







文章目录
1.Linux虚拟文件系统
Linux 虚拟文件系统:文件系统在不同的上下文有不同的含义
- 存储设备的文件系统
格式化,某个目录下挂载或卸载文件系统,在存储设备上组织文件的方法,包括数据结构和访问方法,到存储设备。 - Linux内核管理的文件系统
(1)内核中负责管理和存储文件的模块,即文件系统模块。
(2)Linux文件系统的架构如下图所示,分为用户空间、内核空间和硬件3个层面:
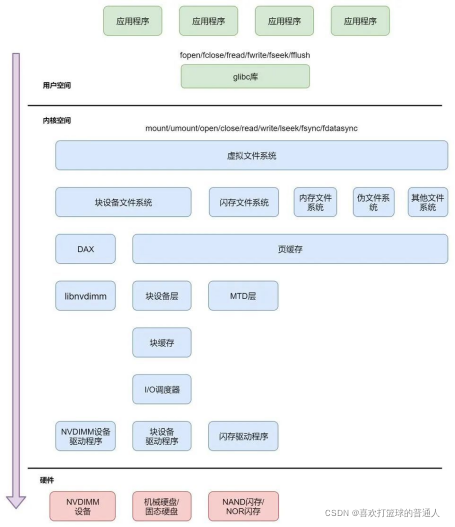
内核文件系统中 “cache” 和 “buffer” 的区别
- 页缓存cache是针对文件来说的,DAX不使用cache
- buffer块缓存是针对块设备来说的
2.硬件与Linux内核
外部存储设备分为块设备、闪存和 NVDIMM 设备 3 类,
块设备主要有以下两种
- 机械硬盘:
机械硬盘的读写单位是扇区。访问机械硬盘的时候,需要首先沿着半径 方向移动磁头寻找磁道,然后转动盘片找到扇区。 - 闪存类块设备
使用闪存作为存储介质,里面的控制器运行固化的驱动程序,驱动程序的功能之一是闪存转换层(Flash Translation Layer,FTL),把闪存转换为块设备,常见的闪存类块设备是固态硬盘 splid State Drives,SSD。
相较于机械硬盘的优点:
访问速度快,因为没有机械操作:抗振性很高, 便于携带。
闪存(Flash Memory)按存储结构分为 NAND 闪存和 NOR 闪存,两者的区别如下:
- 闪存的擦写原理:
(1)在写入数据之前需要擦除一个擦除块,因为向闪存写数据只能把一个位从 1 变成 0,不能从 0 变成 1,擦除的目的是把擦除块的所有位设置为 1
(2)一个擦除块的最大擦除次数有限,NOR闪存的擦除块的最大擦除次数是 10^4~10^3, NAND 闪存的擦除块的最大擦除次数是 10^3~10^6。 - NOR闪存的容量小,NAND 闪存的容量大。
NOR 闪存支持按字节寻址,支持芯片内执行(eXecute In Place,XIP),可以直接 在闪存内执行程序,不需要把程序读到内存中; - NAND 闪存的最小读写单位是页或子页, 一个擦除块分为多个页,有的 NAND 闪存把页划分为多个子页。
- NOR 闪存读的速度比 NAND 闪存块,写的速度和擦除的速度都比 NAND 闪存慢
- NOR 闪存没有坏块;NAND 闪存存在坏块。
主要是因为消除坏块的成本太高 NOR 闪存适合存储程序,一般用来存储引导程序比如 uboot 程序;
NAND 闪存适合存储数据。
为什么要针对闪存专门设计文件系统?
主要原因如下:
- NAND 闪存存在坏块,软件需要识别并且跳过坏块。
- 需要实现损耗均衡( wear leveling),损耗均衡就是使所有擦除块的擦除次数均衡, 避免一部分擦除块先损坏。
机械硬盘和 NAND 闪存的主要区别如下:
- 机械硬盘的最小读写单位是扇区,扇区的大小一般是 512 字节:NAND 闪存的最 小读写单位是页或子页。
- 机械硬盘可以直接写入数据:NAND 闪存在写入数据之前需要擦除一个擦除块。
- 机械硬盘的使用寿命比 NAND 闪存长:机械硬盘的扇区的写入次数没有限制:NAND 闪存的擦除块的擦除次数有限。
- 机械硬盘隐藏坏的扇区,软件不需要处理坏的扇区:NAND 闪存的坏块对软件可 见,软件需要处理坏块。
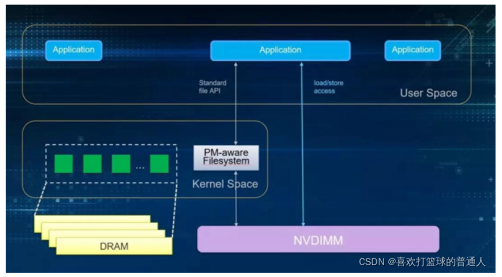
NVDIMM(Nonn-Volatile DIMM,非易失性内存
- DIMM 是 Dual-Inline-Memory-Modules 的缩写,表示双列直插式存储模块,是内存的一种规格)
- 设备把 NAND 闪存、内存和超级电容集成到一起,访问速度和内存一样快,并且断电以后数据不会丢失。在断电的瞬间, 超级电容提供电力,把内存中的数据转移到 NAND 闪存。
3.内核空间层面
内核实现了一个抽象层,称为虚拟文件系统(Virtual File System,VFS),也称为虚拟文件系统切换(Virtual Filesystem Switch,VFS) 文件系统分为以下几种。
块设备文件系统,
- 存储设备是机械硬盘和固态硬盘等块设备,常用的块设备文件 系统是 EXT 和 btrfs。
- EXT 文件系统是 Linux 原创的文件系统,目前有 3 个 成版本:EXT[2-4]。
闪存文件系统,
- 存储设备是 NAND 闪存和 NOR 闪存,常用的闪存文件系统是 JFFS2 (日志型闪存文件系统版本2, Journalling Flash File System version2)和 UBIFS(无序区块镜像文件系统, Unsorted Block Image File System)。
- 内存文件系统的文件在内存中,断电以后文件丢失,常用的内存文件系统是 tmpfs, 用来创建临时文件。
伪文件系统,
- 是假的文件系统,只是为了使用虚拟文件系统的编程接口,常用的 伪文件系统如下所示:
- sockfs,这种文件系统使得套接字(socket)可以使用读文件的接口 read 接收报文, 使用写文件的接口 write 发送报文。
- proc 文件系统,最初开发 proc 文件系统的目的是把内核中的进程信息导出到用户空间, 后来扩展到把内核中的任何信息导出到用户空间,通常把 proc 文件系统挂载在目录 “proc” 下。
- sysfs,用来把内核的设备信息导出到用户空间,通常把 sysfs 文件系统挂载在目录 "/sys"下。
- hugetlbfs,用来实现标准巨型页。
- cgroup 文件系统,控制组(control group cgroup)用来控制一组进程的资源, cgroup 文件系统使管理员可以使用写文件的方式配置 cgroup。
cgroup2 文件系统, cgroup2 是 cgroup 的第二个版本, cgroup2 文件系统使管理员可 以使用写文件的方式配置 cgroup2。
这些文件系统又各自有着相关的特性:
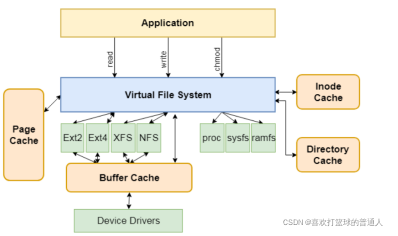
- 页缓存:访问外部存储设备的速度很慢,为了避免每次读写文件时访问外部存储设备,文件系统模块为每个文件在内存中创建了一个缓存,因为缓存的单位是页,所以称为页缓存。
- 块设备层:块设备的访问单位是块,块大小是扇区大小的整数倍。内核为所有块设备实现了统一 的块设备层。
- 块缓存:为了避免每次读写都需要访问块设备,内核实现了块缓存,为每个块设备在内存中创 建一个块缓存。
缓存的单位是块,块缓存是基于页缓存实现的。 - IO 调度器:访问机械硬盘时,移动磁头寻找磁道和扇区很耗时,如果把读写请求按照扇区号排序, 可以减少磁头的移动,提高吞吐量。
IO 调度器用来决定读写请求的提交顺序,针对不同的 使用场景提供了多种调度算法:NOOP(No Operation)、CFQ(完全公平排队, Complete Fair Queuing)和 deadline(限期)。
NOOP 调度算法适合闪存类块设备,CFQ 和 deadline调度算 法适合机械硬盘。 - 块设备驱动程序:每种块设备需要实现自己的驱动程序。
内核把闪存称为存储技术设备( Memory Technology Device,MTD),为所有闪存实现 了统一的 MTD 层,每种闪存需要实现自己的驱动程序。
针对 NVDIMM 设备,文件系统需要实现 DAX(Direct Access直接访问:X 代表 eXciting,没有意义,只是为了让名字看起来酷),绕过页缓存和块设备层,把 NVDIMM 设备里面的内存直接映射到进程或内核的虚拟地址空间。
- libnvdimm 子系统提供对 3 种 NVDIMM 设备的支持:
持久内存(persistent memory,PMEM) 模式的 NVDIMM 设备,块设备(block,BLK)模式的 NVDIMM 设备,以及同时支持PMEM 和 BLK 两种访问模式的 NVDIMM 设备。 - PMEM 访问模式是把 NVDIMM 设备当作内存,BLK 访问模式是把 NVDIMM 设备当作块设备。每种 NVDIMM 设备需要实现自己的驱动程序。
