









前言
写这篇博客的原因是这篇文章被后续很多篇文章所引用,而且其中所用的PMEP(Persistent Memory Emulation Platform),该独特的硬件PM模拟平台采用DRAM模拟非易失的持久内存设备。Subramanya R Dulloor博士做了很多优秀的工作,如本文所讲的PMFS外,还有Xmem等工作。
背景
持久内存(Persistent Memory)
它是容量很大字节的寻址设备作为存储级内存使用;虽然性能差距得到改善,但是PM依然以块设备的方式被访问,这带来了不必要的开销。
PMFS
PMFS实现一个文件系统,它可以不通过块层直接访问PM设备,并且它遵守POSIX接口以便支持传统的应用程序。该轻量级的文件系统以及优化的内存映射I/O无需在DRAM和辅助存储中拷贝数据,从而避免了双倍拷贝开销。
挑战
主要围绕三个挑战开展工作,具体
- 有序性和持久性;
- 保护免受流浪写(stray writes);
- 如何验证以及判断一致性测试的正确性。
本文的贡献点
提出了一个简单的硬件原语为pm_wbarrier,它能够保证写PM的顺序性和持久性;
设计以及实现:
- 一个轻量级的POSIX文件系统;
- 采用细粒度的日志用于一致性保证;
- 通过透明大页支持将PM直接映射给应用程序;
- 通过低开销机制保护PM免受流浪写影响。
PMFS系统架构
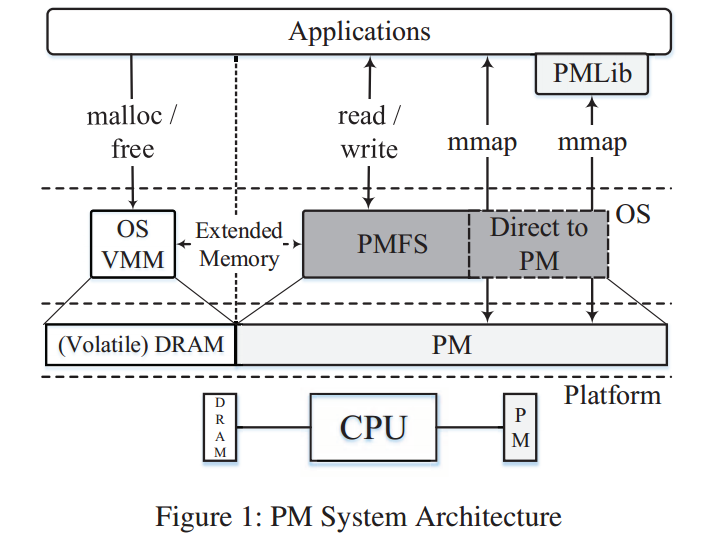
如上图1所示,该OS VMM(Virtual Memory Manager,虚拟内存管理器)继续管理DRAM,而PMFS也负责管理PM。
一致性—-有序性和持久性
保证有序性和持久性的方法如下:
- PM作为写穿设备;
- 绕过CPU高速缓存的PM写;
- 基于Epoch的有序性。
使用PM作为CPU高速缓存的写回设备;
为了到达持久化点,提出了一个新的硬件原语pm_wbarrier。
