。它的段级(segment-level)复制策略受到错误传播的影响。为了解决这个问题,Edit-SQL模型(可以参考我的博客)在SParC上应用了token-level的编辑策略,该策略对错误传播很健壮,但在所有可能的目标token上产生了很高的预测开销。对于历史答案的重用,segment-level太粗而token-level太细。我们的方法进一步扩展了折中的重用策略,该策略主要关注以前的Tree-SQL的操作级重用,以更好地探索连续问题之间的相关性,并获得更准确的映射结果。
3 方法
3.1 任务定义
令 X X X和 Y Y Y分别表示问题Question和对应的SQL语句。 S ^ = [ s ^ 1 , s ^ 2 , … , s ^ i , … , s ^ m ] \hat{S}=\left[\hat{s}_{1}, \hat{s}_{2}, \ldots, \hat{s}_{i}, \ldots, \hat{s}_{m}\right] S^=[s^1,s^2,…,s^i,…,s^m]表示数据库的schema,其中每一个 s ^ i \hat{s}_{i} s^i都表示一个原始的行,即table.column。
在上下文相关的语义解析任务中,我们维护一个交互历史。 I t = [ ( X 1 , Y 1 ) , ( X 2 , Y 2 ) , … , ( X t − 1 , Y t − 1 ) I_{t}=\left[\left(X_{1}, Y_{1}\right),\left(X_{2}, Y_{2}\right), \ldots,\left(X_{t-1}, Y_{t-1}\right)\right. It=[(X1,Y1),(X2,Y2),…,(Xt−1,Yt−1),其包含了前t-1轮的Question和预测的SQL语句。故整个问题可以定义如下:给出当前轮次t的Question X t X_t Xt和数据库scheme信息 S ^ \hat{S} S^,我们的目标是学习这样一个最优的映射函数 f : ( X t , I t , S ^ ) → Y t f:\left(X_{t}, I_{t}, \hat{S}\right) \rightarrow Y_{t} f:(Xt,It,S^)→Yt。

3.2 Tree-SQL
我们提出Tree-SQL作为一种中间表示。其语法如图1所示。下图2给出了SParC的数据示例和第三轮得到的Tree-SQL的形状。 当前,在Spider或SParC这样的复杂数据集上,很少有工作可以处理“值预测”(value prediction)问题,主要原因是值的预测有很大难度。值具有不同的来源和变体形式,比如图2中的“North America”和“3000” 这些值。
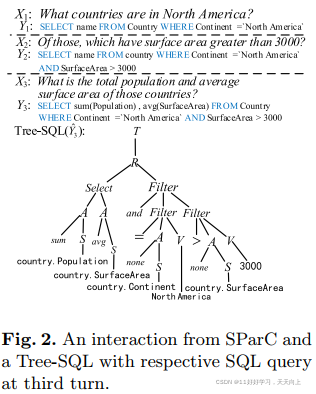
为了减小搜索空间,Tree-SQL将open-domain的value prediction问题转换为closed-domain的NL语句中value extraction任务。我们定义了三个参数来维护值的具体内容,分别是
V
t
V_t
Vt表示值出现在第
V
t
V_t
Vt轮次的Question中,
V
s
V_s
Vs表示值在当前Question中的offset(即对应的index起始下标),
V
d
V_d