4.下一代存储技术NVIDMM
NVDIMM (Non-Volatile Dual In-line Memory Module) 是一种可以随机访问的, 非易失性内存。
- 非易失性内存指的是即使在不通电的情况下, 数据也不会消失。因此可以在计算机掉电 (unexpected power loss),系统崩溃和正常关机的情况下, 依然保持数据。
- NVDIMM 同时表明它使用的是 DIMM 封装, 与标准DIMM 插槽兼容, 并且通过标准的 DDR总线进行通信。考虑到它的非易失性, 并且兼容传统DRAM接口, 又被称作Persistent Memory。
目前, 根据 JEDEC 标准化组织的定义, 有三种NVDIMM 的实现。分别是:
- NVDIMM-N
(1)指在一个模块上同时放入传统 DRAM 和 flash 闪存,计算机可以直接访问传统 DRAM。支持按字节寻址,也支持块寻址。通过使用一个小的后备电源,为在掉电时数据从 DRAM 拷贝到闪存中提供足够的电能;当电力恢复时再重新加载到 DRAM 中。
(2)它的工作方式决定了它的 flash 部分是不可寻址的 - NVDIMM-F
(1)指使用了 DRAM 的DDR3或者 DDR4 总线的flash闪存。我们知道由 NAND flash 作为介质的 SSD,一般使用SATA,SAS 或者PCIe 总线。
(2)使用 DDR 总线可以提高最大带宽,一定程度上减少协议带来的延迟和开销,不过只支持块寻址。 - NVDIMM-P
(1)它既支持块寻址, 也支持类似传统 DRAM 的按字节寻址。它既可以在容量上达到类似 NAND flash 的TB以上, 又能把延迟保持在10的2次方纳秒级
(2)通过将数据介质直接连接至内存总线,CPU 可以直接访问数据,无需任何驱动程序或 PCIe 开销。而且由于内存访问是通过64 字节的 cache line,CPU 只需要访问它需要的数据,而不是像普通块设备那样每次要按块访问
(3)基于3D XPoint™ 技术的Intel® Optane™ DC Persistent Memory。可以认为是NVDIMM-P 的一种实现。
软件如果要充分利用持久性内存的特性,指令集架构上至少需要支持:
-
写的原子性
(1)表示对于持久性内存里任意大小的写都要保证是原子性的, 以防系统崩溃或者突然掉电。
IA-32 和 IA-64 处理器保证了对缓存数据最大64位的数据访问 (对齐或者非对齐) 的写原子性。
(2)因此,软件可以安全地在持久性内存上更新数据。这样也带来了性能上的提升, 因为消除了copy-on-write 或者 write-ahead-logging 这种保证写原子性的开销。 -
高效的缓存刷新flushing
(1)出于性能的考虑, 持久性内存的数据也要先放入处理器的缓存(cache)才能被访问
(2)经过优化的缓存刷新指令减少了由于刷新 (CLFLUSH) 造成的性能影响。
(3)a. CLFLUSHOPT 提供了更加高效的缓存刷新指令
(4) CLWB (Cache Line Write Back) 指令把cache line上改变的数据写回内存 (类似CLFLUSHOPT),但是无需让这条 cache line 转变成无效状态(invalid, MESI protocol),而是转换成未改变的独占状态(Exclusive)。
(5)CLWB 指令实际上是在试图减少由于某条cache line刷新所造成的下次访问必然的cache miss。 -
提交至持久性内存(Committing to Persistence)
新的用于持久性写的提交指令 PCOMMIT 可以把内存子系统写队列中的数据提交至持久性内存。 -
非暂时store操作的优化(Non-temporal Store Optimization)
当软件需要拷贝大量数据从普通内存到持久性内存中时(或在持久性内存之间拷贝), 可以使用弱顺序, 非暂时的store操作 (比如使用MOVNTI 指令)。
因为Non-temporal store指令可以隐式地使要回写的那条cache line 失效, 软件就不需要明确地flush cache line了
持久内存所处地位
- 我们可以看到持久内存处于外存(HDD或者SSD)以及内存DRAM之间,其不论在容量、性能、价格上都是处于两者的中间位置。
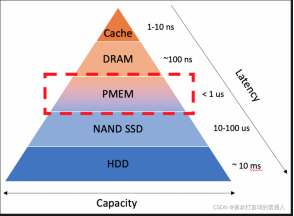
持久内存三个最重要的特征:大, 快,持久性:
- 大:目前持久内存单条内存容量最大可以达到 512 GB,而目前服务器单条内存一般最多到 32/64 GB。也就是说,单台服务器使用持久内存可以轻松到达 TB 级别的内存容量。另一方面,单位价格来说,持久内存为普通内存的一半左右。
- 快:既然也号称为内存,那必然不能慢。可以看到,持久内存相比较于普通 SSD 有1-2个数量级的延迟性能优势,相比较于硬盘优势更加巨大。当然对比与DRAM,其会有一定的性能差距。但是实际使用中由于性能瓶颈不一定在内存上,所以一般不会有特别明显的差距(一般性能衰退在一倍以内)。
- 持久性:通俗来说,就是持久内存有跟硬盘一样的特性,断电以后重启,内存中的数据依然存在。此项特性可以说是秒杀内存,内存中的数据我们都知道断电或者程序以外退出以后就不复存在。此项特性使得持久内存即可以当做一个高速持久化设备使用,也可以满足内存应用某些场景下的快速恢复的需求。
数据中心单台服务器上的典型配置

5.mmap和DAX
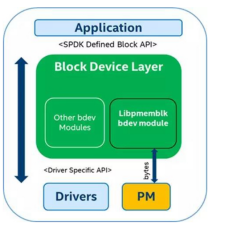
Pmem在SPDK的bdev层暴露为一个块设备,使用块设备接口和上层进行通信。
- 从图中我们可以看到libpmemblk 把块操作转换成了字节操作。
传统IO方式
- 传统的I/O方式, 即缓存I/O (Buffered I/O). 大多数操作系统默认的IO操作方式都是缓存IO。
- 该机制使IO数据缓存在操作系统的page cache 中,即:数据会被先拷贝到操作系统的内核空间的缓冲区中,然后才会从内核空间的缓冲区拷贝到指定的用户地址空间
- 在Linux 中, 这种访问文件的方式就是通过read/write 系统调用来实现

内存映射IO mmap()
-
通过mmap获得了对应文件的一个指针,然后就像操作内存一样进行赋值或者做memcpy/strcpy, 这种我们称之为load/store操作(这种操作一般需要msync、fsync来落盘)。

-
mmap因为建立了文件到用户空间的映射关系,可以看作是把文件直接拷贝到用户空间,减少了一次数据拷贝。但是mmap依然需要依靠page cache。
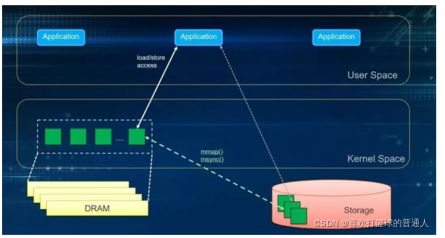
DAX
- 即direct access,这个特性是基于mmap的。
- DAX的区别在于完全不需要page cache,直接对存储设备访问,所以它就是为了NVDIMM而生的。
- 应用对于mmap的文件操作,是直接同步到NVDIMM上的。
- DAX目前在XFS, EXT4, Windows的 NTFS 上都已经支持。
- 需要注意的是, 使用这个模式,要对应用程序或者文件系统进行修改。
- 读写直接操作PMEM上的数据,文件系统需要在mount 的时候,加入 "-o dax"参数。
缺点是:DAX极大地提高了文件系统在PMEM设备上的性能,但是还有一些问题没有解决,比如:
文件系统的metadata还是需要使用page cache或buffer cache。
PMDK
- libpmemblk 实现了一个驻留在pmem中的同样大小的块的数组。
- 里面每个块对于突然掉电,程序崩溃等情况依然保持原子事务性。
- libpmemblk是基于libpmem库的,libpmem是PMDK中提供的一个更底层的库, 尤其是对于flush的支持。它能够追踪每次对pmem的store操作,并保证数据落盘为持久性数据