设计与实现
目标
- 优化字节寻址存储以避免在文件I/O期间拷贝数据到DRAM中;
- 使得应用你程序能够有效访问PM;
- 保护PM免受流浪写影响。
内存映射I/O(Memory-mapped I/O,mmap)
PMFS Layout如下图所示
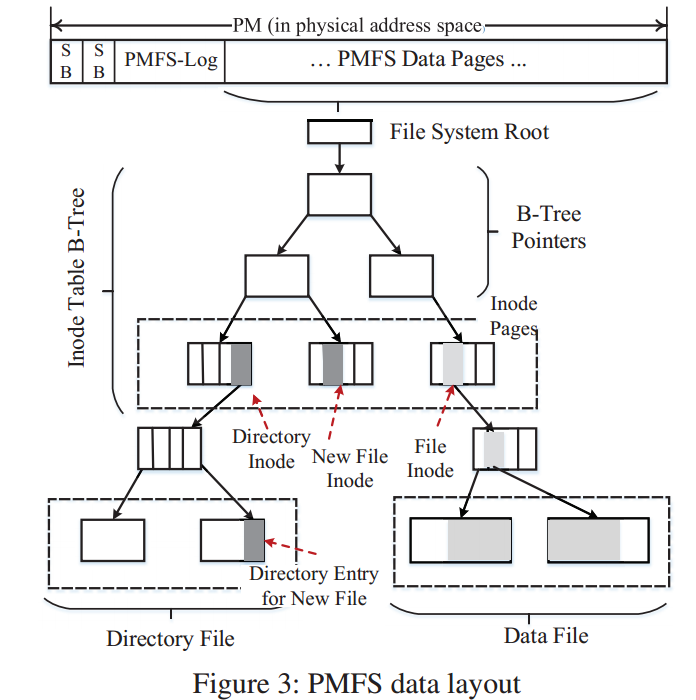
Memor-mapped I/O选择最大的页表。
一致性
- 可能的技术
- 写时复制,journaling,日志结构更新。
- 写时复制(CoW)、日志结构文件系统以块或段大小粒度执行;
- 元数据更新比较小,所以大粒度引起了非常大的写放大。
- Journaling能够以细粒度记录元数据的更新;
- 发现64字节的缓存行粒度对于元数据更新开销最小;
- 使用写时复制技术用于文件数据的更新。
Journaling
重做日志(Redo journaling)
新的数据被记录到日志并持久化。一旦事务提交,该新数据被写入文件系统中。
优点–仅需要2个pm_wbarrier;
缺点是事务期间的读操作需要搜索日志条目。
撤销日志(Undo journaling)
- 将被重写的旧数据被记录到日志中并持久化。该新数据在事务期间被写入到文件系统中。
- 优点是简单并且细粒度成为可能;
- 缺点是每个日志条目需要一个pm_wbarrier硬件原语,增加了开销。
原子的原地更新
无需日志技术直接地更新元数据;
PMFS利用处理器特征实现8,16,64字节原子更新
- 8字节-用于文件读更新索引节点的访问时间;
- 16字节-用于文件追加操作时更新索引节点大小以及修改时间;
- 64字节-用于修改索引节点的许多域如删除一个索引节点操作。
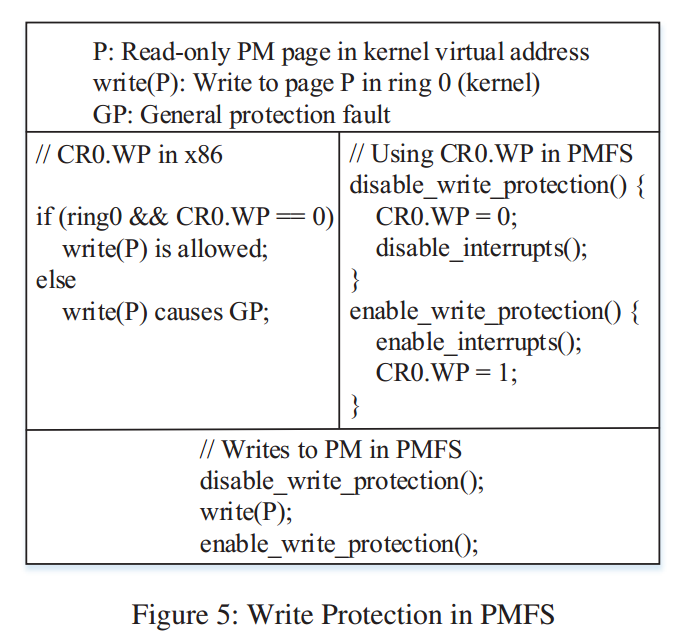
写保护
Corruption会发生由于不相关软件的bugs(流浪写);
写保护如何工作?