Vd表示值的长度。通过这三个参数,就可以唯一确定值。
为了推断一个SQL查询,我们只需预先遍历树结构,并根据图1中定义的语法规则将每个树节点映射到相应的SQL查询组件。
3.3 基本模型
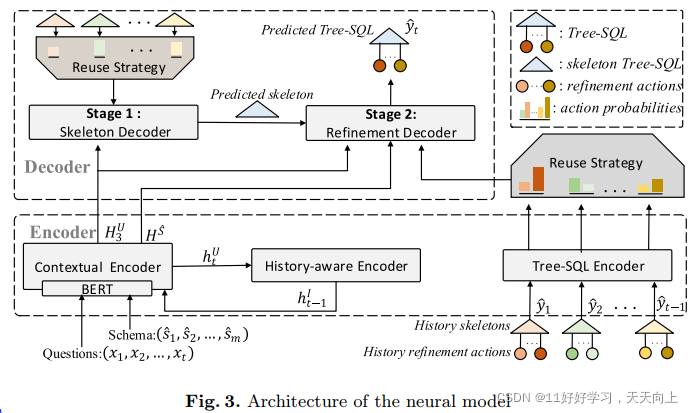
我们设计了一个基于编码器-解码器结构的SQL语法感知模型来生成Tree-SQL。它将问题、数据库模式和历史Tree-SQL作为输入,其输出一个Tree-SQL。模型整体结构如图3所示。
Contextual Encoder 我们使用预训练的BERT作为第一层对问题 X t X_t Xt和数据库模式 S ^ \hat{S} S^进行编码,它们由[SEP]标记连接在一起: [ C L S ] , X t , [ S E P ] , s 1 , [ S E P ] , s 2 , [ S E P ] , … s m , [CLS],X_t,[SEP], s_1,[SEP], s_2, [SEP],…s_m, [CLS],Xt,[SEP],s1,[SEP],s2,[SEP],…sm,。然后将问题的BERT嵌入送入Bi-LSTM层,生成最终的问题嵌入 H t U H_t^U HtU。对于schema的编码,我们采用attention来估计不同项的重要性,同时也可以用来识别主-外键关系。最后的schema嵌入是加权组合 H S H^S HS。
History-Aware Encoder 为了揭示不同问题/查询对之间的相关性,我们设计了一个基于LSTM的历史感知编码器,在交互过程中融入上下文信息。编码器在当前嵌入问题 h t U h_t^U htU与其隐藏状态 h t I h_t^I htI之间迭代更新。
Two-Stage Tree-SQL Decoder 我们的解码器不是应用端到端方法,而是首先从嵌入生成一个Tree-SQL。Tree-SQL的生成是一个从粗到细(Coarse-to-Fine)的框架预测过程,包括两个阶段。
- 在第一阶段,我们应用一个框架解码器(skeleton decoder)来生成只有内部节点的Tree-SQL的框架。
- 在第二阶段,我们采用一个细化解码器(refine decoder)来填充缺失的叶节点。
图3演示了我们的解码器的过程。为了解码第k个动作,我们建立了两个可学习的嵌入,
a
k
a_k
ak表示动作的语义,
b
k
b_k
bk表示动作的类型,并学习了一个上下文向量
c
k
c_k
ck。两种解码器共享相同的可学习参数,不同之处在于上下文向量。
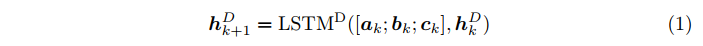
(a) Skeleton Decoder Tree-SQL的内部节点不涉及特定的原始列和值。因此,框架解码器的上下文向量
c
k
c_k
ck(记为
L
S
T
M
D
1
LSTM^{D_1}
LSTMD1)仅通过
D
1
D_1
D1的隐藏状态与所有加权问题嵌入
H
U
H^U
HU之间的注意来自问题信息
c
k
t
o
k
e
n
c^{token}_k
cktoken,即
c
k
=
[
c
k
t
o
k
e
n
]
c_k = [c^{token}_k]
ck=[cktoken]。