NVIDMM分类
- NVIDMM-N:memory mapped DRAM,提供字符访问接口,在三种产品中性能最好,容量最小
NVDIMM-N既可以用作缓存,又可以作为块存储设备来用。典型代表是类似intel 的AEP - NVDIMM-F:memory mapped Flush,只提供块设备接口。Nand Flush直接链接到Memory controller channel。
NVIDMM-F主要用作存储。可以用来快速构建高密度的内存池存储池。 - NVIDMM-P:Under Development,提供块设备和字符设备访问接口。
6.PMEM的应用
构建基于NVDMM的文件系统
-
以PMEM设计的文件系统是NOVA Filesystem
-
ZUFS的全称是Zero-copy User Filesystem。
(1)声称是实现了完全的zero-copy,甚至文件系统的metadata都是zero-copy的。
(2)ZUFS主要是为了PMEM设计,但是也可以支持传统的磁盘设备,相当于是FUSE的zero-copy版本,是对FUSE的性能的提升
7.PMEM的名称空间
与 RAM 一样,PMEM 储存提供字节级别的访问
- 使用 PMEM 时,单个名称空间可以包含多个交错式的 NVDIMM,使这些 NVDIMM 都可用作单个设备。可通过两种方式来配置 PMEM 名称空间。
将 PMEM 与 DAX 搭配使用
- 为 Direct Access (DAX) 配置 PMEM 名称空间后,访问内存时会绕过内核的页面超速缓存,并直接进入媒体。软件可以单独直接读取或写入该名称空间的每个字节。
将 PMEM 与 BTT 搭配使用
- 与在传统的磁盘驱动器中一样,将按扇区访问配置为以 BTT 模式运行的 PMEM 名称空间,而不是像在 RAM 中一样采用按字节寻址的模式。某个转换表机制会将访问活动批处理成扇区大小的单元。
- BTT 的优点在于,储存子系统会确保将每个扇区完全写入到基础媒体,如果某项写入操作出于某种原因而失败,则会取消注册该操作。因此,无法在给定的扇区中进行部分写入。此外,对 BTT 名称空间的访问会由内核超速缓存。缺点在于BTT 名称空间不支持 DAX。
8.管理持久内存PM的工具
ipmctl
- PM的管理工具
ipmctl create -goal PersistentMemoryType=AppDirect创建AppDirect GOAL
ipmctl show -firmware查看DIMM固件版本
ipmctl show -dimm列出DIMM
ipmctl show -sensor获取更多详细信息,类似SMART
ipmctl show -topology定位device位置
ndctl
- 管理“libnvdimm”对应的系统设备(Non-volatile Memory),常用命令:
ndctl list -u
create-namespace
通过fsdax, devdax, sector, and raw这四种方式管理PM的namespace
fsdax,默认模式,创建之后将在文件系统下创建块设备/dev/pmemX[.Y],可以在其上创建xfs、ext4文件系统
(1)fsdax,默认模式,创建之后将在文件系统下创建块设备/dev/pmemX[.Y],可以在其上创建xfs、ext4文件系统。
(2)devdax,创建之后在文件系统下创建char /device/dev/daxX.Y,没有块设备映射出来。
但是使用这种方式仍然可以通过mmap映射(只可以使用open(),close(),mmap())
ndctl create-namespace --type=pmem --mode=fsdax --region=X [--align=4k]
# --region 指定某个pmem设备,不写的话默认是all,全部设备
# --align,内部的对齐的pagesize,默认2M,每次page fault之后读上2M的页
通过FSDAX初始化pmem
ndctl create-namespace
mkfs.xfs -f -d su=2m,sw=1 /dev/pmem0
mkdir /pmem0
mount -o dax /dev/pmem0 /pmem0
xfs_io -c "extsize 2m" /pmem0
要管理持久内存,必须安装 ndctl 包。安装此包也会安装 libndctl 包,后者提供一组用户空间库用于配置 NVDIMM。
- 这些工具通过 libnvdimm 库运行。
- 该库支持三种类型的 NVDIMM:
PMEM
BLK
同步 PMEM 和 BLK。
ndctl help subcommand
查看可用子命令的列表
ndctl --list-cmds
可用的子命令包括:
version:显示 NVDIMM 支持工具的当前版本。
enable-namespace:使指定的名称空间可供使用。
disable-namespace:阻止使用指定的名称空间。
create-namespace:从指定的储存设备创建新的名称空间。
destroy-namespace:去除指定的名称空间。
enable-region:使指定的区域可供使用。
disable-region:阻止使用指定的区域。
zero-labels:擦除设备中的元数据。
read-labels:检索指定设备的元数据。
list:显示可用的设备。
help:显示有关工具用法的信息。
设置持久内存
查看可用的 NVDIMM 储存
ndctl list --dimms
在以下示例中,系统包含三个 NVDIMM,这些 NVDIMM 位于单个三通道交错集内。
[
{
"dev":"nmem2",
"id":"8089-00-0000-12325476"
},
{
"dev":"nmem1",
"id":"8089-00-0000-11325476"
},
{
"dev":"nmem0",
"id":"8089-00-0000-10325476"
}
]
ndctl list列出可用的区域
ndctl list --regions
[
{
"dev":"region1",
"size":68182605824,
"available_size":68182605824,
"type":"blk"
},
{
"dev":"region3",
"size":202937204736,
"available_size":202937204736,
"type":"pmem",
"iset_id":5903239628671731251
},
{
"dev":"region0",
"size":68182605824,
"available_size":68182605824,
"type":"blk"
},
{
"dev":"region2",
"size":68182605824,
"available_size":68182605824,
"type":"blk"
}
]
空间以两种不同的形式显示:三个 BLK 类型的独立 64 GB 区域,或者一个 PMEM 类型的合并 189 GB 区域,
后者将三个交错式 NVDIMM 中的所有空间表示为单个卷。
这会创建支持 DAX 的块设备 /dev/pmem3,将储存配置为使用 DAX 的单个 PMEM 名称空间
- 第一个步骤是创建新的名称空间。
将三个 NVDIMM 配置成使用 Direct Access (DAX) 的单个 PMEM 名称空间。
ndctl create-namespace --type=pmem --mode=fsdax --map=memory
{
"dev":"namespace3.0",
"mode":"memory",
"size":199764213760,
"uuid":"dc8ebb84-c564-4248-9e8d-e18543c39b69",
"blockdev":"pmem3"
}
设备名称中的 3 继承自父区域编号(在本例中为 region3)。