- 行名指的是地址空间;
- 列名指的是优先级。
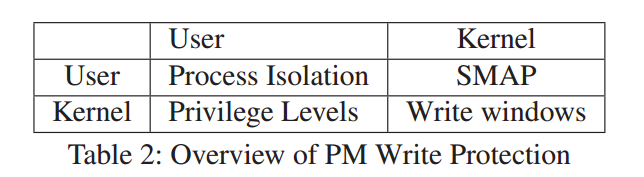
通过优先级(Privilege levels)保护“Kernel from user“;
通过分页(Paging)来保护”user from user“;
通过SMAP(Supervisor Mode Access Prevention)来保护”user from kernel“
- 以监管模式(内核级或ring 0)访问用户地址空间是禁止的。
通过写窗口(Write windows)来保护”kernel from kernel“
- 在文件系统挂载期间将整个PM设备映射为只读;
- 仅对写PM的部分代码时将PM升级为可写的;
测试以及验证
- 维持一致性是一个挑战;
- PM软件需要记录脏的高速缓存行(Dirty cachelines),以便在发送pm_wbarrier硬件原语前明确地刷新脏cachelines。
- 相同的问题使用于任何的PM软件;
- 为了解决这个问题构建了Yat,它是用于帮助验证PM的框架。
- Yat操作有两个阶段:
(1)记录一个有关所有的写、clflush、有序的、pm_wbarrier的轨迹(trace);
(2)重新执行该搜集的trace并且测试所有的子集和顺序性。
性能评估
实验设置
PM模拟
- 对PM软件的系统级评估是具有挑战性的,原因是缺乏真实的硬件。
- 构建了PMEP(PM模拟平台)。
- 将可用的DRAM内存划分为模拟的PM和常规的易失性内存DRAM。
- 模拟PM延迟;
- 模拟PM带宽。
PMBD
- 为了和块设备公平比较而采用PMBD(Persistent Memory Block Driver)。
基于文件的I/O
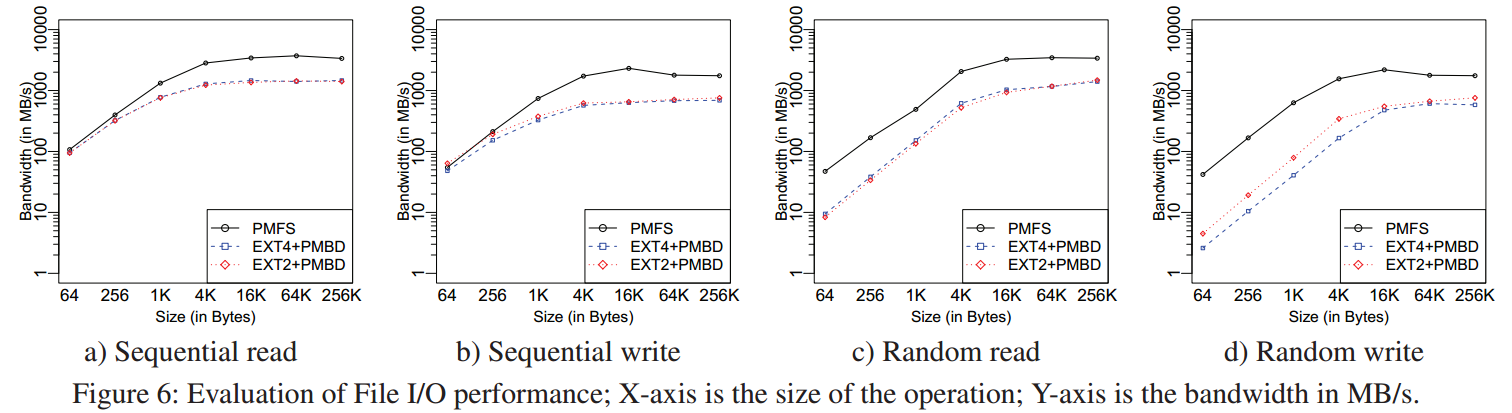
- 对于所有的测试,性能提升范围从1.1倍(对于64B顺序读)到16倍(对于64B随机写)。
- 对于尺寸大于16KB的写下降原因是使用了非时间性的(non-temporal)指令。这些指令绕过高速缓存(bypass the cache)但是依旧导致了高速缓存一致性开销。
一致性
原子的原地更新以避免日志(logging)