(b) Refinement Decoder 细化解码器(记为 L S T M D 2 LSTM^{D_2} LSTMD2)用于预测框架中缺失的叶子节点,在Question嵌入的基础上,也需要使用schema的嵌入 H S H^S HS来学习 c k s c h e m a c^{schema}_k ckschema,即 c k = [ c k t o k e n ; c k s c h e m a ] c_k = [c^{token}_k; c^{schema}_k] ck=[cktoken;ckschema]。
根据以上定义,我们可以定义两级解码器的loss函数为
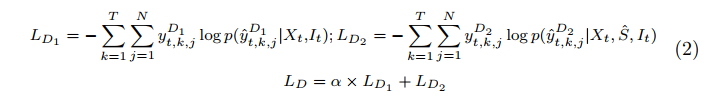
我们采用交叉熵作为我们的解码器的损失函数和一个权重因子α来调整两个解码器的重要性,其中N是动作的数量(
y
t
,
k
,
j
=
1
y_{t,k,j} = 1
yt,k,j=1表示第j个action与ground truth一致,
y
t
,
k
,
j
=
0
y_{t,k,j} = 0
yt,k,j=0表示j个action与ground truth不一致)。
3.4 利用重用机制进行优化
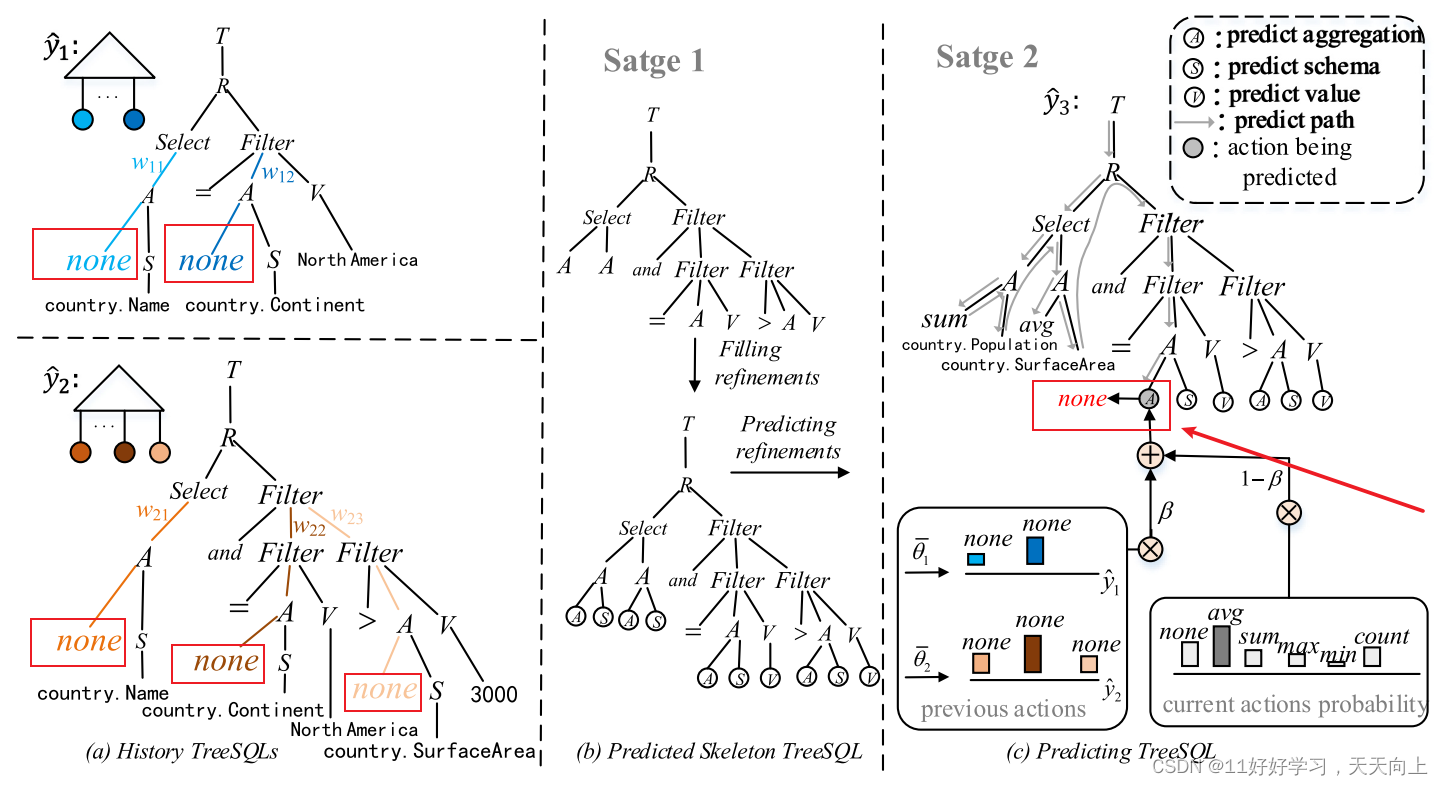
为了利用不同轮次中Tree-SQL的相关性,我们提出了一种优化技术,通过重用历史轮次中生成的部分SQL语法树来改进Tree-SQL的预测。重用机制的过程如图4所示。
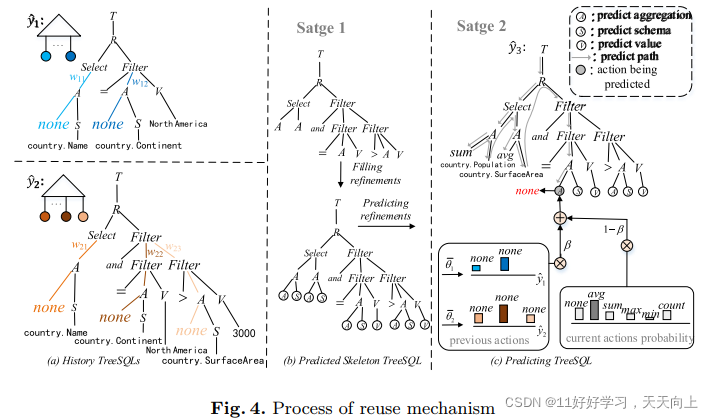
我们首先通过一个基于Bi-LSTM结构的编码器生成Tree-SQL的嵌入。然后,通过对解码器的隐藏状态和Tree-SQL嵌入之间的attention机制,衡量先前不同轮次预测的Tree-SQL
c
l
,
k
q
u
e
r
y
c_{l,k}^{query}
cl,kquery 的重要性。为此,定义一个新的具有query嵌入的上下文向量
c
k
c_k
ck为
c
k
=
[
c
k
t
o
k
e
n
;
c
k
s
c
h
e
m
a
;
c
k
q
u
e
r
y
]
c_k = [c^{token}_k; c^{schema}_k; c^{query}_k]
ck=[cktoken;ckschema;ckquery]。
我们通过将sigmoid函数用于上下文向量 c k c_k ck来预测重用之前Tree-SQL action的概率。我们也为每一个子树(sub-tree)生成一个权重 w l , i w_{l,i} wl,i表示该子树中重用的可能性。然后,输出分布就变成了当前操作与多轮次和多个子树的历史Tree-SQL之间的权衡。
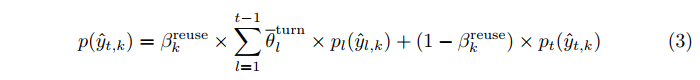
当前回合的动作概率表示为
p
t
p_t
pt,而从之前的Tree-SQL重用的动作概率表示为
p
l
p_l
pl,其中
1
<
=
l
<
=
t
−
1
1<=l<=t-1
1<=l<=t−1。图4显示了重用策略的一个示例。假设我们有两个历史Tree-SQL,
y
^
1
\hat{y}_1
y^1和
y
^
2
\hat{y}_2
y^2。在生成
y
^
3
\hat{y}_3
y^3时,我们重用以前的Tree-SQL中的大多数结构和一些叶节点。
举个例子,如图4所示。我们在预测
y
^
3
\hat{y}_3
y^3时,前面已经有了预测的历史信息