--map=memory 选项从 NVDIMM 中设置出一部分 PMEM 储存空间,以便可以使用这些空间来分配称作结构页面的内部内核数据结构。
这样,便可以将新的 PMEM 名称空间与 O_DIRECT I/O 和 RDMA 等功能搭配使用。
最终 PMEM 名称空间的容量之所以小于父 PMEM 区域,是因为有一部分持久内存预留给了内核数据结构。
- 第二步,校验新的块设备是否可用于操作系统
fdisk -l /dev/pmem3
Disk /dev/pmem3: 186 GiB, 199764213760 bytes, 390164480 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
- 与其他任何驱动器一样,在使用该设备之前,必须先将其格式化。在本示例中,我们使用 XFS 将其格式化:
mkfs.xfs /dev/pmem3
- 将新的驱动器装入到某个目录:
mount -o dax /dev/pmem3 /mnt/pmem3
- 可以校验是否获得了一个支持 DAX 的设备
mount | grep dax
/dev/pmem3 on /mnt/pmem3 type xfs (rw,relatime,attr2,dax,inode64,noquota)
- 结果是,我们已获得一个使用 XFS 文件系统格式化的,且装有 DAX 的 PMEM 名称空间。
- 对该文件系统中的文件进行任何 mmap() 调用都会返回直接映射到 NVDIMM 上的持久内存的虚拟地址,并且会完全绕过页面超速缓存。
- 对该文件系统中的文件进行任何 fsync 或 msync 调用仍可确保将修改后的数据完全写入到 NVDIMM。
去除名称空间
- 在创建使用相同储存的其他任何类型的卷之前,我们必须卸载此 PMEM 卷,然后将其去除。
首先卸载该卷:
umount /mnt/pmem3
然后禁用名称空间:
ndctl disable-namespace namespace3.0
disabled 1 namespace
然后删除该卷:
ndctl destroy-namespace namespace3.0
destroyed 1 namespace
创建使用 BTT 的 PMEM 名称空间
- 示例将创建使用 BTT 的 PMEM 名称空间
ndctl create-namespace --type=pmem --mode=sector
{
"dev":"namespace3.0",
"mode":"sector",
"uuid":"51ab652d-7f20-44ea-b51d-5670454f8b9b",
"sector_size":4096,
"blockdev":"pmem3s"
}
接下来,校验新设备是否存在:
fdisk -l /dev/pmem3s
Disk /dev/pmem3s: 188.8 GiB, 202738135040 bytes, 49496615 sectors
Units: sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
-
与前面配置的支持 DAX 的 PMEM 名称空间一样,这个支持 BTT 的 PMEM 名称空间也会占用 NVDIMM 中的所有可用储存。
-
注意:设备名称 (/dev/pmem3s) 中的尾部 s 表示扇区 (sector),可用于轻松辨别配置为使用 BTT 的名称空间。
-
可按前一示例中所述,格式化和mount卷(mount参数不能使用DAX)。
此处显示的 PMEM 名称空间不能使用 DAX,它会使用 BTT 来提供扇区写入原子性。
每次通过 PMEM 块驱动程序进行扇区写入时,BTT 都会分配一个新的扇区来接收新数据。
完全写入新数据后,BTT 将以原子方式更新其内部映射结构,使新写入的数据可供应用程序使用。
如果在此过程中的任意时间点发生电源故障,则写入内容将会完全丢失,在这种情况下,应用程序可以访问其旧数据,而这些数据仍旧保持不变。这可以防止出现所谓"扇区撕裂"的情况。 -
与其他任何标准块设备一样,可以使用某个文件系统格式化这个支持 BTT 的 PMEM 名称空间,并在该文件系统中使用它。
但是无法将该名称空间与 DAX 搭配使用,此块设备中的文件的 mmap 映射将使用页面超速缓存。
使用内存(DRAM)模拟持久化内存(Persistent Memory)
- 精简版:一般内核只需要两步即可进行持久性内存模拟
从Linux 4.0以来,Linux内核就具备了对持久性内存设备和仿真的支持,但为了便于配置,建议使用比4.2更新的内核。
在内核中,使用对文件系统的DAX扩展创建了一个支持PMEM的环境。
要了解内核是否支持DAX和PMEM,可以使用以下命令:
# egrep '(DAX|PMEM)' /boot/config-`uname -r`
如果内置了支持就会输出类似如下的内容:
CONFIG_X86_PMEM_LEGACY_DEVICE=y
CONFIG_X86_PMEM_LEGACY=y
CONFIG_BLK_DEV_RAM_DAX=y
CONFIG_BLK_DEV_PMEM=m
CONFIG_FS_DAX=y
CONFIG_FS_DAX_PMD=y
CONFIG_ARCH_HAS_PMEM_API=y
(1)配置 grub
vim /etc/default/grub
在里面加入如下语句,前一个为要模拟的大小,后一个为模拟的持久性内存在内存中开始的位置。
也就是从内存4G开始,划分32G来模拟持久性内存。
GRUB_CMDLINE_LINUX="memmap=32G!4G"
(2)更新 grub
update-grub && reboot
在centos7下的update-grub命令是:grub2-mkconfig -o /boot/grub2/grub.cfg 这个命令。
若Linux内核默认没有支持DAX和PMEM的话
首先输入命令:
cd /usr/src
make nconfig
进入到如下的配置界面,配置PMEM和DAX
Device Drivers
NVDIMM Support
<M>PMEM;
<M>BLK;
<*>BTT
<*>NVDIMM DAX
配置PMEM
先进入到Device Drivers中,在Device Drivers中找到NVDIMM Support,需要将菜单栏向下翻,
里面的内容并不只是我们看到的第一页,NVDIMM Support 不在第一页上。
进入到NVDIMM Support 中,将里面的内容都选中:
<M>PMEM;
<M>BLK;
<*>BTT
<*>NVDIMM DAX
配置文件系统DAX
使用esc回到make nconfig的初始页面
File System
<*>Direct Access support
处理器特性设置
使用esc回到make nconfig的初始页面
Processor type and features
<*>Support non-standard NVDIMMs and ADR protected memory
其实上述所有过程,在Linux-4.15中默认都已经做了,也就是我只要 make nconfig就可以了。
所有这些配置好之后就开始编译以及安装内核:
# make -j9
# make modules_install install
然后进入到新编译的内核Linux-4.15中
使用下面的命令打印出e820表:
dmesg | grep e820
得到如下的内容:
[0.000000] e820: BIOS-provided physical RAM map:
[0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009d7ff] usable
[0.000000] BIOS-e820: [mem 0x000000000009d800-0x000000000009ffff] reserved
...