- 写系统调用使用16字节的原子更新,速度提升1.8倍;
- 使用64字节的原子更新来删除一个索引节点,速度可提升18%。
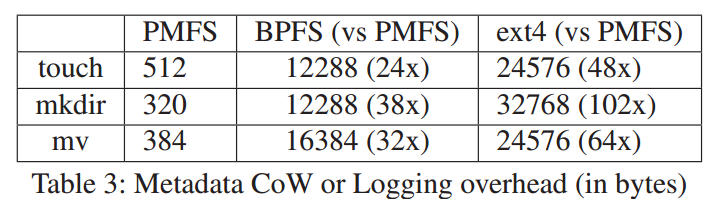
日志开销-得益于细粒度日志(fine-grained logging) - 对于PMFS和ext4而言,测量元数据日志的总量;
- 对于BPFS而言,测试使用写时复制的元数据拷贝的总量。
内存映射I/O
Neo4j图数据库 - 默认,Neo4j通过mmap访问文件;
- 该图有1000万个节点,1亿条边;
- 与ext2,ext4进行比较,提升1.1倍(插入)到2.4倍(查询)。
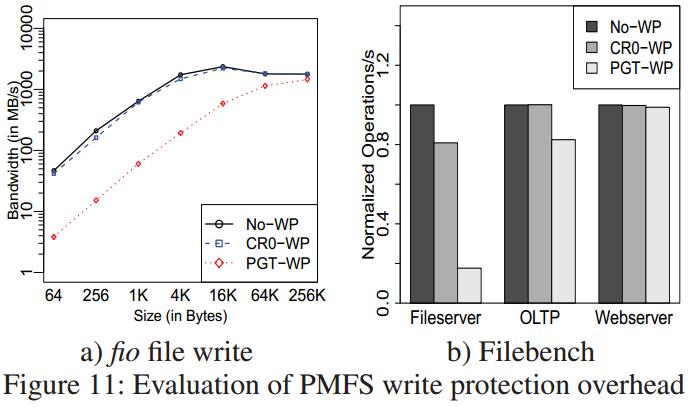
写保护
- PMFS采用CR0-WP与No-WP,PGT-WP(page table permission)进行对比;
- 文件服务器–工作负载有来自于许多进程的写(慢23%);
- OLTP–一个单日志线程;
- Webserver–少写密集型工作负载;
总结
传统的基于磁盘的文件系统存在双份拷贝开销,即一是从块设备(block device)到页高速缓存(page cache),二是从页高速缓存到用户缓冲(user buffer)。而PMFS消除了传统的双份拷贝开销,直接采用文件系统到用户缓冲的数据通路。本文提出的用于优化的持久内存PM的系统软件,通过实现PMFS对于传统的应用而言提升高达一个数量级,并且可使应用程序直接访问PM。然而,一个内存映射接口对于许多应用程序而言太过底层,所以基于PMFS内存映射接口的用户级库和编程模型能够提供更简单的抽象。
最后唠叨一下:Journaling的缺点是写两遍,一个到Journal,一个到文件系统。对于redo journaling而言,只有当事务成功提交后新数据才能够写入到文件系统中,而对于undo journaling而言,新数据的写入发生在事务开始到提交之间某个时间段,只有新数据写入到目标地址才能提交事务。mmap能够将文件数据直接映射到应用程序虚拟地址空间中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