y
^
1
\hat{y}_1
y^1和
y
^
2
\hat{y}_2
y^2,其结构如图4(a)所示。在进行预测时,首先由Skeleton Decoder预测整体SQL语句框架,得到图4(b)上方的那个形式。接着,Refinement Decoder对叶子节点进行补充(即图4(b)上方到下方的形式的过程)和预测动作(即图4©部分),在进行动作预测时,使用了重用机制。该机制的运作示例如图所示:假如我们要预测图4©中的暗色节点(即下图中箭头所指的节点A),那么一方面我们使用LSTM预测它所有本来可能的动作,预测得到各个action的概率分布如右下角current actions probability所示。同时,我们也参考之前预测A这个类型节点时预测得到的action,如下图左侧我用红框标注的位置。对于
y
^
1
\hat{y}_1
y^1,它一共预测过两次A,得到了两个结果,都是none。对于
y
^
1
\hat{y}_1
y^1,它一共预测过三次A,得到了三个结果,都是none。所以他们的历史信息可以作为参考,其概率分布如图4©右下角previous actions。最后,解码器以
β
\beta
β概率考虑原始的历史预测结果作为参考得到最终输出。
4 实验
4.1 实验设置
数据集 我们在SParC上进行实验,这是一个专家标记的跨域上下文相关数据集,包含4,298个相关问题序列(12k+问题与SQL查询配对),查询138个不同域的200个复杂数据库。
评价指标。对于不带值的SQL,为了避免排序的影响,我们遵循之前的方法,将预测查询分解为不同的组件,并计算ground truth值与预测SQL之间的集合匹配精度。报告了两个指标:问题匹配准确性(QMA)和交互匹配准确性(IMA)。对于有值的SQL,我们直接使用生成的SQL执行数据库,并报告问题执行准确性(QEA)和交互执行准确性(IEA)。
4.2 整体结果
表1展示了不预测值时的EM指标的结果表现。
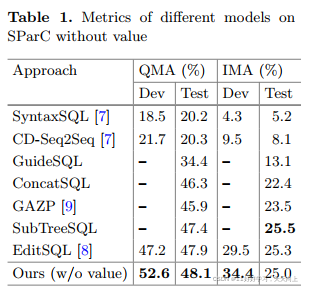
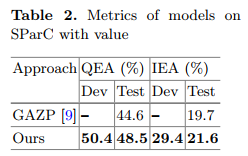
表2展示了带有值预测时的EX指标的表现。
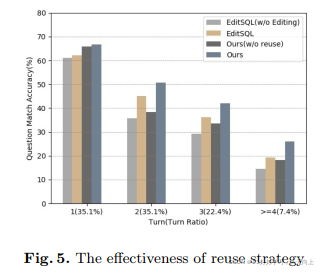
4.3 重用机制的有效性
为了进一步理解重用策略的有效性,我们将我们的方法与无值任务上的EditSQL进行比较,后者也支持编辑策略。如图5所示,应用重用策略对所有轮次都有利,并使模型在以后轮次时更加稳定。利用问题之间的相关性可以有效地减少错误的传播。
5 总结
在本文中,我们提出了一种具有编码器-解码器架构的神经方法,用于上下文相关的跨域Text-to-SQL生成。我们设计了一种新的树结构,Tree-SQL,它被用作转换的中间表示。为了利用不同交互的问题之间的相关性,我们引入了一种重用机制来改进我们的预测。在具有挑战性的SParC基准上的实验结果证明了我们的模型的有效性。特别是,我们的Tree-SQL扩展了值预测模块,以适应更真实的应用程序场景(SQL通常包含值),我们的模型实现了最先进的值预测任务。

















 3735
3735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