上述的usable就是我们可以使用的,从中可以划分部分区域来作为我们的持久化内存,在这里建议选取:
[0.000000] BIOS-e820: [mem 0x0000000100000000-0x000000021f5fffff] usable
其中0x0000000100000000就是4G,需要配置grub来设置:
vim /etc/default/grub
我在里面直接配置4G的空间来模拟持久化内存,在grub中添加如下语句,表示空间大小为4G,从4G内存开始的内存空间用来模拟持久化内存:
GRUB_CMDLINE_LINUX="memmap=4G!4G"
配置好后,更新grub:update-grub
使用下面的命令查看是否成功:
dmesg | grep user
可以看到,这块区域已经被模拟为了持久化内存,然后我们在主机 /dev目录下可以看到pmem0的设备,至此就可以对模拟的持久化内存进行使用了。
使用方式--建立DAX文件系统
以ext4文件系统为例
mkdir /mnt/pmemdir
mkfs.ext4 /dev/pmem0
mount -o dax /dev/pmem0 /mnt/pmemdir
这样就将目录 /mnt/pmem挂载到了持久化内存上,这个目录在之后的使用过程中就会用到
使用memmap内核选项
- pmem驱动程序允许用户基于直接访问文件系统(DAX)来使用EXT4和XFS,添加了一个新的memmap选项,该选项支持保留一个或多个范围的未分配内存以用于模拟持久内存。
- memmap参数文档在Linux内核的相关页面上。
- memmap选项使用memmap=nn[KMG]!ss[KMG]格式;其中nn是要保留的区域的大小,ss是起始偏移量,[KMG]指定大小(以千字节、兆字节或千兆字节为单位)。
配置选项通过GRUB传递给内核,更改GRUB菜单项和内核参数在Linux发行版本之间有所不同,下面是一些常见Linux发行版的说明。有关更多信息,请参阅正在使用的Linux发行版和版本的文档。
内存区域将标记为e820类型12(0xc),这在引导时可见,使用dmesg命令查看这些消息。
$ dmesg | grep e820
GRUB配置中的'memmap=4G!12G':保留4GB内存,从12GB到16GB。
1)、Ubuntu
$ sudo vim /etc/default/grub
GRUB_CMDLINE_LINUX="memmap=4G!12G"
更新完成grub后重启机器
$ sudo update-grub2
2)、RHEL
$ sudo vi /etc/default/grub
GRUB_CMDLINE_LINUX="memmap=4G!12G"
正式开始更新grub配置
On BIOS-based machines:
$ sudo grub2-mkconfig -o /boot/grub2/grub.cfg
On UEFI-based machines:
$ sudo grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg
可以使用多个配置,下面建立了两个2G大小的名称空间
"memmap=2G!12G memmap=2G!14G" will create two 2GB namespaces, one in the 12GB-14GB memory address offsets, the other at 14GB-16GB.
主机重新启动后,应该存在一个新的/dev/pmem{N}设备,在GRUB配置中指定的每个memmap区域都有一个。
这些可以使用ls /dev/pmem*显示,命名约定从/dev/pmem0开始,并为每个设备递增。
/dev/pmem{N}设备可用于创建DAX文件系统。
使用/dev/pmem设备创建并装载文件系统,然后验证是否为装入点设置了dax标志,以确认启用了dax功能。
下面展示了如何创建和挂载EXT4或XFS文件系统。
mkfs.xfs /dev/pmem0
mkdir /pmem && mount -o dax /dev/pmem0 /pmem
mount -v | grep /pmem
/dev/pmem0 on /pmem type xfs (rw,relatime,seclabel,attr2,dax,inode64,noquota)
如何为系统选择正确的memmap选项
- 为memmap内核参数选择值时,必须考虑起始地址和结束地址代表可用的RAM。
- 使用或与保留内存重叠可能导致损坏或未定义的行为,此信息可通过dmesg在e820表中轻松获得。
下面的示例服务器具有16GiB内存,"可用"内存介于4GiB(0x100000000)和~16GiB(0x3ffffffff)之间:
$ dmesg | grep BIOS-e820
[0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[0.000000] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000bffdffff] usable
[0.000000] BIOS-e820: [mem 0x00000000bffe0000-0x00000000bfffffff] reserved
[0.000000] BIOS-e820: [mem 0x00000000feffc000-0x00000000feffffff] reserved
[0.000000] BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
[0.000000] BIOS-e820: [mem 0x0000000100000000-0x00000003ffffffff] usable
要保留4GiB和16GiB之间的12GiB可用空间作为模拟持久内存,语法如下:
memmap=12G!4G
重新启动后一个新的用户定义的e820表项显示范围现在是"persistent(type12)":
$ dmesg | grep user:
[0.000000] user: [mem 0x0000000000000000-0x000000000009fbff] usable
[0.000000] user: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[0.000000] user: [mem 0x00000000000f0000-0x00000000000fffff] reserved
[0.000000] user: [mem 0x0000000000100000-0x00000000bffdffff] usable
[0.000000] user: [mem 0x00000000bffe0000-0x00000000bfffffff] reserved
[0.000000] user: [mem 0x00000000feffc000-0x00000000feffffff] reserved
[0.000000] user: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
[0.000000] user: [mem 0x0000000100000000-0x00000003ffffffff] persistent (type 12)
fdisk或lsblk程序可用于显示容量,例如:
# fdisk -l /dev/pmem0
Disk /dev/pmem0: 12 GiB, 12884901888 bytes, 25165824 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
# lsblk /dev/pmem0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
pmem0 259:0 0 12G 0 disk /pmem
- 注:大多数Linux发行版都启用了内核地址空间布局随机化(KASLR),这是由CONFIG_RANDOMIZE_BASE定义的。启用后,内核可能会在没有警告的情况下使用先前为持久内存保留的内存,从而导致损坏或未定义的行为,因此建议在16GiB或更低的系统上禁用KASLR。
9.持久内存主要优势场景是什么?
场景1:大内存低成本解决方案
- 如果你的应用内存消耗量是关键,是整个系统的资源瓶颈,那么使用持久内存将会是你降低成本的最佳解决方案。你的系统一般在两种情况下对于大内存有特别的需求
(1)基于内存性能的考量,你必须使用基于内存的解决方案,而不可能使用基于磁盘的方案,比如内存数据库(Redis, MemSQL)。
(2)虽然你的应用可以接受基于磁盘而带来的性能损耗,但是显然如果内存扩大,你的应用可以跑得更快更加节省时间,比如基于 Spark 搭建的应用。
此种场景下,你可以考虑使用持久内存来提供一个大内存低成本的解决方案。
-
优势:
持久内存在单位价格上约为普通内存的一半,并且可以在单台机器上轻松达到 1.5 TB,甚至 3 TB 的内存大小。
因此,比如你目标需要 20 TB 的总内存容量,持久内存可能只需要10台机器即可满足,但是基于DDR内存的集群可能需要40台甚至更多。
考虑机器投入以及运营上带来的成本,持久内存所带来的低成本解决方案的优势是显而易见的。 -
可能的问题:
当然引入持久内存,相比较于内存可能会带来一定的性能衰退,衰退的原因可能是持久内存本身所引起的,也可能是由于机器台数减少,其他硬件资源(比如CPU核数或者网络带宽)减少所引起的。
所以实际项目落地中,作为决策者,一定需要进行谨慎评估,来量化持久内存带来的利害关系。
场景2:高性能持久化需求的应用
-
持久内存作为一个内存和外存的混合体,其高速持久化的特性在某些磁盘 IO 作为性能瓶颈的场景下是一个破局的解法。
-
虽然 SSD 一定程度上也可以缓解磁盘 IO 性能瓶颈,但是相比较于 PMem 这种可以实现两个数量级的吞吐和延迟改进的持久化设备来说,PMem 无疑是具有革命性的意义的。
-
以下抛砖引玉举几个磁盘IO作为性能瓶颈的场景。
(1)消息队列:
大家熟悉的开源消息队列 Kafka,由于其消息持久化逻辑的存在,其吞吐最终会卡在硬盘 IO 上。目前的解法是不断堆机器来扩展整个 Kafka 集群的吞吐。
(2)搜索系统:
类似于 Kafka,流行的开源搜索系统 Elasticsearch,也将部分的数据结构存放在磁盘上。那么最终影响整体延迟和吞吐的将会是磁盘 IO 的性能。
(3)数据库或者KV存储引擎:比如 MySQL 或者 RocksDB,都具有重要的面向外存的数据持久化逻辑。
(4)分布式文件系统:在人工智能场景中,常常会有大量的小文件存在。
比如在 Ceph 的文件系统中,在 metadata server 上对大量小文件的管理常常由于大量随机读写的存在而产生性能问题。 -
优势:
显然,对于有高速持久化读写需求的场景,持久内存引入直接有了数量级的性能提升。
在吞吐方面,由于单机吞吐提升,因此总的机器数量规模可以大量减少,在延迟方面则是提供了另一给维度的优势。
具体性能比对可以参照上一节末尾给出的性能比对表格。 -
可能的问题:
-
PMem 作为纯粹的持久化设备可能是把双刃剑,最主要的问题是其容量相比较于传统硬盘来说还是偏小,同时单位成本也高。
因此对于某些场景下如果除了对于性能,对于容量也有较高的要求,那么使用 PMem 带来性能的提升,但是也可能会造成成本的上升。
场景3:内存数据持久性的应用
-
这种场景下,本质上还是把 PMem 当做一个内存来使用,和上一个高性能持久化的场景有所相似有所区别。
上一个场景主要是针对本来软件架构设计就有持久化逻辑(比如文件系统本来就需要存在硬盘上),然后我们把持久化逻辑搬移到PMem上就可以。其本身可能并不涉及到复杂的数据结构的修改,因为其本来的设计就已经带有了持久化逻辑。 -
但是在场景 3 这种内存数据持久化场景中,软件本身的内存数据结构的设计是没有考虑到持久化逻辑的。因此你需要针对内存中的数据结构重新设计持久化数据结构和逻辑。
这一类应用对开发的要求是最高的,同时也是最能完全发挥 PMem 的特点。 -
此种场景往往是本来就是基于纯内存的应用,但是希望增加数据持久的特性,最常见的需求是因为要快速数据恢复。此种需求一般来自线上服务系统(比如数据库 Redis,或者人工智能场景下的参数服务器、特征工程数据库等),线上服务一旦节点离线,都会造成服务质量的影响。
-
由于系统是基于内存数据结构,离线以后的数据恢复往往需要小时级别的时间来重新抓取数据,并且重新构建内存中的数据结构。
如果有了持久内存,此类服务不仅能够通过大内存降低成本,而且可以增加快速恢复功能,保证线上服务质量。 -
优势:如上所述,此种模式下,可以把持久内存的优势充分发挥出来。
首先大内存带来硬件成本的下降;
其次,通过持久性,赋予了本来的内存应用的新的持久化特性,可以支持数据快速回复,保证线上服务质量。 -
缺点:此种应用唯一的问题可能是带来比较多。
一般的内存数据结构都没有持久化逻辑,一般要求程序员通过 PMDK 重新设计持久化数据结构和逻辑,实现期望中的内存数据持久化。 -
eg:英特尔、第四范式联合研究成果入选国际顶会 VLDB 傲腾™ 持久内存加持 优化万亿维特征在线预估系统,第四范式推出业界首个基于持久内存、支持毫秒级恢复的万亿维线上预估系统
10.持久内存使用模式?
正是因为持久内存具有传统内存的特性,又兼具有外存的持久化特性,造就了其特殊的双模式使用方式。
- 注意,两种模式不能混合使用,并且模式之前切换具有一定成本,无法做到程序运行时动态切换。
内存模式(Memory Mode)
-
顾名思义,就是把持久内存直接当做内存使用,不利用其非易失特性。
这是一种最快速、低成本扩展内存容量的方式,对于程序完全透明。
具体来说,操作系统将会直接看到持久内存的容量,而原来的DRAM将会被隐藏掉(实际上作为了持久内存的一层cache,其cache机制由CPU直接掌控)。
程序无需改动任何代码,可以直接利用持久内存的大内存优势来运行内存消耗大的应用。 -
内存模式问题:
(1)可能的性能问题。
由于DRAM被当做了PMem的一层cache,并且被CPU自动管理,但是PMem其在性能参数上是略低于DRAM的,所以在某些对于cache不友好的情况下,可能会带来性能较大的衰减。
(2)无法使用持久化特性。
内存模式丢失了内存数据持久化的特性,无法用作对数据持久化有要求的场景。
App Direct 模式(AD Mode)
-
AD Mode 实际上是把内存层级完全暴露给了应用。程序员需要自己控制将数据存放在DRAM或者持久内存,自己掌握是否要进行内存数据的持久化操作。
-
因此,其优势正好是克服了内存模式的两个问题:
-
存储层级对程序员可见,因此应用可以根据自己的特点进行存储性能优化,比如冷热数据的分级存储,以及使用缓存敏感的数据结构(cache conscious)
-
数据持久性在AD Mode下可用,程序员可以选择是否将数据在持久内存上做持久化操作,从而达到利用高速持久化能力,或者给程序带来快速恢复的能力
-
但是,AD Mode 带来的问题在于研发成本的提升。
由于持久化编程模型的引入,原来基于内存的程序可能需要重新架构才能在多级存储的内存架构上发挥优势
11.如何做持久内存的开发?
适合场景
- memory mode这种低成本扩展内存容量的方式可以满足你的业务需求
场景改造场景
- 内存模式性能衰退过于明显,希望使用大容量内存的同时,保持和DRAM接近的性能
- 想利用持久内存来替代(或者一部分替代)传统外存设备,利用其高速持久化特性
- 希望对内存数据做持久化,提供离线以后的快速恢复功能
应用程序会有3种模式可以访问傲腾磁盘(插在内存插槽上的傲腾介质):
-
通常我们访问磁盘,都需要走文件系统,内核,驱动程序,最后是磁盘本身的操作,当然,磁盘自身的操作时间(延时)会比较长,前面一些操作的时间基本可以被忽略。
-
随着磁盘越来越快,从传统HDD到SSD到PCI-E SSD再到现在的傲腾技术,我们发现“磁”盘自身操作的延时越来越短,那么相比之下,操作系统内核,驱动,文件系统所带来的开销就不能被忽略了,甚至会成为瓶颈,于是就有了新的持久化内存编程模型出来了。
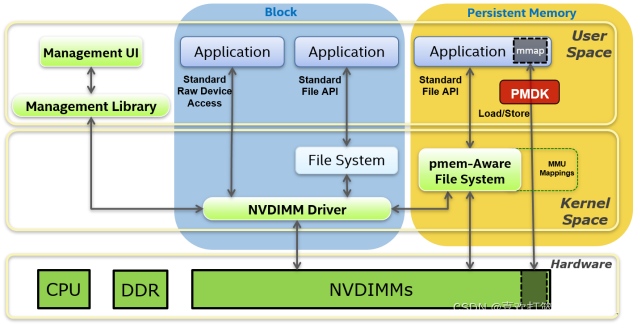
-
方法1:传统的文件系统方式访问文件,把傲腾当成普通的SSD用;
这个访问延迟可能会和访问PCI-E SSD不会有太大差别,毕竟延时都浪费再文件系统,内核,驱动上了,除非其价格和PCI-E SSD可以拼一把,否则这种应用场景通常不会被考虑。 -
方法2:用PM-Aware文件系统(可以持久化)
会跳过文件系统本身的负载(比如文件缓存等);
标准文件API这一块或许不是我们通常理解的标准C/C++/Java API,至少这些API底层需要重写或者有PM-Aware文件系统提供新型API; -
方法3:应用程序直接访问NVDIMM
操作系统内核把它当作内存用,并提供MMU的地址映射关系(可以不持久化);
理论上应用程序可以获得一个更大的内存,和普通的内存使用没有什么太大区别,访问数据时,没有了系统调用,文件系统等多个拖累;
基于PMDK库,Intel仅使用8字节存储确保故障原子性。大于8字节的将不保证数据一致性。
12.持久内存编程
NVDIMM
- NVDIMM是基于NAND Flash的非易失型内存条。
- 它通常被做成“电池+Flash+DRAM”的形式,通电时依然是依靠DRAM工作,断电时才用电池电量将DRAM数据刷回Flash。
应用如何访问持久内存?
- 应用需要特定方法和指定的持久内存连接;
- 持久内存不像易失性内存一样是匿名的,他需要像文件一样命名一个区域;
- 应用需要具有访问持久内存的控制权限;
DAX
- 如上图最右边所示,允许应用程序直接访问持久内存PM,而不经过系统的page cache,这样的特性称为DAX。
- 持久内存编程模型和DAX特性表明持久内存文件可以使用mmap()或MapViewOfFile()类似的标志函数映射到内存。
- 应用直接通过load/store指令访问持久内存。允许直接访问持久媒介而不用进行用户态和内核态的切换。
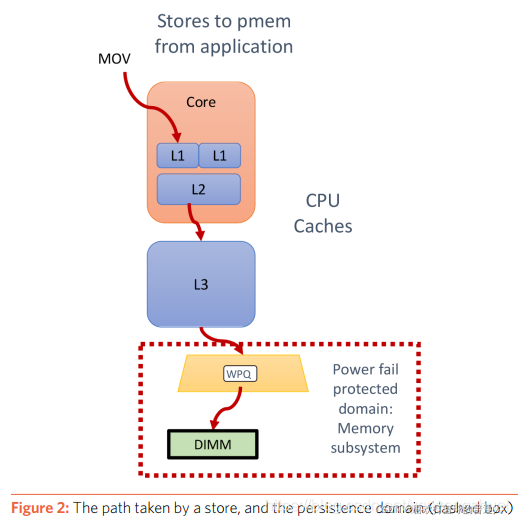
存储持久化
- Linux系统可以使用msync()或fsync()确保数据持久化,这些调用会创建一个内存栅,这个点之前的数据都已经全部持久化到持久内存。
- OS在存储存储栅找到page cache中的脏页,然后将他们刷写到磁盘。
持久内存不使用page cache,操作系统仅需要将CPU cache中的变动刷写到持久内存。
异步DRAM
- 图中虚线部分显示了持久域。这种级别的架构,虚线部分的数据要么在DIMM,要么在内存控制器的写请求队列WPQ。
- 无论哪种返回,持久内存需要有足够的电量将虚线框中的数据刷写到持久媒介。这种特性叫做异步DRAM刷,并NVDIMM已经具备这种特性。
NVM库
- Intel开发的pmdk库,在GitHub上开源,开源协议BSD,使用手册可从http://pmem.io查看。
libpmem:基本库
- 这个库比较小,相对简单,包含探测CPU支持哪种刷写指令以及使用最佳指令进行范围拷贝。
- Libpmem库提供函数告诉应用程序何时Optimized flush是安全的。
(1)强烈建议程序员使用libpmem来确定并使用用户空间刷写。
(2)Libpmem也被用来检测平台使用电池的情况,将刷写调用转换成简单的sfence指令调用。
libpmemobj:
- 支持事务
Libpmemblk和libpmemlog:
- 支持特定用户案例
Libmemkind:
- 持久内存易失性使用
持久内存相关的最重要的开源项目肯定是 Intel 自己家的 Persistent Memory Programming ,其中比较重要的几个repo包括
- 最底层的基础性编程库,覆盖最全的功能,但也是最繁琐的操作方式
- 以C++绑定的PMDK里面最重要的一些概念和基础数据结构,作为入门开发者的首选
- 最为基础的持久内存应用 KV Store,兼具有高性能内存查询和数据持久化能力
13.持久化编程入门资料
入门
-
Intel 举办的 Hackathon 的介绍材料以及若干
-
最重要的持久化编程库 PMDK 里面的 examples
eg:libpmemobj-cpp编写的Pmem的Hello world
14.PM相关程序例子
libmem库
- peme底层库,不支持事务
- eg:以下是目前所有的和持久化相关的函数
#include <libpmem.h>
void pmem_persist(const void *addr, size_t len); // 将对应的区域强制持久化下去,相当于调用msync(),调用该函数不需要考虑align(如果不align,底层会扩大sync范围到align)
int pmem_msync(const void *addr, size_t len); // 相当于调用msync,和pmem_persist功能一致。 Since it calls msync(), this function works on either persistent memory or a memory mapped file on traditional storage. pmem_msync() takes steps to ensure the alignment of addresses and lengths passed to msync() meet the requirements of that system call.
void pmem_flush(const void *addr, size_t len); // 这个的粒度应该是cacheline
void pmem_deep_flush(const void *addr, size_t len); (EXPERIMENTAL) // 不考虑PMEM_NO_FLUSH变量,一定会flushcpu寄存器
int pmem_deep_drain(const void *addr, size_t len); (EXPERIMENTAL)
int pmem_deep_persist(const void *addr, size_t len); (EXPERIMENTAL)
void pmem_drain(void);
int pmem_has_auto_flush(void); (EXPERIMENTAL) // 检测CPU是否支持power failure时自动flush cache
int pmem_has_hw_drain(void);
- 调用pmem_persist相当于调用了sync和drain
void
pmem_persist(const void *addr, size_t len)
{
/* flush the processor caches */
pmem_flush(addr, len);
/* wait for any pmem stores to drain from HW buffers */
pmem_drain();
}
前提是x86-64环境
pmem_flush
- pmem_flush含义是调用clflush将对应的区域flush下去。libpmem会在装载时获取相关信息自动选择最优的flush系指令。
- CLFLUSH会命令cpu将对应cacheline逐出,强制性的写回介质,但是这是一个同步指令,将会阻塞流水线,损失了一定的运行速度。
于是Intel添加了新的指令CLFLUSHOPT和CLWB,这是两个异步的指令。尽管都能写回介质,区别在前者会清空cacheline,后者则会保留,这使得在大部分场景下CLWB可能有更高的性能。 - 一般的pmem_memmove(), pmem_memcpy() and pmem_memset()在下发完成之后都会flush的,除非指定PMEM_F_MEM_NOFLUSH
pmem_drain
- pmem_drain含义是调用sfense等待所有的pipline都下刷到PM完成(等待其他的store指令都完成才会返回)
- 上面flush异步的代价是我们对于cache下刷的顺序依旧不可预测,考虑到有些操作需要顺序保证,于是我们需要使用SFENCE提供保证,SFENCE强制sfence指令前的写操作必须在sfence指令后的写操作前完成。
- 考虑到pmem_drain可能会阻塞一些操作,更好的做法是对数据结构里互不相干的几个字段分别flush,最后一并调用pmem_drain,将阻塞带来的问题降到最低。
libpmemobj
-
libpmem的上层封装,所有对pmem的操作都抽象为obj pool的形式。
(1)pmemobj_create创建obj pool
(2)pmemobj_open打开已经创建的obj
(3)pmemobj_close关闭对应的obj
(4)pmemobj_check对metadata进行校验 -
pmemobj_direct作用
bpmemobj的内存指针是普通指针的两倍大,它说明了该pool是指向哪个obj pool的,和其中的offset;
因此,从这个指针数据结构需要(void *)((uint64_t)pool + oid.off)这样的转换,才能转到实际的地址;
typedef struct pmemoid {
uint64_t pool_uuid_lo; // 具体的某个obj,通过cuckoo hash table的两层哈希对应到实际的地址pool
uint64_t off; // 对应的offset
} PMEMoid; // 我们把它叫做persistent pointer
跟对象 root object
- 根据官方的说法,根对象的作用就是一个访问持久内存对象的入口点,是一个锚的作用。使用如下方式
- pmemobj_root(PMEMobjpool* pop, size_t size):非类型化的原始API。
create或者resize根对象,根据官方文档的描述,当你初次调用这个函数的时候,如果size大于0并且没有根对象存在,则会分配空间并创建一个根对象。当size大于当前根对象的size的时候会进行重分配并resize。 - POBJ_ROOT(PMEMobjpool* pop, TYPE):这是一个宏,传入的TYPE是根对象的类型,并且最后返回值类型是一个void指针
事务支持
- 整个事务的流程可以通过这几个宏以及代码块来定义,并且将事务分成了多个阶段,中间的三个阶段为可选的,最基本的一个事务流程是TX_BEGIN-TX_END,这也是最常用的部分,其他的几个部分在嵌套事务中使用较多。
- 除了基本的事务代码块,libpmemobj还提供了相应的事务操作API。
/* TX_STAGE_NONE */
TX_BEGIN(pop) {
/* TX_STAGE_WORK */
} TX_ONCOMMIT {
/* TX_STAGE_ONCOMMIT */
} TX_ONABORT {
/* TX_STAGE_ONABORT */
} TX_FINALLY {
/* TX_STAGE_FINALLY */
} TX_END
/* TX_STAGE_NONE */
type safety
- libpmemobj使用了一系列macro来将persistent pointer和某个具体类型联系起来

线程安全
- 所有的libpmemobj函数都是线程安全的。
- 除了管理obj pool的函数例如open、close和pmemobj_root,宏里面只有FOREACH的不是线程安全的。
- 我们可以将pthread_mutex_t类放到pm里,叫做pmem-aware lock,下面是一个简单的例子
struct foo {
PMEMmutex lock;
int bar;
};
int fetch_and_add(TOID(struct foo) foo, int val) {
pmemobj_mutex_lock(pop, &D_RW(foo)->lock);
int ret = D_RO(foo)->bar;
D_RW(foo)->bar += val;
pmemobj_mutex_unlock(pop, &D_RW(foo)->lock);
return ret;
}
更多编程参考资料
-
Intel PMem 编程的官方大本营:Persistent Memory Development Kit (PMDK)
-
Programming Persistent Memory – A Comprehensive Guide for Developers 英文原版pdf
-
参考:持久内存(PMem)科普,持久内存编程,持久内存开发资料汇总,持久化内存编程及其思考,清华计算机系舒继武 CCF-ADL 讲习班下篇:持久性内存存储系统的研究与挑战 ,干货:Linux 文件系统与持久性内存介绍,探秘持久内存(PMem)中无锁实现多线程安全的持久化数据结构,Persistent Memory编程简介,持久内存快速编程手册 (Part 6 of 7)

















 4145
4145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









